Categories
Archives
We at IPTC receive many requests for help and advice regarding editing embedded photo and video metadata, and this has only increased with the recent news about the IPTC Digital Source Type property being used to identify content created by a generative AI engine.
In response, we have created some guidance: Developers’ and power users’ guide to reading and writing IPTC Photo Metadata
This takes the form of a wiki, so that it can be easily maintained and extended with more information and examples.
In its initial form, the documentation focuses on:
- Using the ExifTool command-line tool to read and write IPTC Photo Metadata,. ExifTool is commonly used by developers and power users to explore embedded metadata;
- Reading and writing image metadata in Python using the pyexiftool module;
- Reading and writing metadata in JavaScript (or TypeScript) using the node-exiftool module.
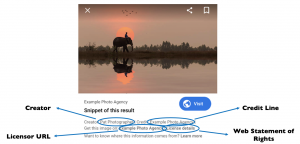
In each guide, we advise on how to read and create DigitalSourceType metadata for generative AI images, and also how to read and write the Creator, Credit Line, Web Statement of Rights and Licensor information that is currently used by Google image search to expose copyright information alongside search results.
We hope that these guides will help to demystify image metadata and encourage more developers to include more metadata in their image editing and publishing workflows.
We will add more guidance over the coming months in more programming languages, libraries and frameworks. Of particular interest are guides to reading and writing IPTC Photo Metadata in PHP, C and Rust.
Contributions and feedback are welcome. Please contact us if you are interested in contributing.
The IPTC is proud to announce that after intense work by most of its Working Groups, we have published version 1.0 of our guidelines document: Expressing Trust and Credibility Information in IPTC Standards.
The culmination of a large amount of work over the past several years across many of IPTC’s Working Groups, the document represents a guide for news providers as to how to express signals of trust known as “Trust Indicators” into their content.
Trust Indicators are ways that news organisations can signal to their readers and viewers that they should be considered as trustworthy publishers of news content. For example, one Trust Indicator is a news outlet’s corrections policy. If the news outlet provides (and follows) a clear guideline regarding when and how it updates its news content.
The IPTC guideline does not define these trust indicators: they were taken from existing work by other groups, mainly the Journalism Trust Initiative (an initiative from Reporters Sans Frontières / Reporters Without Borders) and The Trust Project (a non-profit founded by Sally Lehrman of UC Santa Cruz).
The first part of the guideline document shows how trust indicators created by these standards can be embedded into IPTC-formatted news content, using IPTC’s NewsML-G2 and ninjs standards which are both widely used for storing and distributing news content.
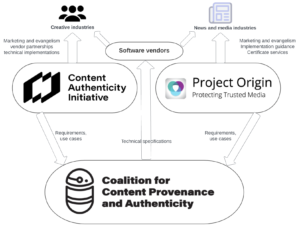
The second part of the IPTC guidelines document describes how cryptographically verifiable metadata can be added to media content. This metadata may express trust indicators but also more traditional metadata such as copyright, licensing, description and accessibility information. This can be achieved using the C2PA specification, which implements the requirements of the news industry via Project Origin and of the wider creative industry via the Content Authenticity Initiative. The IPTC guidelines show how both IPTC Photo Metadata and IPTC Video Metadata Hub metadata can be included in a cryptographically signed “assertion”
We expect these guidelines to evolve as trust and credibility standards and specifications change, particularly in light of recent developments in signalling content created by generative AI engines. We welcome feedback and will be happy to make changes and clarifications based on recommendations.
The IPTC sends its thanks to all IPTC Working Groups that were involved in creating the guidelines, and to all organisations who created the trust indicators and the frameworks upon which this work is based.
Feedback can be shared using the IPTC Contact Us form.
The IPTC NewsCodes Working Group has approved an addition to the Digital Source Type NewsCodes vocabulary.

