Categories
Archives
Defining the boundary between authentic news and synthetic content has never been more critical. In 2025, IPTC didn’t just participate in that conversation—we led it.
Through a record year of new memberships and global events spanning from Juan-les-Pins to New York, we connected thousands of professionals to the future of media technology. Whether through new AI opt-out mechanisms or robust provenance tools, our work is now empowering hundreds of the world’s leading organisations to face the challenges of tomorrow.
Here is a look at the milestones, events, and releases that defined our work in 2025.
Global Connections: A Year of Events
This year, we prioritised bringing the media community together to solve shared challenges. From exclusive member gatherings to public conferences, we held events around the world – and plan to be even more international in 2026. Our events included:
- Member Meetings: We kicked off the year with our Spring Meeting in Juan-les-Pins, France, held alongside CEPIC. It was a vital opportunity to bring IPTC members together and align with the licensed photography world. Later in the year, our Autumn Meeting was held online, allowing our global membership to convene efficiently to discuss strategy and standards updates.
- Media Provenance Series: Trust was a central theme of 2025. We partnered with leading organisations to host a series of high-impact events focused on Media Provenance:
- Paris: Held at the AFP offices, IPTC participated in this event that was organised by AFP along with the BBC and Media Cluster Norway.
- New York: The Content Authenticity Summit was held at the Cornell University campus. IPTC co-hosted the event in association with the Content Authenticity Initiative (CAI) and C2PA.
- Bergen, Norway: A landmark event held in association with Media Cluster Norway, the BBC, and the EBU.
- Photo Metadata Conference: Our annual conference remains a must-attend event for the industry, this year attracting more than 200 attendees to hear from industry legends such as Tim Bray on the technical evolution of visual media.
Critical Guidelines for the AI Era
As Generative AI continues to reshape the landscape, the IPTC provided the industry with the necessary guidance to adapt.
- AI Opt-Out: We published comprehensive guidelines allowing content owners to express their machine learning and data mining preferences, ensuring publishers retain control over how their content is ingested by AI crawlers.
- Implementing C2PA: While the demand for provenance is high, the technical path can be complex. We released specific guidelines on implementing C2PA for news publishers, helping newsrooms bridge the gap between technical specification and practical workflow application.
Powering the Industry: Standards and Tools
We continued to maintain and evolve the technical backbone of the news industry. 2025 saw significant updates across our portfolio to ensure our standards remain modern and accessible.
New Standard Versions We published updated versions of our core standards, including NewsML-G2, IPTC Video Metadata Hub, IPTC Photo Metadata Standard, and ninjs (News in JSON). We also made many updates to the IPTC NewsCodes controlled vocabularies, ensuring that our taxonomies keep pace with a rapidly changing world.
Open Source Tooling To lower the barrier to entry for developers, we expanded our open-source offerings. This year we released a new Python module for NewsML-G2 and a WordPress plugin for C2PA, making it easier than ever for CMS developers and newsrooms to implement IPTC standards directly.
Online Tools Tools such as the Simple Rights Service make it easier than ever for rightsholders to express complex rights statements in the form of simple URLs. And of course our Origin Verify Validator allows anyone to inspect content signed with C2PA metadata, including all of the metadata fields recommended by IPTC and showing when the publisher that signed the content is on the Origin Verified News Publishers List.
Be Part of the Future
As we look toward 2026, the intersection of AI, provenance, and metadata will only become more critical.
If you want to be part of the conversation rather than just following it, we invite you to join us. By becoming an IPTC member, you can contribute to the standards that run the global news ecosystem and network with the technical leaders of the world’s biggest media organisations.
Become a Member of IPTC and help us build the future of media standards
We would like to thank our members, Working Group leads, volunteers and invited experts for their contributions to IPTC’s vital work this year. We look forward to many more years of defining and influencing technology standards for the media and beyond.
2024 has flown by, but it was a great year for IPTC.
The highlight was definitely the creation of the IPTC’s first new Committee in many years – the Media Provenance Committee, with its working groups for Advocacy and Education, Best Practices and Implementation, and Governance.
Thanks to our Committee Chair Bruce MacCormack (and previous Chair Judy Parnall), and Working Group leads Helge O. Svela, Laura Ellis and Charlie Halford for all their hard work.
With the Committee we launched the Origin Verified News Publisher List this year, with demos and events at IBC in September and NAB New York in October.
The Media Provenance Summit held in the UK in October drew over 70 representatives from news organisations from Africa to Iceland to understand what we are doing in the area of C2PA and media provenance. Thanks to the BBC and Media Cluster Norway for organising the event.
The Committee’s latest milestone is the updating of its governance guidelines to make it easier for Verified News Publishers to obtain certificates. More information will be announced very soon.
Our other Working Groups under the Standards Committee have not been idle – this year has seen new versions of NewsML-G2, ninjs 3.0, Photo Metadata 2024.1, several updates to our NewsCodes vocabularies, including updates to the widely-used Digital Source Type vocabulary, and a forthcoming update to Sport Schema.
