Categories
Archives
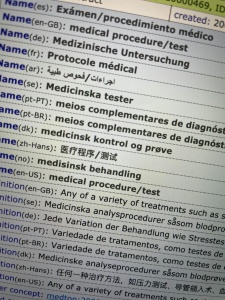 We have just released a new version of IPTC NewsCodes, which includes many changes to Media Topics.
We have just released a new version of IPTC NewsCodes, which includes many changes to Media Topics.
This is the first major update since August 2020 (although we released new versions in September and October 2020 to add translations of new terms).
The changes are detailed below:
New translations for Media Topics
After many requests, we have now added an “en-US” language version, based on a contribution by Jeff Brown of Fourth Estate. Thanks Jeff!
Mostly it simply changes British English words to US English, such as “centre”/”center” and “programme”/”program”, but there are a few more substantive changes around cinema / movies and changing “holiday” to “vacation”. Also where Jeff had suggested changes to definitions, we often changed them for both British and US English.
en-GB will still be the primary language for Media Topics, but we will keep the en-GB and en-US versions in sync as we make changes.
New Media Topics terms
These were suggested by our collaborators from Ritzau via iMatrics, NTB, TT and AFP. Thanks to all.
- animal abuse (http://cv.iptc.org/newscodes/mediatopic/20001314)
- border disputes (http://cv.iptc.org/newscodes/mediatopic/20001316)
- cheerleading (http://cv.iptc.org/newscodes/mediatopic/20001309)
- child care (http://cv.iptc.org/newscodes/mediatopic/20001317)
- disinformation and misinformation http://cv.iptc.org/newscodes/mediatopic/20001319
- kickboxing (http://cv.iptc.org/newscodes/mediatopic/20001310)
- kiting (http://cv.iptc.org/newscodes/mediatopic/20001306) (which includes kitesurfing, kiteboarding, snowkiting and land kiting)
- krav maga (http://cv.iptc.org/newscodes/mediatopic/20001308)
- padel (http://cv.iptc.org/newscodes/mediatopic/20001305)
- pests (http://cv.iptc.org/newscodes/mediatopic/20001318)
- political leadership (http://cv.iptc.org/newscodes/mediatopic/20001312)
- sambo (martial art) (http://cv.iptc.org/newscodes/mediatopic/20001311)
- shootings (http://cv.iptc.org/newscodes/mediatopic/20001313)
- stand up paddleboarding (SUP) (http://cv.iptc.org/newscodes/mediatopic/20001307)
- sport achievement (http://cv.iptc.org/newscodes/mediatopic/20001301)
- sports award (http://cv.iptc.org/newscodes/mediatopic/20001304)
- sports medal (http://cv.iptc.org/newscodes/mediatopic/20001303)
- sports record (http://cv.iptc.org/newscodes/mediatopic/20001302)
- zoo (http://cv.iptc.org/newscodes/mediatopic/20001315)
Please note that the new terms only exist in en-GB and en-US right now, more translations will be added soon.
Update on 15 March: we have now added translations in Danish (thanks to Ritzau and iMatrics), Nowegian (thanks to NTB), Swedish (thanks to TT) and Portuguese for Brazil and Portugal (thanks to Priberam and Lusa).
Update on 12 April: We have now also added Chinese and German translations for these new and updated terms and definitions. Thanks very much to members Xinhua and dpa for their help!
Retired Media Topics terms
- sports facilities (http://cv.iptc.org/newscodes/mediatopic/20000559 (retired)) – use medtop:20001126 “sport venue” instead
- inline skating (http://cv.iptc.org/newscodes/mediatopic/20000967 (retired)) – use medtop:20001155 “roller sports” instead
Label changes to Media Topics
Please note that we only ever make changes to labels to make the meaning clearer, we never change the meaning of a term.