The new term, “Composite with Trained Algorithmic Media“, is intended to handle situations where the “synthetic composite” term is not specific enough, for example a composite that is specifically made using an AI engine’s “inpainting” or “outpainting” operations.
The full Digital Source Type vocabulary can be accessed from https://cv.iptc.org/newscodes/digitalsourcetype. It can be downloaded in NewsML-G2 (XML), SKOS (RDF/XML, Turtle or JSON-LD) to be integrated into content management and digital asset management systems.
The new term can be used immediately with any tool or standard that supports IPTC’s Digital Source Type vocabulary, including the C2PA specification, the IPTC Photo Metadata Standard and IPTC Video Metadata Hub.
Information on the new term will soon be added to IPTC’s Guidance on using Digital Source Type in the IPTC Photo Metadata User Guide.

CIPA, the Camera and Imaging Products Association based in Japan, has released version 3.0 of the Exif standard for camera data.
The new specification, “CIPA DC-008-Translation-2023 Exchangeable image file format for digital still cameras: Exif Version 3.0” can be downloaded from https://www.cipa.jp/std/documents/download_e.html?DC-008-Translation-2023-E.
Version 1.0 of Exif was released in 1995. The previous revision, 2.32, was released in 2019. The new version introduces some major changes so the creators felt it was necessary to increment the major version number.
Fully internationalised text tags
In previous versions, text-based fields such as Copyright and Artist were required to be in ASCII format, meaning that it was impossible to express many non-English words in Exif tags. (In practice, many software packages simply ignored this advice and used other character sets anyway, violating the specification.)
In Exif 3.0, a new datatype “UTF-8” is introduced, meaning that the same field can now support internationalised character sets, from Chinese to Arabic and Persian.
Unique IDs
The definition of the ImageUniqueID tag has been updated to more clearly specify what type of ID can be used, when it should be updated (never!), and to suggest an algorithm:
This tag indicates an identifier assigned uniquely to each image. It shall be recorded as an ASCII string in hexadecimal notation equivalent to 128-bit fixed length UUID compliant with ISO/IEC 9834-8. The UUID shall be UUID Version 1 or Version 4, and UUID Version 4 is recommended. This ID shall be assigned at the time of shooting image, and the recorded ID shall not be updated or erased by any subsequent editing.
Guidance on when and how tag values can be modified or removed
Exif 3.0 adds a new appendix, Annex H, “Guidelines for Handling Tag Information in Post-processing by Application Software”, which groups metadata into categories such as “structure-related metadata” and “shooting condition-related metadata”. It also classifies metadata in groups based on when they should be modified or deleted, if ever.
|
Category |
Description |
Examples (list may not be exhaustive) |
|
Update 0 |
Shall be updated with image structure change |
DateTime (should be updated with every edit), ImageWidth, Compression, BitsPerSample |
|
Update 1 |
Can be updated regardless of image structure change |
ImageDescription, Software, Artist, Copyright, UserComment, ImageTitle, ImageEditor, ImageEditingSoftware, MetadataEditingSoftware |
|
Freeze 0 |
Shall not be deleted/updated at any time |
ImageUniqueID |
|
Freeze 1 |
Can be deleted in special cases |
Make, Model, BodySerialNumber |
|
Freeze 2 |
Can be corrected [if wrong], added [if empty] or deleted [in special cases] |
DateTimeOriginal, DateTimeDigitized, GPSLatitude, GPSLongitude, LensSpecification, Humidity |
Collaboration between CIPA and IPTC
CIPA and IPTC representatives meet regularly to discuss issues that are relevant to both organisations. During these meetings IPTC has contributed suggestions to the Exif project, particularly around internationalised fields and unique IDs.
We are very happy for our friends at CIPA for reaching this milestone, and hope to continue collaborating in the future.
Developers of photo management software understand that values of Exif tags and IPTC Photo Metadata properties with a similar purpose should be synchronised, but sometimes it wasn’t clear exactly which properties should be aligned. IPTC and CIPA collaborated to create a Mapping Guideline to help software developers implement it properly. Most professional photo software now supports these mappings.