Our standards are being used by many of the biggest organisations in the world. Google uses IPTC metadata for AI transparency (among other things). Axel Springer spoke at our Autumn Meeting about how they use Video Metadata Hub to manage their Video On Demand system. AFP and Kairntech talked about how they auto-classify content using Media Topics. And many more of course!
We published advice on using IPTC Photo Metadata for AI-generated images as part of an update to the Photo Metadata User Guide – both to mark their creation and to declare the owner’s intent on whether the image should be used as part of a training data set.
Our partnerships have never been stronger. We signed new liaison agreements with CIPA, EIDR and Global Media Registry. Our latest collaboration with DPP was the Live Production Exchange project, based on IPTC’s ninjs 3.0 standard.
We submitted position papers to the IETF workshop on AI Control and to the EU’s consultation on the AI Act, making the case for respecting embedded metadata in determining whether media files can be used as training data for AI engines.
We had many new members join: Google, Finnish Broadcasting Company Yle, HAND (Human & Digital), China Association of Press Technicians, Kairntech, DW (Deutsche Welle), Factiverse, Media Cluster Norway, RNZ, John Simmons. European Broadcasting Union (upgraded to Voting Membership), and Trufo. We’re very happy to have you all onboard!
We had two amazing member meetings: one physical meeting in New York (thanks to The New York Times and The Associated Press for hosting us) and one virtual meeting in the Autumn. Our attendees especially loved the guided tours of the NYT and AP archives. We’re already planning the next Spring Meeting which will be held in Juan-les-Pins, France in May 2025.
The IPTC Photo Metadata Conference in May saw Adobe, Camera Bits, Foto Forensics, Numbers Protocol and others present many aspects of photo metadata to celebrate 20 years of the IPTC Photo Metadata Standard.
We gave presentations about IPTC standards in the Netherlands, UK, Brazil, USA and France – and probably other places too!
Here’s to achieving even bigger things in 2025!
Thanks for all your help and support.

As we wrap up 2023, we thought it would be useful to give an update you on the IPTC’s work in 2023, including updates to most of our standards.
Two successful member meetings, one in person!
This year we finally held our first IPTC Member meeting in person since 2019, in Tallinn Estonia. We had around 30 people attend in person and 50 attended online from over 40 organisations. Presentations and discussions ranged from the e-Estonia digital citizen experience to building re-usable news content widgets with Web Components, and of course included generative AI, credibility and fact checking, and more. Here’s our report on the IPTC 2023 Spring Meeting.
For our Autumn Meeting we went back to an online format, with over 50 attendees, and more watching the recordings afterwards (which are available to all members). Along with discussions of generative AI and content licensing at this year’s meetings, it was great to hear the real-world implementation experience of the ASBU Cloud project from the Arab States Broadcasting Union. The system was created by IPTC members Broadcast Solutions, based on NewsML-G2. The DPP Live Production Exchange, led by new members Arqiva, will be another real-world implementation coming soon. We heard about the project’s first steps at the Autumn Meeting.
Also at this years Autumn Meeting we also heard from Will Kreth of the HAND Identity platform and saw a demo of IPTC Sport Schema from IPTC member Progress Software (previously MarkLogic). More on IPTC Sport Schema below! All news from the Autumn Meeting is summed up in our post AI, Video in the cloud, new standards and more: IPTC Autumn Meeting 2023
We’re very happy to say that the IPTC Spring Meeting 2024 will be held in New York from April 15 – 17. All IPTC member delegates are welcome to attend the meeting at no cost. If you are not a member but would like to present your work at the meeting, please get in touch using our Contact Us form.
IPTC Photo Metadata Conference, 7 May 2024: save the date!
Due to several issues, we were not able to run a Photo Metadata Conference in 2023, but we will be back with an online Photo Metadata Conference on 7th May 2024. Please mark the date in your calendar!
As usual, the event will be free and open for anyone to attend.
If you would like to present to the people most interested in photo metadata from around the world, please let us know!
Presentations at other conferences and work with other organisations
IPTC was represented at the CEPIC Congress in France, the EBU DataTech Seminar in Geneva, Sports Video Group Content Management Forum in New York and the DMLA’s International Digital Media Licensing Conference in San Francisco.
We also worked with CIPA, the organisation behind the Exif photo metadata standard, on aligning Exif with IPTC Photo Metadata, and supported them in their work towards Exif 3.0 which was announced in June.
The IPTC will be advising the TEMS project which is an EU-funded initiative to build a “media data space” for Europe, and possibly beyond: IPTC working with alliance to build a European Media Data Space.
IPTC’s work on Generative AI and media
Of course the big topic for media in 2023 has been Generative AI. We have been looking at this topic for several years, since it was known as “synthetic media” and back in 2022 we created a taxonomy of “digital source types” that can be used to describe various forms of machine-generated and machine-assisted content creation. This was a joint effort across our NewsCodes, Video Metadata and Photo Metadata Working Groups.

