Categories
Archives

Last week, the IPTC Spring Meeting 2024 brought media industry experts together for three days in New York City to discuss many topics including AI, archives and authenticity.
Hosted by both The New York Times and Associated Press, over 50 attendees from 14 countries participated in person, with another 30+ delegates attending online.
As usual, the IPTC Working Group leads presented a summary of their most recent work, including a new release of NewsML-G2 (version 2.34, which will be released very soon); forthcoming work on ninjs to support events, planned news coverage and live streamed video; updates to NewsCodes vocabularies; more evangelism of IPTC Sport Schema; and further work on Video Metadata Hub, the IPTC Photo Metadata Standard and our emerging framework for a simple way to express common rights statements using RightsML.
We were very happy to hear many IPTC member organisations presenting at the Spring Meeting. We heard from:
- Anna Dickson of recently-joined member Google talked about their work with IPTC in the past and discussed areas where we could collaborate in the future
- Aimee Rinehart of Associated Press presented AP’s recent report on the use of generative AI in local news
- Scott Yates of JournalList gave an update on the trust.txt protocol
- Andreas Mauczka, Chief Digital Officer at Austria Press Agency APA presented on APA’s framework for use of generative AI in their newsroom
- Drew Wanczowski of Progress Software gave a demonstration of how IPTC standards can be implemented in Progress’s tools such as Semaphore and MarkLogic
- Vincent Nibart and Geert Meulenbelt of new IPTC Startup Member Kairntech presented on their recent work with AFP on news categorisation using IPTC Media Topics and other vocabularies
- Mathieu Desoubeaux of IPTC Startup Member IMATAG presented their work, also with AFP, on watermarking images for tracking and metadata retrieval purposes
In addition we heard from guest speakers:
- Jim Duran of the Vanderbilt TV News Archive spoke about how they are using AI to catalog and tag their extensive archive of decades of broadcast news content
- John Levitt of Elvex spoke about their system which allows media organisations to present a common interface (web interface and developer API) to multiple generative AI models, including tracking, logging, cost monitoring, permissions and other governance features which are important to large organisations using AI models.
- Toshit Panigrahi, co-founder of TollBit spoke about their platform for “AI content licensing at scale”, allowing content owners to establish rules and monitoring around how their content should be licensed for both the training of AI models and for retrieval-augmented generation (RAG)-style on-demand content access by AI agents.
- We also heard an update about the TEMS – Trusted European Media Data Space project.
 We were also lucky enough to take tours of the Associated Press Corporate Archive on Tuesday and the New York Times archive on Wednesday. Valierie Komor of AP Corporate Archives and Jeff Roth of The New York Times Archival Library (known to staffers as “the morgue”) both gave fascinating insights and stories about how both archives preserve the legacy of these historically important news organisations.
We were also lucky enough to take tours of the Associated Press Corporate Archive on Tuesday and the New York Times archive on Wednesday. Valierie Komor of AP Corporate Archives and Jeff Roth of The New York Times Archival Library (known to staffers as “the morgue”) both gave fascinating insights and stories about how both archives preserve the legacy of these historically important news organisations.
Brendan Quinn, speaking for Judy Parnall of the BBC, also presented an update of the recent work of C2PA and Project Origin and introduced the new IPTC Media Provenance Committee, dedicated to bringing C2PA technology to the news and media industry.
On behalf all attendees, we would like to thank The New York Times and Associated Press for hosting us, and especially to thank Jennifer Parrucci of The New York Times and Heather Edwards of The Associated Press for their hard work in coordinating use of their venues for our meeting.
The next IPTC Member Meeting will be the 2024 Autumn Meeting, which will be held online from Monday September 30th to Wednesday October 2nd, and will include the 2024 IPTC Annual General Meeting. The Spring Meeting 2025 will be held in Western Europe at a location still to be determined.