Complete list of changes in Exif 3.0
The full set of changes in Exif 3.0 are as follows (taken from the history section of the PDF document):
- Added Tag Type of UTF-8 as Exif specific tag type.
- Enabled to select UTF-8 character string in existing ASCII-type tags
- Enabled APP11 Marker Segment to store a Box-structured data compliant with the JPEG System standard
- Added definition of Box-structured Annotation Data
- Added and changed the following tags:
- Added Title Tag
- Added Photographer Information related Tags (Photographer and ImageEditor)
- Added Software Information related Tags (CameraFirmware, RAWDevelopingSoftware, ImageEditingSoftware, and MetadataEditingSoftware)
- Changed Software, Artist, and ImageUniqueID
- Corrected incorrect definition of GPSAltitudeRef
- GPSMeasureMode tag became to support positioning information obtained from GNSS in addition to GPS
- Changed the description support levels of the following tags:
- XResolution
- YResolution
- ResolutionUnit
- FlashpixVersion
- Discarded Annex E.3 to specify Application Software Guidelines
- Added Annex H. (at the time of publication) to specify Guidelines for Handling Tag Information in Post-processing by Application Software
- Added Annex I.and J. (both at the time of publication) for supplemental information of Annotation Data
- Added Annex K. (at the time of publication) to specify Original Preservation Image
- Corrected errors, typos and omissions accumulated up to this edition
- Restructured and revised the entire document structure and style

Following the recent announcements of Google’s signalling of generative AI content and Midjourney and Shutterstock the day after, Microsoft has now announced that it will also be signalling the provenance of content created by Microsoft’s generative AI tools such as Bing Image Creator.
Microsoft’s efforts go one step beyond those of Google and Midjourney, because they are adding the image metadata in a way that can be verified using digital certificates. This means that not only is the signal added to the image metadata, but verifiable information is added on who added the metadata and when.
As TechCrunch puts it, “Using cryptographic methods, the capabilities, scheduled to roll out in the coming months, will mark and sign AI-generated content with metadata about the origin of the image or video.”
The system uses the specification created by the Coalition for Content Provenance and Authenticity. a joint project of Project Origin and the Content Authenticity Initiative.
The 1.3 version of the C2PA Specification specifies how a C2PA Action can be used to signal provenance of Generative AI content. This uses the IPTC DigitalSourceType vocabulary – the same vocabulary used by the Google and Midjourney implementations.
This follows IPTC’s guidance on how to use the DigitalSourceType property, published earlier this month.

As a follow-up to yesterday’s news on Google using IPTC metadata to mark AI-generated content we are happy to announce that generative AI tools from Midjourney and Shutterstock will both be adopting the same guidelines.
According to a post on Google’s blog, Midjourney and Shutterstock will be using the same mechanism as Google – that is, using the IPTC “Digital Source Type” property to embed a marker that the content was created by a generative AI tool. Google will be detecting this metadata and using it to show a signal in search results that the content has been AI-generated.
A step towards implementing responsible practices for AI
We at IPTC are very excited to see this concrete implementation of our guidance on metadata for synthetic media.
We also see it as a real-world implementation of the guidelines on Responsible Practices for Synthetic Media from the Partnership on AI, and of the AI Ethical Guidelines for the Re-Use and Production of Visual Content from CEPIC, the alliance of European picture agencies. Both of these best practice guidelines emphasise the need for transparency in declaring content that was created using AI tools.
The phrase from the CEPIC transparency guidelines is “Inform users that the media or content is synthetic, through
labelling or cryptographic means, when the media created includes synthetic elements.”
The equivalent recommendation from the Partnership on AI guidelines is called indirect disclosure:
“Indirect disclosure is embedded and includes, but is not limited to, applying cryptographic provenance to synthetic outputs (such as the C2PA standard), applying traceable elements to training data and outputs, synthetic media file metadata, synthetic media pixel composition, and single-frame disclosure statements in videos”
Here is a simple, concrete way of implementing these disclosure / transparency guidelines using existing metadata standards.