It turns out that this was very useful, and the IPTC Digital Source Type taxonomy has been adopted by Google, Midjourney, C2PA and others as a way to describe content. Here are some of our news posts from 2023 on this topic:
- IPTC publishes metadata guidance for AI-generated “synthetic media”
- Google announces use of IPTC metadata for generative AI images
- Midjourney and Shutterstock AI sign up to use of IPTC Digital Source Type to signal generated AI content
- Microsoft announces signalling of generative AI content using IPTC and C2PA metadata
- Royal Society/BBC workshop on Generative AI and content provenance
- New “digital source type” term added to support inpainting and outpainting in Generative AI
- IPTC releases technical guidance for creating and editing metadata, including DigitalSourceType
IPTC’s work on Trust and Credibility

After a lot of drafting work over several years, we released the Guidelines for Expressing Trust and Credibility signals in IPTC standards that shows how to embed trust infiormation in the form of “trust indicators” such as those from The Trust Project into content marked up using IPTC standards such as NewsML-G2 and ninjs. The guideline also discusses how media can be signed using C2PA specification.
We continue to work with C2PA on the underlying specification allowing signed metadata to be added to media content so that it becomes “tamper-evident”. However C2PA specification in its current form does not prescribe where the certificates used for signing should come from. To that end, we have been working with Microsoft, BBC, CBC / Radio Canada and The New York Times on the Steering Committee of Project Origin to create a trust ecosystem for the media industry. Stay tuned for more developments from Project Origin during 2024.
IPTC’s newest standard: IPTC Sport Schema
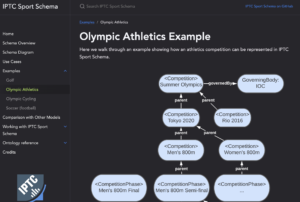
After years of work, the IPTC Sports Content Working Group released version 1.0 of IPTC Sport Schema. IPTC Sport Schema takes the experience of IPTC’s 10+ years of maintaining the XML-based SportsML standard and applies it to the world of the semantic web, knowledge graphs and linked data.
Paul Kelly, Lead of the IPTC Sports Content Working Group, presented IPTC Sport Schema to the world’s top sports media technologists: IPTC Sport Schema launched at Sports Video Group Content Management Forum.
Take a look at out dedicated site https://sportschema.org/ to see how it works, look at some demonstration data and try out a query engine to explore the data.
If you’re interested in using IPTC Sport Schema as the basis for sports data at your organisation, please let us know. We would be very happy to help you to get started.
Standard and Working Group updates
- Our IPTC NewsCodes vocabularies had two big updates, the NewsCodes 2023-Q1 update and the NewsCodes Q3 2023 update. For our main subject taxonomy Media Topics, over the year we added 12 new concepts, retired 73 under-used terms, and modified 158 terms to make their labels and/or descriptions easier to understand. We also added or updated vocabularies such as Digital Source Type and Authority Status.
- The News in JSON Working Group released ninjs 2.1 and ninjs 1.5 in parallel, so that people who cannot move from the 1.x schema can still get the benefits of new additions. The group is currently working on adding events and planning items to ninjs based on requirements the DPP Live Production Exchange project: expect to see something released in 2024.
- NewsML-G2 2.32 and NewsML-G2 v2.33 were released this year, including support for Generative AI via the Digital Source Type vocabulary.
- The IPTC Photo Metadata Standard 2023.1 allows rightsholders to express whether or not they are willing to allow their content to be indexed by search engines and data mining crawlers, and whether the content can be used as training data for Generative AI. This work was done in partnership with the PLUS Coalition. We also updated the IPTC Photo Metadata Mapping Guidelines to accommodate Exif 3.0.
- Through discussions and workshops at our Member Meetings in 2022 and 2023, we have been working on making RightsML easier to use and easier to understand. Stay tuned for more news on RightsML in 2024.
- Video Metadata Hub 1.5 adds the same properties to allow content to be excluded from generative AI training data sets. We have also updated the Video Metadata Hub Generator tool to generate C2PA-compliant metadata “assertions”.
New faces at IPTC
Ian Young of Alamy / PA Media Group stepped up to become the lead of the News in JSON Working Group, taking over from Johan Lindgren of TT who is winding down his duties but still contributes to the group.
We welcomed Bonnier News, Newsbridge, Arqiva, the Australian Broadcasting Corporation and Neuwo.ai as new IPTC members, plus a very well known name who will be joining at the start of 2024. We’re very happy to have you all as members!
We are always happy to work with more organisations in the media and related industries. If you would like to talk to us about joining IPTC, please complete our membership enquiry form.
Here’s to a great 2024!
Thanks to everyone who gave IPTC your support, and we look forward to working with you in the coming year.
If you have any questions or comments (and especially if you would like to speak at one of our events in 2024!), you can contact us via our contact form.