- online media -> online media outlet http://cv.iptc.org/newscodes/mediatopic/20000048
- traffic crime -> reckless driving (http://cv.iptc.org/newscodes/mediatopic/20001196)
- arbitration -> arbitration and mediation (http://cv.iptc.org/newscodes/mediatopic/20000117)
- prosecution -> prosecution and prosecutors (http://cv.iptc.org/newscodes/mediatopic/20000118)
- trade fair -> trade show or expo (http://cv.iptc.org/newscodes/mediatopic/20001136)
- online media -> online media industry (http://cv.iptc.org/newscodes/mediatopic/20000311)
- speciality store -> specialty store (http://cv.iptc.org/newscodes/mediatopic/20000253)
- motorbike enthusiasm -> motorcycle enthusiasm (http://cv.iptc.org/newscodes/mediatopic/20000571)
- parliament -> legislative body (http://cv.iptc.org/newscodes/mediatopic/20000615)
- synchronised swimming -> artistic swimming (http://cv.iptc.org/newscodes/mediatopic/20001175) (as per IOC changes for 2020 Olympics)
Media Topics hierarchy moves
- dropped criminal investigation (http://cv.iptc.org/newscodes/mediatopic/20001200) moved to under investigation (criminal) (http://cv.iptc.org/newscodes/mediatopic/20000131)
- bodybuilding (http://cv.iptc.org/newscodes/mediatopic/20001240) moved to under competition discipline (http://cv.iptc.org/newscodes/mediatopic/20000822)
Definition changes in Media Topics
- Updates to correct British English in en-GB definitions: 20000004, 20001181, 20000041, 20000068, 20000094, 20001283, 20000175, 20000246, 20000458, 20001247, 20000608, 20001292, 20000719, 20000724, 20000804, 20001193, 20000807, 20000835, 20001157
- Fixes to typos and spelling mistakes in en-GB definitions: 20001187, 20000088, 20000263, 20000469, 20000711
- Tweaks to definitions to make the meaning clearer:
- homicide (http://cv.iptc.org/newscodes/mediatopic/20000099)
- prison (http://cv.iptc.org/newscodes/mediatopic/20000137)
- civil law (http://cv.iptc.org/newscodes/mediatopic/20000122)
- police (http://cv.iptc.org/newscodes/mediatopic/20000133)
- real estate (http://cv.iptc.org/newscodes/mediatopic/20000241)
- mining (http://cv.iptc.org/newscodes/mediatopic/20000320)
- geriatric medicine (http://cv.iptc.org/newscodes/mediatopic/20000488)
- leisure venue (http://cv.iptc.org/newscodes/mediatopic/20000553)
- speed skating (http://cv.iptc.org/newscodes/mediatopic/20001067)
- sport venue (http://cv.iptc.org/newscodes/mediatopic/20001126)
Changes to other NewsCodes vocabularies
- http://cv.iptc.org/newscodes/contentprodpartyrole/ – new terms Fact Checker (http://cv.iptc.org/newscodes/contentprodpartyrole/factChecker) and author (http://cv.iptc.org/newscodes/contentprodpartyrole/author)
- http://cv.iptc.org/newscodes/newsprovider/ – new terms http://cv.iptc.org/newscodes/newsprovider/ACCESSWIRE and http://cv.iptc.org/newscodes/newsprovider/NEWSDIRECT
As usual, the changes can be seen:
- Directly on the CV server at http://cv.iptc.org/
- In machine-readable form using SKOS, NewsML-G2 and NewsML 1 (see the cv.iptc.org guidelines for details)
- HTML tree view at https://www.iptc.org/std/NewsCodes/treeview/mediatopic/mediatopic-en-GB.html
- As an interactive diagram on http://show.newscodes.org/
- In Excel format from https://www.iptc.org/std/NewsCodes/IPTC-MediaTopic-NewsCodes.xlsx
Please let us know if you spot any problems. If you are an IPTC member you can post issues, questions and suggestions to the NewsCodes Working Group list at iptc-newscodes-dev@groups.io.
We have made it to the end of 2020. And what a year it has been!

The news and media industry has perhaps been affected less than the travel or hospitality industry, but 2020 was still a hugely eventful year for us all professionally and personally. Congratulations on getting through it, and our thoughts go out to those who have suffered in any way this year.
IPTC Events
Of course our member meetings, planned for Tallinn Estonia and New York USA this year, quickly became virtual events held via Zoom. It worked surprisingly well, and even allowed us to bring on some speakers and guests who wouldn’t have been able to attend or present if we had held the events physically.
You can look back at our Spring Meeting blog posts (Day 1, Day 2, Day 3) and the summary of our Autumn Meeting.