Moving towards a provenance ecosystem
IPTC is also involved in efforts to embed transparency and provenance metadata in a way that can be protected using cryptography: C2PA, the Content Authenticity Initiative, and Project Origin.
C2PA provides a way of declaring the same “Digital Source Type” information in a more robust way, that can provide mechanisms to retrieve metadata even after the image was manipulated or after the metadata was stripped from the file.
However implementing C2PA technology is more complicated, and involves obtaining and managing digital certificates, among other things. Also C2PA technology has not been implemented by platforms or search engines on the display side.
In the short term, AI content creation systems can use this simple mechanism to add disclosure information to their content.
The IPTC is happy to help any other parties to implement these metadata signals: please contact IPTC via the Contact Us form.
At today’s Google I/O event keynote, Sundar Pichai, CEO of Google, explained how Google will be using embedded IPTC image metadata to signal visual media created by generative AI models.
“Moving forward, we are building our models to include watermarking and other techniques from the start,” Pichai said. “If you look at a synthetic image, it’s impressive how real it looks, so you can imagine how important this is going to be in the future.
“Metadata allows content creators to associate additional context with original files, giving you more information whenever you encounter an image. We’ll ensure every one of our AI-generated images has that metadata.”
The IPTC Photo Metadata section of Google Images’ guidance on metadata has been updated with new guidance on the DigitalSourceType field:
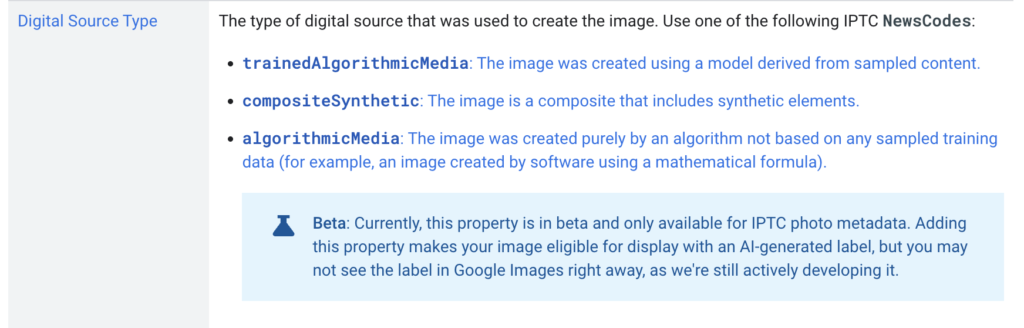
This follows the guidance on IPTC Photo Metadata for Generative AI that was recently published by IPTC.
“AI-Generated” label on Google Images
The above guidance hints at an “AI-generated label” to be used on Google Images in the future. Google recommends that all creators of AI-generated images use the IPTC Digital Source Type property to signal AI-generated content. While Google says that “you may not see the label in Google Images right away”, it appears that it will soon be available in Google Images search results.

The IPTC has updated its Photo Metadata User Guide to include some best practice guidelines for how to use embedded metadata to signal “synthetic media” content that was created by generative AI systems.
After our work in 2022 and the draft vocabulary to support synthetic media, the IPTC NewsCodes Working Group, Video Metadata Working Group and Photo Metadata Working Group worked together with several experts and organisations to come up with a definitive list of “digital source types” that includes various types of machine-generated content, or hybrid human and machine-generated media.
Since publishing the vocabulary, the work has been picked up by the Coalition for Content Provenance and Authenticity (C2PA) via the use of digitalSourceType in Actions and in the IPTC Photo and Video Metadata assertion. But the primary use case is for adding metadata to image and video files
Here is a direct link to the new section on Guidance for using Digital Source Type, including examples for how the various terms can be used to describe media created in different formats – audio, video, images and even text.