Best wishes,
Brendan Quinn
Managing Director, IPTC
and the IPTC Board of Directors: Dave Compton (LSE Group), Heather Edwards (The Associated Press), Paul Harman (Bloomberg LP), Gerald Innerwinkler (APA), Philippe Mougin (Agence France-Presse), Jennifer Parrucci (The New York Times), Robert Schmidt-Nia of DATAGROUP (Chair of the Board), Guowei Wu (Xinhua)

Here is a wrap-up of IPTC has been up to in 2022, covering our latest work, including updates to most of our key standards.
Two successful member meetings and five member webinars
This year we again held our member meetings online, in May and October. We had over 70 registered attendees each time, from over 40 organisations, which is well over half of our member organisations so it shows that the virtual format works well.
This year we had guests from United Robots, Kairntech, EDRLab, Axate, HAND Identity, RealityDefender.ai, synthetic media consultant Henrik de Gyor and metaverse expert Toby Allen, as well as member presentations from The New York Times, Agence France-Presse, Refinitiv (an LSE Group company), DATAGROUP Consulting, TT Sweden, iMatrics and more. And that’s not even counting our regular Working Group presentations! So we had a very busy three days in May and October.
We also had some very interesting members-only webinars including a deep dive into ninjs 2.0, JournalList and the trust.txt protocol, a joint webinar with the EBU on how Wikidata and IPTC Media Topics can be used together, and a great behind the scenes question-and-answer session with a product manager from Wikidata itself.
Recordings of all presentations and webinars are available to IPTC members in the Members-Only Zone.
A fascinating Photo Metadata Conference
This year’s IPTC Photo Metadata Conference was held online in November and we had over 150 registrants and 19 speakers from Microsoft, CBC Radio Canada, BBC, Adobe, Content Authenticity Initiative, the Smithsonian and more. The general theme was bringing the IPTC Photo Metadata Standard to the real world, focussing on adoption of the recently-introduced accessibility properties, looking at adoption and interoperability between different software tools, including a new comparison tool that we have introduced; use of C2PA and Content Authenticity in newsroom workflows, with demos from the BBC and CBC (with Microsoft Azure).
We also had an interesting session discussing the future of AI-generated images and how metadata could help to identify which images are synthetic, the directions and algorithms used to create them, and whether or not the models were trained on copyrighted images.
Recordings of all sessions are available online.
Presentations at other conferences, work with other organisations
IPTC was represented at the CEPIC Congress in Spain, the DigiTIPS conference run by imaging.org, the Sports Video Group’s content management group, and several Project Origin events.
Our work with C2PA is progressing well. As of version 1.2 of the C2PA Specification, assertions can now include any property from IPTC Photo Metadata Standard and/or IPTC Video Metadata Hub. C2PA support is growing in tools and is now available in Adobe Photoshop.
IPTC is also working with Project Origin on enabling C2PA in the news industry.
We had an IPTC member meet-up at the NAB Show in Las Vegas in May.
We also meet regularly with Google, schema.org, CIPA (the camera-makers behind the Exif standard), ISO, CEPIC and more.
Standard and Working Group updates
- Our IPTC NewsCodes vocabularies had regular updates each quarter, including 12 new terms at least 20 retired terms. See the details in our news posts about the September Update, July Update, May Update, and the February Update (in time for the Winter Olympics). We also extended the Digital Source Type vocabulary specifically to address “synthetic media” or AI-generated content.
- The News in JSON Working Group released ninjs 1.4, a parallel release for those who can’t upgrade to ninjs 2.0 which was released in 2021. We published a case study showing how Alamy uses ninjs 2.0 for its content API.
- NewsML-G2 v2.31 includes support for financial instruments without the need to attach them to organisations.
- Photo Metadata Standard 2022.1 includes a Contributor structure aligned with Video Metadata Hub which can handle people who worked on a photograph but did not press the shutter, such as make-up artists, stylists or set designers;
- The Sports Content Working Group is working on the IPTC Sport Schema, which is pre-release but we are showing it to various stakeholders before a wider release for feedback. If you are interested, please let me know!
- Video Metadata Hub 1.4 includes new properties for accessibility, content warnings, AI-generated content, and clarifies the meanings of many other properties.
New faces at IPTC
We waved farewell to Johan Lindgren of TT as a Board Member, after five years of service. Thankfully Johan is staying on as Lead of the News in JSON Working Group.
We welcomed long-time member Heather Edwards of The Associated Press as our newest board member.
We welcomed Activo, Data Language, Denise Kremer, MarkLogic, Truefy, Broadcast Solutions and Access Intelligence as new IPTC members, plus Swedish publisher Bonnier News who are joining at the start of 2023. We’re very happy to have you all as members!
If you are interested in joining, please fill out our membership enquiry form.
Web site updates
We launched a new, comprehensive navigation bar on this website, making it easier to find our most important content.
We have also just launched a new section highlighting the “themes” that IPTC is watching across all of our Working Groups:
We would love to hear what you think about the new sections, which hopefully bring the site to life.