The IPTC Photo Metadata Conference was very interesting this year: from our usual small room hosted as part of the CEPIC Congress, we went to a virtual event with over 200 attendees. If you missed it, or want to re-visit, videos of the sessions are available on YouTube.
Standards work
The News in JSON Working Group submitted ninjs 1.3 for approval at the Spring Meeting, which added fields for trust indicators and genres, support for different types of headlines and alternative IDs. The ninjs generator, showing how easy it is to create a ninjs document by filling in a web form, was very popular and was the inspiration for some related tools in other working groups. Since then, the working group has been looking at more features to be included in future versions of ninjs. If you handle news in JSON in any way and you haven’t completed our News in JSON survey, please do it now!
The NewsML-G2 Working Group released NewsML-G2 2.29 in July which added some fields required for the trust and credibility project, and a new NewsML-G2 Generator tool based on the ninjs one. The group also participated in the trust and credibility projects described below. The NewsML-G2 specifications and guidelines documents have now been updated to version 2.29.
The Video Metadata Working Group released Video Metadata Hub 1.3 during the summer, which added fields to track the editing of metadata (as opposed to editing the actual video), parent video identifier, and updated the mappings to EBUCore and EIDR. The group is hard at work on promoting Video Metadata Hub and creating more introductory materials to help new users understand VMHub and why it is useful.
The NewsCodes Working Group published three updates this year, in March, June and August, and a new update will be published very soon. The NewsCodes Guidelines document was released this year, and is already proving useful both for those wishing to learn how to use NewsCodes better and for the Working Group to establish clear guidelines about when and how to add new terms. MediaTopics is now available in 11 languages and we have more translations coming!
The Photo Metadata Working Group has been very busy, with the biggest news of the year being that Google now supports IPTC Photo Metadata to display licensor information in search results, including a link back to the image owner’s “licence this image” page. The feature was launched in beta in February and launched fully in August. We have had great take-up so far, and the interest in the Photo Metadata Conference (with over 200 people registered) showed that the industry was very keen to hear about it. We also launched updates to the GetPMD tool to support new schema.org mappings, and browser plugins for Chrome and Firefox to enable easy viewing of embedded IPTC Photo Metadata in photographs on the web.
The Sports Content Working Group has had its collective head down in 2020, re-thinking the data model for sports results, statistics and performances. We have been taking a semantic view, looking at using RDF as the main data model for sports data which can then be serialised into JSON, XML and other formats. The intention is that this will also bring the model closer to schema.org in the future. We have some RDF and semantic web experts on the group who are helping with the modelling, and are taking a use-case based approach to make sure that we’re designing something that’s both useful and usable.
A discussion group “spun out” from the NewsCodes Working Group to consider Named Entities for News. So far we have had a couple of meetings to discuss our thoughts on maintaining vocabularies for named entities such as people, companies and places, and to study different approaches used by IPTC member organisations and non-members.
An ongoing project that spans several working groups is the work on Trust and Credibility. After publishing a draft guidelines document in April and a webinar that we ran in September, we plan to publish a 1.0 version in the new year.
All of our Working Groups are always looking for new participants, so if you’re interested in any of these areas, please consider joining IPTC and taking part in a working group!
IPTC appearances at conferences and in the media
There weren’t many conferences in the first part of the year as everyone adjusted to working remotely, but in the second half of the year IPTC people made quite a few appearances at other conferences and webinars.
In July, Brendan Quinn and Robert Schmidt-Nia spoke about NewsML-G2 at an Arab States Broadcasting Union metadata workshop. In September, Michael Steidl spoke on a panel with Google and Alamy at the Perpignan photojournalism conference about Google’s “Licensable Images” feature, and Brendan Quinn hosted a webinar about our work in trust and credibility.
In October, Pam Fisher and Mark Milstein spoke about Video Metadata Hub at the DMLA conference. In November, Brendan Quinn was invited to give a keynote at the FIBEP World Media Intelligence Congress, speaking to the media monitoring / media intelligence industry who also use quite a few IPTC standards.