As we wrap up 2023, we thought it would be useful to give an update you on the IPTC’s work in 2023, including updates to most of our standards.
Two successful member meetings, one in person!
This year we finally held our first IPTC Member meeting in person since 2019, in Tallinn Estonia. We had around 30 people attend in person and 50 attended online from over 40 organisations. Presentations and discussions ranged from the e-Estonia digital citizen experience to building re-usable news content widgets with Web Components, and of course included generative AI, credibility and fact checking, and more. Here’s our report on the IPTC 2023 Spring Meeting.
For our Autumn Meeting we went back to an online format, with over 50 attendees, and more watching the recordings afterwards (which are available to all members). Along with discussions of generative AI and content licensing at this year’s meetings, it was great to hear the real-world implementation experience of the ASBU Cloud project from the Arab States Broadcasting Union. The system was created by IPTC members Broadcast Solutions, based on NewsML-G2. The DPP Live Production Exchange, led by new members Arqiva, will be another real-world implementation coming soon. We heard about the project’s first steps at the Autumn Meeting.
Also at this years Autumn Meeting we also heard from Will Kreth of the HAND Identity platform and saw a demo of IPTC Sport Schema from IPTC member Progress Software (previously MarkLogic). More on IPTC Sport Schema below! All news from the Autumn Meeting is summed up in our post AI, Video in the cloud, new standards and more: IPTC Autumn Meeting 2023
We’re very happy to say that the IPTC Spring Meeting 2024 will be held in New York from April 15 – 17. All IPTC member delegates are welcome to attend the meeting at no cost. If you are not a member but would like to present your work at the meeting, please get in touch using our Contact Us form.
IPTC Photo Metadata Conference, 7 May 2024: save the date!
Due to several issues, we were not able to run a Photo Metadata Conference in 2023, but we will be back with an online Photo Metadata Conference on 7th May 2024. Please mark the date in your calendar!
As usual, the event will be free and open for anyone to attend.
If you would like to present to the people most interested in photo metadata from around the world, please let us know!
Presentations at other conferences and work with other organisations
IPTC was represented at the CEPIC Congress in France, the EBU DataTech Seminar in Geneva, Sports Video Group Content Management Forum in New York and the DMLA’s International Digital Media Licensing Conference in San Francisco.
We also worked with CIPA, the organisation behind the Exif photo metadata standard, on aligning Exif with IPTC Photo Metadata, and supported them in their work towards Exif 3.0 which was announced in June.
The IPTC will be advising the TEMS project which is an EU-funded initiative to build a “media data space” for Europe, and possibly beyond: IPTC working with alliance to build a European Media Data Space.
IPTC’s work on Generative AI and media
Of course the big topic for media in 2023 has been Generative AI. We have been looking at this topic for several years, since it was known as “synthetic media” and back in 2022 we created a taxonomy of “digital source types” that can be used to describe various forms of machine-generated and machine-assisted content creation. This was a joint effort across our NewsCodes, Video Metadata and Photo Metadata Working Groups.

It turns out that this was very useful, and the IPTC Digital Source Type taxonomy has been adopted by Google, Midjourney, C2PA and others as a way to describe content. Here are some of our news posts from 2023 on this topic:
- IPTC publishes metadata guidance for AI-generated “synthetic media”
- Google announces use of IPTC metadata for generative AI images
- Midjourney and Shutterstock AI sign up to use of IPTC Digital Source Type to signal generated AI content
- Microsoft announces signalling of generative AI content using IPTC and C2PA metadata
- Royal Society/BBC workshop on Generative AI and content provenance
- New “digital source type” term added to support inpainting and outpainting in Generative AI
- IPTC releases technical guidance for creating and editing metadata, including DigitalSourceType
IPTC’s work on Trust and Credibility