Best wishes to all for a successful 2023!
Thanks to everyone who has supported IPTC this year, whether as members, speakers at our events, contributors to our standards development or software vendors implementing our standards. Thanks for all your support, and we look forward to working with you more in the coming year.
If you have any questions or comments, you can contact me directly at mdirector@iptc.org.
Best wishes,
Brendan Quinn
Managing Director, IPTC
Welcome to 2022! We thought a good way to kick off the new year would be to share the text of the speech given by our new Standards Committee Chair, Paul Harman of Bloomberg, at the IPTC Standards Committee meeting on 20 October 2021. In this piece, Paul does a particularly good job of explaining IPTC’s mission and calls on all IPTC members to participate in our standards work.
The IPTC was founded to secure fair access to modern telecommunications infrastructure. Using satellite technology would enable news providers and distributors to report from conflict zones, or from the other side of the world, at greater speed and with less risk of disruption from regional disputes or actions which could affect landline alternatives.
Once such access was secured, they had to decide how to use it. News agencies required technical standards for information interchange, and that’s what IPTC set out to provide, in the name of interoperability. It’s a remit we continue to carry out today. Organisations both inside the news technology arena, and outside, look to IPTC for guidance on media metadata; IPTC is perhaps best known for the Photo Metadata standards that were incorporated into Adobe products, and from there across the photo ecosystem.
Today we face a different problem: not a lack of standards, but an over-abundance of them; and alongside that, regular misuse – or lack of use – of the standards we actually have. As the popular XKCD comic highlights, the solution isn’t to create “one new standard to rule them all”, as this just perpetuates the problem. Increasingly the activities of our Working Groups are about documenting how to use the standards – IPTC and external – that already exist, and how to map between them.

To do this, we need an understanding of what news is, and what each step in the workflow is trying to achieve. We must step away from the bits and bytes of transfer protocols, and instead examine the semantics of news – define an abstract data model representing the concepts in news collection, curation, distribution and feedback, and how those concepts inter-relate – separating the meaning of the metadata from the mechanics of how they are expressed. Only then can we successfully reflect that understanding back into whatever formats our members can use based on the constraints they are operating within.
New protocols and representations evolve all the time: SGML, XML, JSON, YAML, Turtle, Avro, protobuf… they are just serialisation formats. It shouldn’t have to matter whether you choose schema.org or rNews or RDFa or microdata or JSON-LD to embed metadata into HTML; what matters is a consistency of meaning, regardless of the mechanism.
Our Working Groups are already doing this, to a greater or lesser extent. The Video Metadata Hub is precisely an abstract model that defines serialisations into existing formats. The Photo Metadata Standard grew out of IIM and XMP work and describes the serialisations into, and necessary synchronisations between, current and future photo metadata standards. The News in JSON Working Group is attempting to map the same data model across JSON, Avro and Protocol Buffers, based on the News Architecture which was conceived as a data model but quickly became defined via its expression in XML, namely NewsML-G2. The Sports Content Working Group is currently working on taking the semantics from SportsML and SportsJS and re-expressing them in terms of RDF. For machine-readable rights, IPTC worked with the W3C on ODRL and used it as the basis for RightsML. And the NewsCodes Working Group is taking the Media Topics scheme and mapping it to Wikidata, which could be used as a lingua franca between any classification systems.
But this work is far from trivial, and requires continuous effort. IPTC is a member organisation, and it is through the time volunteered by delegates and their organisations that the work progresses. IPTC has but one member of staff – Brendan – who does a huge amount of work across all of our standards, but he also needs to run the business. Therefore we need your help to create and maintain our standards for the benefit of your businesses. Please join the working group sessions, or recommend somebody from your organisation to get involved, in the areas of interest to you and your organisation.
In particular, we have heard again at this meeting the need for machine-readable rights. The standard exists, in the form of RightsML. What it needs now is tooling to support the standard, a user guide with use cases, and potentially some how-tos or templates for typical use cases – similar maybe to Creative Commons licences – that cover the majority of our use cases. Most meetings, we hear from members on how crucial machine-readable rights are to effective workflows in their business, but the Working Group is currently without a lead. If you work at a member organisation who would benefit, please consider volunteering to participate in this group.
I would remind the Working Groups that IPTC has provision in the budget for technical authoring and software development – so I would encourage you to propose to the Board how you might use that. We can then decide where to spend, and also use this as input on future budgets. Let the Board know how we can help and support you.
I’d like to close by thanking the Working Group Leads, and their organisations, for so generously giving of their time: Dave, Jennifer, Johan, Paul, Michael and Pam. Special thanks to David Riecks for agreeing to co-chair the Photo Metadata group, and to Brendan for his support and development work on tools such as the Generators and Unit Testing frameworks. Thanks also to Kelvin Holland, our technical author, for his work on the NewsML-G2 Specification and User Guide. And thanks to the members of all of the working groups for their efforts on our standards which play such a crucial role in the newstech industry.