Also in November, Bill Kasdorf published a column in Publisher’s Weekly about Media Topics and IPTC Photo Metadata which raised a lot of interest in the publishing industry. In December, Michael Steidl was invited to present a webinar to IPTC member BVPA about IPTC Photo Metadata.
Membership updates
- We announced the IPTC Startup Membership category in September, and our first Startup Member to join is IMATAG.
- DATAGROUP Consulting Services joined as a Voting Member.
- New Associate Members are CBC / Radio Canada, iMatrics, and DeFodi Images.
- New Individual Members are Margaret Warren and Alison Sullivan.
We’re very happy to have them all on board and joining in the IPTC community!
Some sad news
It was with great shock that we learned in early November that longstanding member Andy Read of BBC had passed away. He was a key contributor in many areas and his friendliness and enthusiasm will be hugely missed. Rest in peace, friend.
Looking forward
It seems that we have come through the worst 2020 could throw at us and things are looking up for 2021. We are already thinking about 2021’s events and how we can learn from 2020 to improve things for members and friends in 2021.
Best wishes for the holiday season from all of us at IPTC.
PS: If you have any questions or thoughts about how IPTC could help you, or if you are interested in talking about joining IPTC, please contact Managing Director, Brendan Quinn at mdirector@iptc.org.
Today we announce the launch of two new browser extensions for viewing IPTC Photo Metadata on web pages.
The GetPMD tool is one of IPTC’s most popular online resources. With the GetPMD tool, users can view the embedded IPTC metadata of any image on the web, whether it was embedded using either the IPTC IIM or the ISO XMP format. But up to now, users must copy and paste an image’s URL into the tool, or install a browser “bookmarklet”.
To make that a little bit easier, we have created the IPTC Photo Metadata Inspector, a simple browser extension that currently works with the Google Chrome and Mozilla Firefox browsers.
With the extension installed, a context menu will appear when you right-click on an image anywhere on the Web, with a menu option, “View IPTC Photo Metadata.” If you select that option, you will be taken to getpmd.iptc.org where you can see the embedded metadata for that image.
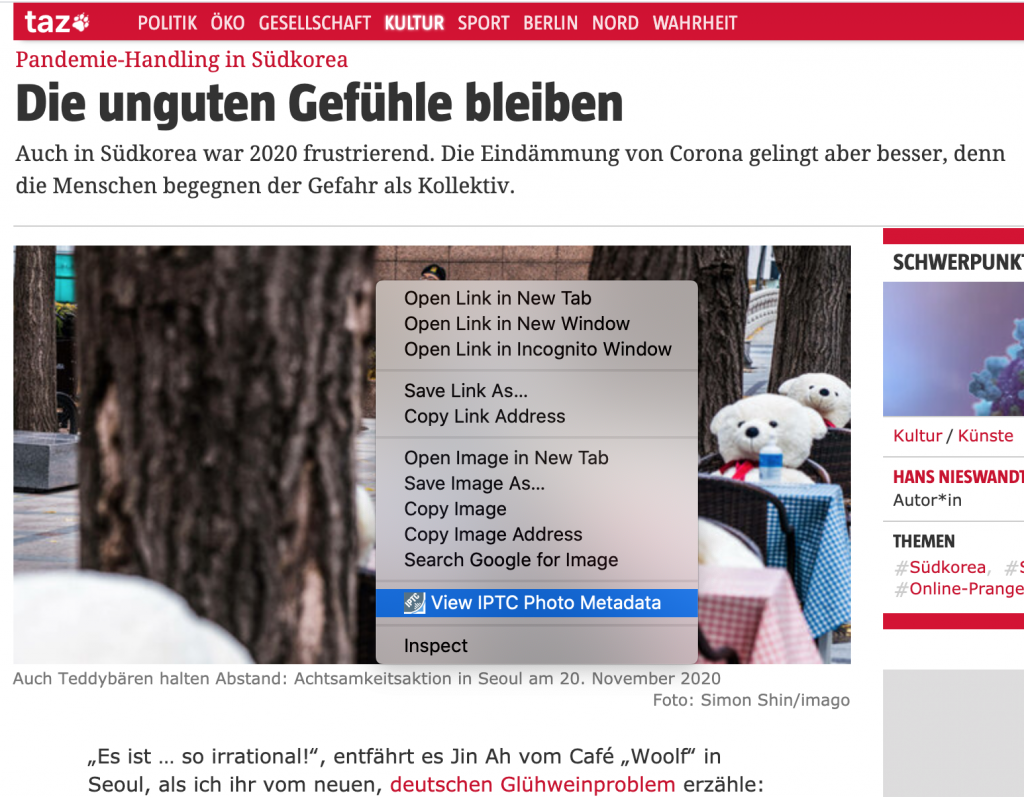
Please note that the Photo Metadata Inspector only works with simple images: it won’t work with embedded video thumbnails or tweets, for example.