IPTC recommends that software creating images using trained AI algorithms uses the “Digital Source Type” value of “trainedAlgorithmicMedia” is added to the XMP data packet in generated image and video files. Alternatively, it may be included in a C2PA manifest as described in the IPTC assertion documentation in the C2PA specification.
The official URL for the full vocabulary is http://cv.iptc.org/newscodes/digitalsourcetype, so the complete URI for the recommended Trained Algorithmic Media term is http://cv.iptc.org/newscodes/digitalsourcetype/trainedAlgorithmicMedia.
Other terms in the vocabulary include:
- Composite with synthetic elements – https://cv.iptc.org/newscodes/digitalsourcetype/compositeSynthetic – covering a composite image that contains some synthetic and some elements captured with a camera;
- Digital Art – https://cv.iptc.org/newscodes/digitalsourcetype/digitalArt – covering art created by a human using digital tools such as a mouse or digital pencil, or computer-generated imagery (CGI) video
- Virtual recording – https://cv.iptc.org/newscodes/digitalsourcetype/virtualRecording – a recording of a virtual event which may or may not contain synthetic elements, such as a Fortnite game or a Zoom meeting
- and several other options – see the full list with examples in the IPTC Photo Metadata User Guide.
Of course, the original digital source type values covering photographs taken on a digital camera or phone (digitalCapture), scan from negative (negativeFilm), and images digitised from print (print) are also valid and may continue to be used. We have, however, retired the generic term “softwareImage” which is now deemed to be too generic. We recommend using one of the newer terms in its place.
If you are considering implementing this guidance in AI image generation software, we would love to hear about it so we can offer advice and tell others. Please contact us using the IPTC contact form.

Here is a wrap-up of IPTC has been up to in 2022, covering our latest work, including updates to most of our key standards.
Two successful member meetings and five member webinars
This year we again held our member meetings online, in May and October. We had over 70 registered attendees each time, from over 40 organisations, which is well over half of our member organisations so it shows that the virtual format works well.
This year we had guests from United Robots, Kairntech, EDRLab, Axate, HAND Identity, RealityDefender.ai, synthetic media consultant Henrik de Gyor and metaverse expert Toby Allen, as well as member presentations from The New York Times, Agence France-Presse, Refinitiv (an LSE Group company), DATAGROUP Consulting, TT Sweden, iMatrics and more. And that’s not even counting our regular Working Group presentations! So we had a very busy three days in May and October.
We also had some very interesting members-only webinars including a deep dive into ninjs 2.0, JournalList and the trust.txt protocol, a joint webinar with the EBU on how Wikidata and IPTC Media Topics can be used together, and a great behind the scenes question-and-answer session with a product manager from Wikidata itself.
Recordings of all presentations and webinars are available to IPTC members in the Members-Only Zone.
A fascinating Photo Metadata Conference
This year’s IPTC Photo Metadata Conference was held online in November and we had over 150 registrants and 19 speakers from Microsoft, CBC Radio Canada, BBC, Adobe, Content Authenticity Initiative, the Smithsonian and more. The general theme was bringing the IPTC Photo Metadata Standard to the real world, focussing on adoption of the recently-introduced accessibility properties, looking at adoption and interoperability between different software tools, including a new comparison tool that we have introduced; use of C2PA and Content Authenticity in newsroom workflows, with demos from the BBC and CBC (with Microsoft Azure).
We also had an interesting session discussing the future of AI-generated images and how metadata could help to identify which images are synthetic, the directions and algorithms used to create them, and whether or not the models were trained on copyrighted images.
Recordings of all sessions are available online.
Presentations at other conferences, work with other organisations
IPTC was represented at the CEPIC Congress in Spain, the DigiTIPS conference run by imaging.org, the Sports Video Group’s content management group, and several Project Origin events.