Thank you.
Paul Harman
Chair, IPTC Standards Committee
20 October 2021
We have made it to the end of 2020. And what a year it has been!

The news and media industry has perhaps been affected less than the travel or hospitality industry, but 2020 was still a hugely eventful year for us all professionally and personally. Congratulations on getting through it, and our thoughts go out to those who have suffered in any way this year.
IPTC Events
Of course our member meetings, planned for Tallinn Estonia and New York USA this year, quickly became virtual events held via Zoom. It worked surprisingly well, and even allowed us to bring on some speakers and guests who wouldn’t have been able to attend or present if we had held the events physically.
You can look back at our Spring Meeting blog posts (Day 1, Day 2, Day 3) and the summary of our Autumn Meeting.
The IPTC Photo Metadata Conference was very interesting this year: from our usual small room hosted as part of the CEPIC Congress, we went to a virtual event with over 200 attendees. If you missed it, or want to re-visit, videos of the sessions are available on YouTube.
Standards work
The News in JSON Working Group submitted ninjs 1.3 for approval at the Spring Meeting, which added fields for trust indicators and genres, support for different types of headlines and alternative IDs. The ninjs generator, showing how easy it is to create a ninjs document by filling in a web form, was very popular and was the inspiration for some related tools in other working groups. Since then, the working group has been looking at more features to be included in future versions of ninjs. If you handle news in JSON in any way and you haven’t completed our News in JSON survey, please do it now!
The NewsML-G2 Working Group released NewsML-G2 2.29 in July which added some fields required for the trust and credibility project, and a new NewsML-G2 Generator tool based on the ninjs one. The group also participated in the trust and credibility projects described below. The NewsML-G2 specifications and guidelines documents have now been updated to version 2.29.
The Video Metadata Working Group released Video Metadata Hub 1.3 during the summer, which added fields to track the editing of metadata (as opposed to editing the actual video), parent video identifier, and updated the mappings to EBUCore and EIDR. The group is hard at work on promoting Video Metadata Hub and creating more introductory materials to help new users understand VMHub and why it is useful.
The NewsCodes Working Group published three updates this year, in March, June and August, and a new update will be published very soon. The NewsCodes Guidelines document was released this year, and is already proving useful both for those wishing to learn how to use NewsCodes better and for the Working Group to establish clear guidelines about when and how to add new terms. MediaTopics is now available in 11 languages and we have more translations coming!
The Photo Metadata Working Group has been very busy, with the biggest news of the year being that Google now supports IPTC Photo Metadata to display licensor information in search results, including a link back to the image owner’s “licence this image” page. The feature was launched in beta in February and launched fully in August. We have had great take-up so far, and the interest in the Photo Metadata Conference (with over 200 people registered) showed that the industry was very keen to hear about it. We also launched updates to the GetPMD tool to support new schema.org mappings, and browser plugins for Chrome and Firefox to enable easy viewing of embedded IPTC Photo Metadata in photographs on the web.
The Sports Content Working Group has had its collective head down in 2020, re-thinking the data model for sports results, statistics and performances. We have been taking a semantic view, looking at using RDF as the main data model for sports data which can then be serialised into JSON, XML and other formats. The intention is that this will also bring the model closer to schema.org in the future. We have some RDF and semantic web experts on the group who are helping with the modelling, and are taking a use-case based approach to make sure that we’re designing something that’s both useful and usable.
A discussion group “spun out” from the NewsCodes Working Group to consider Named Entities for News. So far we have had a couple of meetings to discuss our thoughts on maintaining vocabularies for named entities such as people, companies and places, and to study different approaches used by IPTC member organisations and non-members.
An ongoing project that spans several working groups is the work on Trust and Credibility. After publishing a draft guidelines document in April and a webinar that we ran in September, we plan to publish a 1.0 version in the new year.
All of our Working Groups are always looking for new participants, so if you’re interested in any of these areas, please consider joining IPTC and taking part in a working group!
IPTC appearances at conferences and in the media
There weren’t many conferences in the first part of the year as everyone adjusted to working remotely, but in the second half of the year IPTC people made quite a few appearances at other conferences and webinars.
In July, Brendan Quinn and Robert Schmidt-Nia spoke about NewsML-G2 at an Arab States Broadcasting Union metadata workshop. In September, Michael Steidl spoke on a panel with Google and Alamy at the Perpignan photojournalism conference about Google’s “Licensable Images” feature, and Brendan Quinn hosted a webinar about our work in trust and credibility.
In October, Pam Fisher and Mark Milstein spoke about Video Metadata Hub at the DMLA conference. In November, Brendan Quinn was invited to give a keynote at the FIBEP World Media Intelligence Congress, speaking to the media monitoring / media intelligence industry who also use quite a few IPTC standards.