After a lot of drafting work over several years, we released the Guidelines for Expressing Trust and Credibility signals in IPTC standards that shows how to embed trust infiormation in the form of “trust indicators” such as those from The Trust Project into content marked up using IPTC standards such as NewsML-G2 and ninjs. The guideline also discusses how media can be signed using C2PA specification.
We continue to work with C2PA on the underlying specification allowing signed metadata to be added to media content so that it becomes “tamper-evident”. However C2PA specification in its current form does not prescribe where the certificates used for signing should come from. To that end, we have been working with Microsoft, BBC, CBC / Radio Canada and The New York Times on the Steering Committee of Project Origin to create a trust ecosystem for the media industry. Stay tuned for more developments from Project Origin during 2024.
IPTC’s newest standard: IPTC Sport Schema
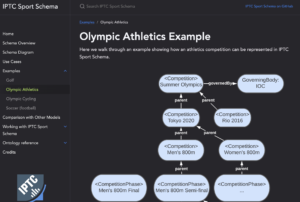
After years of work, the IPTC Sports Content Working Group released version 1.0 of IPTC Sport Schema. IPTC Sport Schema takes the experience of IPTC’s 10+ years of maintaining the XML-based SportsML standard and applies it to the world of the semantic web, knowledge graphs and linked data.
Paul Kelly, Lead of the IPTC Sports Content Working Group, presented IPTC Sport Schema to the world’s top sports media technologists: IPTC Sport Schema launched at Sports Video Group Content Management Forum.
Take a look at out dedicated site https://sportschema.org/ to see how it works, look at some demonstration data and try out a query engine to explore the data.
If you’re interested in using IPTC Sport Schema as the basis for sports data at your organisation, please let us know. We would be very happy to help you to get started.
Standard and Working Group updates
- Our IPTC NewsCodes vocabularies had two big updates, the NewsCodes 2023-Q1 update and the NewsCodes Q3 2023 update. For our main subject taxonomy Media Topics, over the year we added 12 new concepts, retired 73 under-used terms, and modified 158 terms to make their labels and/or descriptions easier to understand. We also added or updated vocabularies such as Digital Source Type and Authority Status.
- The News in JSON Working Group released ninjs 2.1 and ninjs 1.5 in parallel, so that people who cannot move from the 1.x schema can still get the benefits of new additions. The group is currently working on adding events and planning items to ninjs based on requirements the DPP Live Production Exchange project: expect to see something released in 2024.
- NewsML-G2 2.32 and NewsML-G2 v2.33 were released this year, including support for Generative AI via the Digital Source Type vocabulary.
- The IPTC Photo Metadata Standard 2023.1 allows rightsholders to express whether or not they are willing to allow their content to be indexed by search engines and data mining crawlers, and whether the content can be used as training data for Generative AI. This work was done in partnership with the PLUS Coalition. We also updated the IPTC Photo Metadata Mapping Guidelines to accommodate Exif 3.0.
- Through discussions and workshops at our Member Meetings in 2022 and 2023, we have been working on making RightsML easier to use and easier to understand. Stay tuned for more news on RightsML in 2024.
- Video Metadata Hub 1.5 adds the same properties to allow content to be excluded from generative AI training data sets. We have also updated the Video Metadata Hub Generator tool to generate C2PA-compliant metadata “assertions”.
New faces at IPTC
Ian Young of Alamy / PA Media Group stepped up to become the lead of the News in JSON Working Group, taking over from Johan Lindgren of TT who is winding down his duties but still contributes to the group.
We welcomed Bonnier News, Newsbridge, Arqiva, the Australian Broadcasting Corporation and Neuwo.ai as new IPTC members, plus a very well known name who will be joining at the start of 2024. We’re very happy to have you all as members!
We are always happy to work with more organisations in the media and related industries. If you would like to talk to us about joining IPTC, please complete our membership enquiry form.
Here’s to a great 2024!
Thanks to everyone who gave IPTC your support, and we look forward to working with you in the coming year.
If you have any questions or comments (and especially if you would like to speak at one of our events in 2024!), you can contact us via our contact form.
Best wishes,
Brendan Quinn
Managing Director, IPTC
and the IPTC Board of Directors: Dave Compton (LSE Group), Heather Edwards (The Associated Press), Paul Harman (Bloomberg LP), Gerald Innerwinkler (APA), Philippe Mougin (Agence France-Presse), Jennifer Parrucci (The New York Times), Robert Schmidt-Nia of DATAGROUP (Chair of the Board), Guowei Wu (Xinhua)

Where else can you hear about the difficulties of examining photo metadata in NFTs, see a lifelike image of a human being generated from pure data before your eyes, see how Wikidata can be used to take semantic fingerprints of news articles, and discover that an hour is nowhere near long enough to discuss simplifying machine-readable rights? Nowhere but the IPTC Meeting, of course! And this year’s Spring Meeting was the venue for all of this and much more.
We held the meeting virtually from Monday May 16 to Wednesday May 18th, and attending were over 70 people from at least 45 organisations across more than 20 countries.
Along with our usual Working Group updates and committee meetings, we invited speakers from several fascinating startups, services and projects at member companies. Here’s a quick summary of their sessions:
- We heard from Kairntech who are working on a classification system based on extracting entities from news stories and building a “semantic fingerprint” which can be used for cross-language classification, search and content enhancement
- The New York Times’ R&D Lab presented PaperTrail, a project to enhance the quality of the Times’ print archive through the use of machine learning to improve on basic OCR techniques (they’re looking for collaborators, more info coming soon!)
- Bria.ai showed us how an API can be used to enhance and create images and videos through the use of a custom GAN model trained in a “responsible AI” method
- Margaret Warren talked us through her efforts in creating and selling an NFT, looking at the process view the perspective of a photo metadata expert
- Consultant and author Henrik de Gyor talked us through the latest in synthetic media, which will be helpful in helping us to finalise our Digital Source Type vocabulary for synthetic media
- Laurent Le Meur from EDRLab presented his project’s recommendation on a Text and Data Mining Reservation Protocol, which can be used by publishers to restrict the rights of data miners in scraping any content for the purpose of analysis or building a model
- We heard from Dominic Young of Axate on his approach to offer pay-as-you-go payment options on paywalled news sites based on a simple pre-paid wallet mechanism.
We also had many announcements and discussions around IPTC standards, many of which we will be revealing in the coming months. One notable update is that the Standards Committee approved ninjs version 1.4 which we will release soon.
Thanks to all the IPTC members, Working Group leads, committee members and guests who made this member meeting one to remember.
 Brendan Quinn, Managing Director of IPTC, spoke on 20 April 2021 at the regular meeting of the W3C Text and Data Mining Reservation Protocol Community Group.
Brendan Quinn, Managing Director of IPTC, spoke on 20 April 2021 at the regular meeting of the W3C Text and Data Mining Reservation Protocol Community Group.
The Community Group, open to anyone to join, is discussing how to “facilitate a technical protocol to reserve a publisher’s right for content to be made available for text and data mining (TDM). The solution should be capable of expressing the reservation of TDM rights – following the rules set by Article 4 of the new European DSM Directive – and the availability of machine-readable licenses for TDM actors.”
The Community Group is looking at various technologies for representing machine-readable licences, and Brendan presented IPTC’s RightsML as a possible option. Based on W3C’s ODRL, RightsML allows rights holders to specify permissions, prohibitions and constraints on usage of all types of media content, so it may be a good candidate for representing rights around data mining.
Laurent Le Meur, Chair of the TDM Reservation Protocol Community Group and previous contributor to IPTC, presented at the IPTC Autumn Meeting in 2020 to discuss the proposed project.
Day 2 of the IPTC Autumn Meeting 2019 was just as busy as Day 1: we heard from the IPTC NewsCodes Working Group, the AI Expert Group, and the News Architecture Working Group including updates on IPTC’s work on trust and credibility projects. We also had updates from the Video Metadata Working Group, an update on IPTC’s Rights work, and news from the Sports Content Working Group. Phew!
Jennifer Parrucci from the New York Times, lead of the IPTC NewsCodes Working Group, introduced IPTC NewsCodes and discussed recent progress, including cleaning up large parts of the Media Topics vocabulary. The Working Group also announced new language translations coming very soon: Portuguese and Brazilian Portuguese are ready, Chinese is almost ready, and some other language versions are in progress.
We also had an interesting and productive discussion about the workflow and process around Media Topics translations. As the team adds and retires terms and definitions, how should translations be managed? Should we not publish changes until we have translations in all languages? Or should there be a core of languages that require translations? Should we publish interim versions with un-synced changes and less frequent “stable” versions of Media Topics including all translations? We are having success using GitHub issues to manage regular changes to the taxonomy: can technology also help in managing the translation process and if so, which tools? Many ideas and thoughts were shared, including the perspectives of many member organisations who already work across multiple languages.