Our work with C2PA is progressing well. As of version 1.2 of the C2PA Specification, assertions can now include any property from IPTC Photo Metadata Standard and/or IPTC Video Metadata Hub. C2PA support is growing in tools and is now available in Adobe Photoshop.
IPTC is also working with Project Origin on enabling C2PA in the news industry.
We had an IPTC member meet-up at the NAB Show in Las Vegas in May.
We also meet regularly with Google, schema.org, CIPA (the camera-makers behind the Exif standard), ISO, CEPIC and more.
Standard and Working Group updates
- Our IPTC NewsCodes vocabularies had regular updates each quarter, including 12 new terms at least 20 retired terms. See the details in our news posts about the September Update, July Update, May Update, and the February Update (in time for the Winter Olympics). We also extended the Digital Source Type vocabulary specifically to address “synthetic media” or AI-generated content.
- The News in JSON Working Group released ninjs 1.4, a parallel release for those who can’t upgrade to ninjs 2.0 which was released in 2021. We published a case study showing how Alamy uses ninjs 2.0 for its content API.
- NewsML-G2 v2.31 includes support for financial instruments without the need to attach them to organisations.
- Photo Metadata Standard 2022.1 includes a Contributor structure aligned with Video Metadata Hub which can handle people who worked on a photograph but did not press the shutter, such as make-up artists, stylists or set designers;
- The Sports Content Working Group is working on the IPTC Sport Schema, which is pre-release but we are showing it to various stakeholders before a wider release for feedback. If you are interested, please let me know!
- Video Metadata Hub 1.4 includes new properties for accessibility, content warnings, AI-generated content, and clarifies the meanings of many other properties.
New faces at IPTC
We waved farewell to Johan Lindgren of TT as a Board Member, after five years of service. Thankfully Johan is staying on as Lead of the News in JSON Working Group.
We welcomed long-time member Heather Edwards of The Associated Press as our newest board member.
We welcomed Activo, Data Language, Denise Kremer, MarkLogic, Truefy, Broadcast Solutions and Access Intelligence as new IPTC members, plus Swedish publisher Bonnier News who are joining at the start of 2023. We’re very happy to have you all as members!
If you are interested in joining, please fill out our membership enquiry form.
Web site updates
We launched a new, comprehensive navigation bar on this website, making it easier to find our most important content.
We have also just launched a new section highlighting the “themes” that IPTC is watching across all of our Working Groups:
We would love to hear what you think about the new sections, which hopefully bring the site to life.
Best wishes to all for a successful 2023!
Thanks to everyone who has supported IPTC this year, whether as members, speakers at our events, contributors to our standards development or software vendors implementing our standards. Thanks for all your support, and we look forward to working with you more in the coming year.
If you have any questions or comments, you can contact me directly at mdirector@iptc.org.
Best wishes,
Brendan Quinn
Managing Director, IPTC
We had a great Photo Metadata Conference last Thursday. Thanks to those who attended. For those who didn’t, or those who would like to go over some detail again, here we publish full recordings of all sessions.
First up, Brendan Quinn, IPTC Managing Director introduced the day and gave an overview of what was to come:
Next was a great panel on adoption of the accessibility properties added in the 2021.1 update to the IPTC Photo Metadata Standard. We are very happy to share that the fields are now supported in many popular photo creating and editing tools, with more to come:
Next was David Riecks and Michael Steidl, co-leads of the IPTC Photo Metadata Working Group, presenting the work done by the Working Group since the last Photo Metadata Conference:
Then came a session on real-world implementations of the C2PA specification for content authenticity, including presentations from Microsoft, CBC / Radio Canada, the BBC and Adobe / Content Authenticity Initiative:
The last session was a panel discussion on Metadata for AI Images, looking at questions around the ethics of using copyrighted content to train a machine learning engine to generate AI images, and how the IPTC Photo Metadata Standard could be extended to support metadata appropriate for AI-generated images:
We had a great session and a packed conference! We look forward to seeing everyone again at next year’s event.