Also in November, Bill Kasdorf published a column in Publisher’s Weekly about Media Topics and IPTC Photo Metadata which raised a lot of interest in the publishing industry. In December, Michael Steidl was invited to present a webinar to IPTC member BVPA about IPTC Photo Metadata.
Membership updates
- We announced the IPTC Startup Membership category in September, and our first Startup Member to join is IMATAG.
- DATAGROUP Consulting Services joined as a Voting Member.
- New Associate Members are CBC / Radio Canada, iMatrics, and DeFodi Images.
- New Individual Members are Margaret Warren and Alison Sullivan.
We’re very happy to have them all on board and joining in the IPTC community!
Some sad news
It was with great shock that we learned in early November that longstanding member Andy Read of BBC had passed away. He was a key contributor in many areas and his friendliness and enthusiasm will be hugely missed. Rest in peace, friend.
Looking forward
It seems that we have come through the worst 2020 could throw at us and things are looking up for 2021. We are already thinking about 2021’s events and how we can learn from 2020 to improve things for members and friends in 2021.
Best wishes for the holiday season from all of us at IPTC.
PS: If you have any questions or thoughts about how IPTC could help you, or if you are interested in talking about joining IPTC, please contact Managing Director, Brendan Quinn at mdirector@iptc.org.
A clear majority of professional photo businesses in Europe and North America find IPTC photo metadata highly relevant to their business. That is the message received by IPTC from its 2019 photo industry supplier survey.
According to survey results, eight out of ten photo supplier companies say that data describing images and supporting searches by users is most relevant. Eight out of ten photographers say that metadata to express ownership and usage rights is most important.
These trends are shown by a survey among photo professionals conducted by IPTC, the maker of the industry standard for embedding descriptive, rights information and administrative metadata into images. The 2019 IPTC Photo Metadata Survey results were made public on 14 August 2019 and can be downloaded from the iptc.org website.
“We know that taking the time to apply photo metadata is an investment by photo businesses, so it’s good to see that they get a return,” said Michael Steidl, lead of IPTC’s Photo Metadata Working Group. “Still, we are pleasantly surprised by the importance that photo businesses give to metadata.”
The survey investigated how and why IPTC photo metadata are used in 2019, and more than 100 supplier companies and photographers from many European countries and the USA participated. Most respondents to the supplier survey are companies active in the stock images business, but IPTC also received responses from companies dealing with news photos, cultural heritage images and video footage. The primary business areas of photographers are stock images and public relations photos.
The main reason for applying descriptions of what is depicted in an image are for supplier companies business needs, primarily to help users or customers to find an image they are looking for. Businesses apply rights and licensing data primarily because of legal requirements, but also to protect their companies revenue streams. Administrative data are added to satisfy customer needs.
For photographers, rights are of critical importance
The use of rights data by photographers is more driven by their own business needs than by legal requirements. As photographers are the first party in the supply chain of images they have a high interest to claim who is the creator and the first copyright owner of each creative work. Applying descriptions of the image is driven by customer needs and business needs of photographers. Why administrative data is applied comes also from their business needs and much less from customer needs compared to supplier companies.
IPTC photo metadata – used since 1995
The IPTC photo metadata standard originated in 1995 when Adobe and other makers of image software adopted the IPTC Information Interchange Model (IIM) standard for the panels with fields describing what an image shows, providing the name of the photographer, stating copyright and usage terms, and sharing instructions and more administrative information. In 2005 IPTC published its first Photo Metadata Standard covering fields used by photo professionals and expressed by the IIM format and the then-new XMP format. The IPTC fields were substantially extended in 2008 and since then the standard has been continuously maintained by IPTC, the global standards body of the news media.
For more information, download the full analysis of supplier survey results as a PDF.
Recently conversations on Twitter and various blogs and news sites have reported on Facebook’s use of IPTC embedded photo metadata fields to “track users”. (Reddit.com: “Facebook is embedding tracking data inside the photos you download”, The Australian: “Facebook pics tracking you”, Forbes: “Facebook Embeds ‘Hidden Codes’ To Track Who Sees And Shares Your Photos”, Financial Express: “Beware! Facebook embeds tracking data inside photos you download”).
As the creators and maintainers of the IPTC Photo Metadata Standard, we want to clarify a few points and share our own analysis of the situation.
In Spring 2019, IPTC’s Photo Metadata Working Group conducted our latest round of tests regarding how various social media platforms deal with metadata embedded in uploaded and shared images. The 2019 test results show how Facebook treats image metadata: in IIM and EXIF formats, a few fields are retained related to claiming rights while all others are removed, and in the XMP format all fields are removed.
While this was a small improvement compared to the previous IPTC test in 2016 when all Exif fields were removed, we did not rate Facebook with a “green dot” showing compliance with IPTC standards, as removing metadata embedded by the owner of an image contradicts IPTC’s strong support for keeping metadata persistent.
In addition, in both the 2016 and 2019 tests the Working Group found that two fields in the IIM format do indeed appear to be given values populated by Facebook.