The browser extensions are open source, the code is available from the IPTC’s GitHub repository.
Ideas for fixes and new features are welcome.
If you have feedback, please raise an issue on our GitHub repository, post suggestions to the iptc-photometadata@groups.io public discussion list, or contact us via the form on this site.
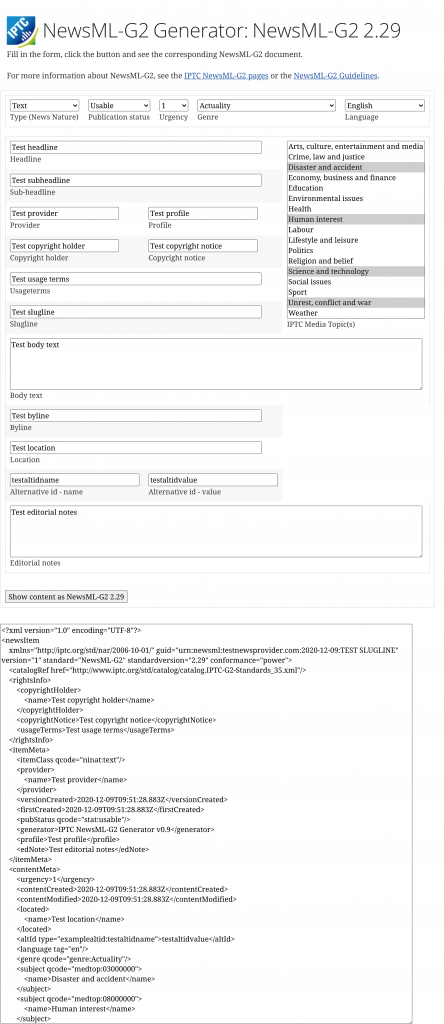
We are pleased to announce the release of the NewsML-G2 Generator, a simple tool to help understand the structure and layout of NewsML-G2 files.
To see how easy it can be to create a valid NewsML-G2 file, simply visit https://iptc.org/std/NewsML-G2/generator/, fill in the form and press the button labelled “Show content as NewsML-G2 2.29”.
Then the box below the form will be filled in with a valid NewsML-G2 document.
The tool demonstrates several key features of NewsML-G2:
- Adding copyright and rights information through the
<copyrightHolder/>,<copyrightNotice/>and<usageTerms/>elements - Adding news-item metadata via the
<itemMeta>container, such as<firstCreated/>,<versionCreated/>, item type (text, audio, video, graphic or composite, selected via a drop-down), publication status (usage, cancelled or withheld, selected via a drop-down) - Adding subject metadata using IPTC Media Topics, via a selection with all of the top-level categories enabled. Subjects are added using the
<subject/>construct within the<contentMeta>container. - Referring to the IPTC catalog that declares standard metadata vocabularies, using the
<catalogRef/>tag - Adding the body content using embedded NITF. In the future, we will add a radio button so users can select whether to embed the news content using NITF or XHTML, which is the other common format used by IPTC members to mark up news content.
Your test content is never saved and only exists within your browser.
The source code of the generator is available in the NewsML-G2 GitHub repository.
This is a simple 1.0 version, and only scratches the surface of the capabilities of NewsML-G2. It is based on the successful ninjs generator used to demonstrate our ninjs standard, which was launched along with ninjs 1.3 earlier this year.
In the future, we are thinking of adding features such as:
- Switch between NITF and XHTML for the content body
- Demonstrate referring to images and video files using
<remoteContent/> - Switch between using qcodes and URIs for metadata
- Demonstrate multiple language support in NewsML-G2
- Demonstrate usage of partMeta to show adding metadata to segments in files, such as audio and video
- Integrate the tool with the ninjs generator so users can switch between ninjs and NewsML-G2 with one click!