Tao Chen, VP of Machine Learning at 500px and lead of the new AI Expert Group, gave a great overview of the latest developments in AI affecting the media industry. From practical developments, like removing backgrounds from stock images, detecting copyright infringement and assessing the commercial potential of images, to the dangers of face swapping apps and a potential future of completely generated images that feature no real human beings, we learned a lot about how AI affects us today and tomorrow. We are building up the AI Expert Group to become the place where media technologists can go to learn the latest on AI and Machine Learning issues, apply the latest techniques in the media industry, and share ideas with their peers. If you’re a member and not yet involved, please talk to Tao or Brendan to get started.
Next up, Brendan Quinn spoke about IPTC’s recent work with the Journalism Trust Initiative and The Trust Project, on mapping their “trust indicators” to IPTC standards (particularly NewsML-G2) so news providers can show how they comply with trust criteria. Look out for some announcements about this work in the next few weeks. Then Dave Compton of Refinitiv, lead of the News Architecture Working Group gave an update on recent work on NewsML-G2, including the trust and credibility work, a NewsML-G2 2.28 errata release fixing some small typo errors, updates to the NewsML-G2 Guidelines and the NewsML-G2 Specification documents, work on making local extensions to Media Topics, and future work, including looking at how to represent auto-generated content, and better alignment with ninjs (see Monday’s wrap-up post for more on our recent ninjs updates).

After lunch, Pam Fisher of The Media Institute at University College London spoke about her project to build a read/write API that maps metadata between various video formats. We will link to a demo as soon as it is available. Pam also discussed “compact video signatures”, part of MPEG7, which are being used to make content fingerprints for video content, used for infringement detection and content matching.
Pam’s talk was very relevant to the next discussion by Michael Steidl, lead of the Video Metadata Working Group updating on recent progress. The Working Group has been looking at new video APIs and understanding how IPTC members and others are using video metadata in their work, either with or without IPTC Video Metadata Hub.
In the afternoon Michael Steidl presented again with an update on his work with W3C’s ODRL group which impacts on RightsML. Johan Lindgren presented in lieu of Paul Kelly, new Lead of the Sports Content Working Group, giving an update on the Working Groups efforts to interview IPTC members and others about their use of sports data and to position SportsML and our work on SportsJS in the context of the news and media industry.

Finally we bade farewell to Stuart Myles, outgoing Chair of IPTC. We presented Stuart with a small token of our thanks for chairing the Board of Directors of IPTC since 2014, and has been involved with IPTC as a delegate since 1999! We will definitely miss his contributions, intelligence, common sense and enthusiasm, and we hope to see him involved with IPTC again in the future in some way.