IPTC looks at the facts
IPTC provides a reference image for each version of its Photo Metadata Standard which contains a test value for every specified metadata field. This makes it easy to test which fields are removed or modified.
The reference image of the 2017.1 version of the standard was uploaded to Facebook by the Working Group member David Riecks and it can still be seen here. Next the group used the IPTC’s Get IPTC Photo Metadata website tool for retrieving embedded metadata of most of the images shown on the web. Anyone can use this tool: simply fill the URL of the image into the site’s form and click to see all the metadata embedded in the image.
{kind=link}
This test was performed using the URL of the IPTC reference image uploaded to Facebook and the result was shown instantly:
{kind=link}
- Embedded metadata fields in the IIM format related to rights were retained: Creator, Creator Job Title, Copyright Notice, Credit Line, Source and Description Writer.
- All embedded metadata using the XMP format were removed by Facebook.
- The Creator and the Copyright Notice in the Exif format were also retained.
- The Instructions field and the Job Id field in IIM show values significantly different from what had been uploaded. The IPTC Working Group assumes these values were inserted by Facebook:
- The value of the Instructions field starts with FBMD. The IPTC Working Group retrieved this image using “Save As…” and another Facebook user uploaded it to his account. Result: the value was not changed during the second upload to Facebook. These results were shown for the re-uploaded image.
- The value of the Job Id fields looks like a unique identifier. If an uploaded image is downloaded using the Save As function and then uploaded by another Facebook user this field contains a different value.
- The IPTC Working Group searched for any documentation of these inserted values but found no specification or statement from Facebook. There have been, however, many guesses and assumptions by users and developers.

Using the Get IPTC Photo Metadata site anybody can check what Facebook values were applied to her or his photo. As a user, you can find Facebook image URLs by clicking on the image on the Facebook site and using the “Copy image address” or the “Inspect” or “Inspect Element” function of your web browser, you should then see the URL.
IPTC’s summary
IPTC tests showed when a Facebook member uploads an image to the Facebook system it removes a lot of fields, keeps only a few related to rights and replaces or adds values to the Job Id and the Instructions fields. The role of these values is not publicly documented by Facebook, so they are currently the subject of significant speculation.
IPTC makes no assumptions about what the metadata values are used for, but Facebook appears to keep the value of the Instructions field constant even when the image is re-uploaded by another user. The Job ID field on the other hand changes with each separate upload.
Our recommendations are that all embedded metadata values should be retained by platforms and that no platform should be overwriting user metadata.
IPTC’s 2019 Social Media Platforms survey also looked at the metadata usage of other major social media platforms. Interested parties can find more information at Social Media Sites Photo Metadata Test Results 2019.
Technical notes
The example metadata values embedded into the 2017.1 reference image can be checked by going to https://getpmd.iptc.org and clicking on the green button in Option A labeled Get Photo Metadata of Web Image. No image URL is required, as by default the metadata of this reference image is retrieved and displayed.
For those interested in the technical details of embedded photo metadata, the technical formats IIM and XMP are introduced in the IPTC Photo Metadata User Guide, including a look under the hood of image files.
Home and away teams
alignment attribute.Pre-game actions
<actions>
<action sequence-number="1" team-idref="team_9572" type="esacttype:remove" comment="Nuke"></action>
<action sequence-number="2" team-idref="team_6134" type="esacttype:remove" comment="Inferno"></action>
<action sequence-number="3" team-idref="team_9572" type="esacttype:choose" comment="Cache"></action>
<action sequence-number="4" team-idref="team_6134" type="esacttype:choose" comment="Train"></action>
<action sequence-number="5" team-idref="team_9572" type="esacttype:remove" comment="Overpass"></action>
<action sequence-number="6" team-idref="team_6134" type="esacttype:remove" comment="Dust2"></action>
<action sequence-number="7" type="esacttype:remaining" comment="Mirage"></action>
</actions>
Statistics for eSports teams, players and tournaments
scoping-label on outcome-totals in SportsML:<team-stats score="16" event-outcome="speventoutcome:win"> <outcome-totals scoping-label="T" wins="4" /> <outcome-totals scoping-label="CT" wins="12"/></team-stats><player-stats> <rating rating-value="1.11"/> <stats> <stat stat-type="esstat:kills" value="15" /> <stat stat-type="esstat:headshot" value="6" /> <stat stat-type="esstat:assist" value="4" /> <stat stat-type="esstat:flashassist" value="2" /> <stat stat-type="esstat:deaths" value="11" /> <stat stat-type="esstat:KAST" value="78.3" /> <stat stat-type="esstat:ADR" value="68.4" /> <stat stat-type="esstat:FKdiff" value="0" /> </stats></player-stats>stat construction with stat-type and value we can handle any type of statistic.esstat: and esacttype: in these examples do not currently exist in the IPTC NewsCodes catalog but could easily be set up if needed. It might be necessary to have different prefixes for different type of eSports games. But that would require some more investigation.