If you have any more ideas, please raise an issue on the GitHub repository, or contact us via the IPTC Contact Us form.
To learn more about NewsML-G2, the global standard used for distributing news content, see our introduction to NewsML-G2, or the NewsML-G2 Guidelines.
schema.org is the technology used by web site owners around the world to make metadata available to search engines and other third-party services. It is widely used to embed machine-readable data in websites for products, store opening times and much more.
It is also used as one of the sources of metadata for the Google search results. The schema.org “license”, “acquireLicensePage” and “creator” properties in a page’s HTML code are used in addition to IPTC Photo Metadata embedded in image files to populate the image panel.
schema.org version 11 was released this week. It contains two new properties on the CreativeWork type (and therefore its subtypes such as ImageObject) that were created to match their equivalent properties in IPTC Photo Metadata: copyrightNotice, which matches the IPTC Photo Metadata Copyright Notice property, and creditText, which matches the IPTC Photo Metadata Credit Line property.
The new fields are not yet supported by Google images search, but hopefully will be soon.
After the recent update, the current properties mapped to schema.org and used in Google images search results are:
| IPTC Photo Metadata property | Matching schema.org property | Used in Google search results? |
| Creator | ImageObject -> creator | Yes |
| Copyright Notice | ImageObject -> copyrightNotice | Not yet |
| Credit Line | ImageObject -> creditText | Not yet |
| Web Statement of Rights | ImageObject -> license | Yes |
| Licensor / Licensor URL | ImageObject -> acquireLicensePage | Yes |
The IPTC Photo Metadata Working Group is working on a more comprehensive document showing all possible IPTC Photo Metadata fields with their schema.org and EXIF equivalents. The full mapping document will be released soon.
Yesterday Michael Steidl, Lead of the IPTC Photo Metadata Working Group, gave a webinar to Bundesverband professioneller Bildanbieter (BVPA), the Federal Association of Professional Image Providers in Germany.

The webinar focused on the recently introduced image license information for Google image searches and the possible opportunities and risks for the professional image business.
“This year, Google introduced the so-called Licensable Badge for its image search. This feature enables images to be linked to license information and to be displayed in the image search results with a corresponding link. Image seekers from advertising, editorial offices and corporate PR can follow the link to obtain further information on how to use the image. This turns Google image search into a potential marketplace. But how can image providers use the new tool for themselves? Is it worth the effort of storing the necessary metadata? Are there any economic risks involved? Will Google soon become a meta picture agency?”
In the first part of the webinar, Michael Steidl explained which image metadata must be stored in order to display photo credits and “licensable” badges on Google. He also informed participants about the problem that certain software and web platforms deletes image metadata after upload.
In the second part, Alexander Karst explains the possibilities for increasing visibility through the new features and gives an assessment of the effects on the image market.
Thanks to BVPA for hosting Michael for the webinar.
 Based on discussions at the recent IPTC Autumn Meeting, the IPTC News in JSON Working Group is updating its view of the use of ninjs and other forms of JSON for handling news content.
Based on discussions at the recent IPTC Autumn Meeting, the IPTC News in JSON Working Group is updating its view of the use of ninjs and other forms of JSON for handling news content.
If your organisation uses JSON in any way for handling news content, we would like to hear from you.
We are looking for input from IPTC members and non-members, from agencies, publishers, broadcasters and software vendors.
Please help us by filling in the short survey via this Google Form.
 Bill Kasdorf, principal at Kasdorf & Associates and individual member of IPTC, has published his latest column at Publishers Weekly, “News You Can Use”, where he promotes IPTC standards including IPTC Photo Metadata and IPTC Media Topics.
Bill Kasdorf, principal at Kasdorf & Associates and individual member of IPTC, has published his latest column at Publishers Weekly, “News You Can Use”, where he promotes IPTC standards including IPTC Photo Metadata and IPTC Media Topics.
As Bill says, “I recently attended the IPTC Autumn Meeting, and at virtually every session, I thought, “People in other sectors of publishing ought to know about what the IPTC has to offer them.”
Bill goes on to discuss IPTC’s work with Google on exposing IPTC Photo Metadata in Google search results and the Licensable Images feature in Google Images search, explaining how those in the publishing industry can use those features to find out who owns the copyright on an image they might want to re-use, and how to obtain a license to use it.
He also talks about IPTC’s Media Topics subject taxonomy, and how publishers could use it for press releases, so they can “be sure the terms you use are the ones the news industry itself uses”.
You can view the article on the Publisher’s Weekly website.
Thanks Bill for sharing your thoughts and for promoting the IPTC cause!
IPTC Managing Director Brendan Quinn spoke at the FIBEP World Media Intelligence Congress 2020 on Wednesday 18th November.
FIBEP is the industry body for the “media intelligence” industry, including media monitoring, public relations and marketing organisations.
FIBEP was founded over 65 years ago (so it is even older than IPTC!) and the FIBEP World Media Intelligence Congress has become one of the largest events for communications, public relations, technology, social media monitoring and marketing professionals alike. It brings together communications professionals from around the world to share best practices, discuss industry developments and innovations, present the latest technology and network through a variety of presentations and panel discussions from industry leaders. So it is in many ways similar to IPTC for the technical side of the news industry.
This year’s theme was Exploring and Expanding the Media Intelligence World and the program included a wide range of best practices and topics relevant for media intelligence and communication professionals including social media monitoring, privacy, and data integrity, copyright, the evolution of data consumption, measurement, PR trends, technological developments and future outlooks for communications and media intelligence industries.
Brendan was invited to speak about IPTC’s view of the news ecosystem, particularly with a view to online misinformation and disinformation and how the news industry can work together to combat those problems. Brendan discussed IPTC’s work on trust and credibility, including the content of the recent IPTC webinar on Trust and Credibility.
Questions from the media intelligence community included what individuals could do to avoid misinformation and spreading false news on social media. Brendan’s advice to those who want to learn more about misinformation are in the table:
Educate your teams to “think before you share” on social media |
|
Reuters has put together a course on “manipulated media” including “deep fake” videos: https://www.reuters.com/manipulatedmedia The EU has created a “Think before you share” campaign: https://euvsdisinfo.eu/think-before-you-share/ |
Stay in touch with fact checking organisations |
| Fact checking organisations such as FullFact, PolitiFact, FactCheck.org and Snopes often release information about topics that are often the subject of disinformation and misinformation such as vaccines, elections and conspiracy theories. Many local organisations can be found via the International Fact-Checking Network. |
Thanks very much to FIBEP, especially Romina Gersuni, for inviting us to present. We realised during the preparations for the event that IPTC and FIBEP have a lot in common, so hopefully this will be the first of many collaborations between the two organisations!
 It is with great sadness that we report that Andrew Read passed away suddenly on Sunday 8 November, 2020.
It is with great sadness that we report that Andrew Read passed away suddenly on Sunday 8 November, 2020.
Andy was a passionate member of the IPTC for over 20 years, first through Reuters, then Thomson Reuters and most recently as the BBC’s main representative at the IPTC.
Andy contributed to NewsML-G2 and the IPTC News Architecture, RightsML and other rights-related work, and followed our other work including Photo Metadata and our sports standards. A frequent attendee and speaker at our face-to-face IPTC member meetings, Andy also helped to organise IPTC’s London meetings, including the special Rights Day in 2013 and Rights Management in News day in 2017.
A committed believer in the benefit of industry organisations, he also contributed to the EBU’s metadata activities and organised collaborations with the DPP. Just a few weeks ago at the IPTC Autumn 2020 Meeting, Andy presented his most recent project at the BBC, an adaptation of the Guardian’s open-source digital asset management system for use as the BBC’s main image asset library. He was always making connections between IPTC members and outside organisations, research projects and startups, and loved bringing people together to discuss what technology can bring to the media industry.
Andy will be fondly remembered by all of his IPTC colleagues for his friendly, supportive manner and willingness to help anyone with anything.
When IPTC members get together it often feels like a family reunion, and Andy has been a key part of the IPTC family for the past 20 years. He will be sorely missed.
UPDATE: If you would like to share your memories of Andy or make a donation to his preferred charity, please see the tribute site: https://andyread.muchloved.com/