At the 2024 IPTC Photo Metadata Conference, James Lockman of Adobe’s Digital Media Services division demonstrated the Custom Metadata Panel, a tool that allows users to create their own user interface for editing sets of metadata fields. Since that time, the IPTC has worked with James and his team to make the tool even more useful, supporting the full set of IPTC properties and even enabling IPTC Photo Metadata as the default view in the tool.
Adobe’s Custom Metadata Panel offers the full set of IPTC Photo Metadata properties to users of Adobe Bridge, Photoshop, Premiere Pro and Illustrator.
The Custom Metadata Panel also supports IPTC’s equivalent standard for video content, IPTC Video Metadata Hub. We will add guidance in the future for how it can be used to edit Video Metadata Hub metadata from within Adobe Premiere Pro.
The IPTC thanks James and his team for their work on the panel and for enhancing it so well over the past 12 months to turn it into a real power tool for media managers who want the full power of IPTC Photo Metadata at their fingertips.
Hands-on metadata workshop in Juan les Pins, France in May 2025
IPTC Managing Director Brendan Quinn will run a workshop on Wednesday 14th May showing users how to activate the plugin and how to use it to edit metadata for various purposes. This workshop will take place as part of the IPTC Day at CEPIC 2025, and so will be accessible to attendees of CEPIC 2025 and of the IPTC 2025 Spring Meeting.
Chinese authorities issued guidelines on Friday requiring labels on all artificial intelligence-generated content circulated online, aiming to combat the misuse of AI and the spread of false information.
The regulations, jointly issued by the Cyberspace Administration of China, the Ministry of Industry and Information Technology, the Ministry of Public Security, and the National Radio and Television Administration, will take effect on Sept 1.
A spokesperson for the Cyberspace Administration said the move aims to “put an end to the misuse of AI generative technologies and the spread of false information.”
According to China Daily, “[t]he guidelines stipulate that content generated or synthesized using AI technologies, including texts, images, audios, videos and virtual scenes, must be labeled both visibly and invisibly” (emphasis added by IPTC). This potentially means that IPTC or another form of embedded metadata must be used, in addition to a visible watermark.
“Content identification numbers”
The article goes on to state that “[t]he guideline requires that implicit labels be added to the metadata of generated content files. These labels should include details about the content’s attributes, the service provider’s name or code, and content identification numbers.”
It is not clear from this article which particular identifiers should be used. There is currently no globally-recognised mechanism to identify individual pieces of content by identification numbers, although IPTC Photo Metadata does allow for image identifiers to be included via the Digital Image GUID property and the Video Metadata Hub Video Identifier field, which is based on Dublin Core’s generic dc:identifier property.
According to the article, “Service providers that disseminate content online must verify that the metadata of the content files contain implicit AIGC labels, and that users have declared the content as AI-generated or synthesized. Prominent labels should also be added around the content to inform users.”
Spain’s equivalent legislation on labelling AI-generated content
The Spanish proposal has been approved by the upper house of parliament but must still be approved by the lower house. The legislation will be enforced by the newly-created Spanish AI supervisory agency AESIA.
If companies do not comply with the proposed Spanish legislation, they could incur fines of up to 35 million euros ($38.2 million) or 7% of their global annual turnover.
On behalf of our memberships, IPTC and PLUS respectfully suggest that existing copyright law is sufficient to enable licensing of content to AI platforms. A “fair use” provision does not cover commercial AI training. Existing United States copyright law should be enforced.
IPTC and PLUS Photo Metadata provide a technical means for expressing the creator’s intent as to whether their creations may be used in generative AI training data sets. This takes the form of metadata embedded in image and video files. This solution, in combination with other solutions such as the Text and Data Mining Reservation Protocol, could take the place of a formal licence agreement between parties, making an opt-in approach technically feasible and scalable.
It is true that our technical solutions would also be relevant if the US government chose to implement an opt-out based approach. However, this does not currently protect owners’ rights well due to the routine activity of “metadata stripping” – removing important rights and accessibility metadata that is embedded in media files, in the misguided belief that it will improve site performance. Metadata stripping is performed by many publishers and publishing systems – often inadvertently.
As a result, we can only recommend that the US adopts an opt-in approach. We request that the US government ensures that metadata embedded in media files be declared as a core part of any technical mechanism to declare content owner’s desire for content to be included or excluded from training data sets.
Content creators are a core part of the US economy and have a strong voice. We agree with their position, but we don’t simply come with another voice of complaint: we bring a viable, ready-made technical solution that can be used today to implement true opt-in data mining permissions and reservations.
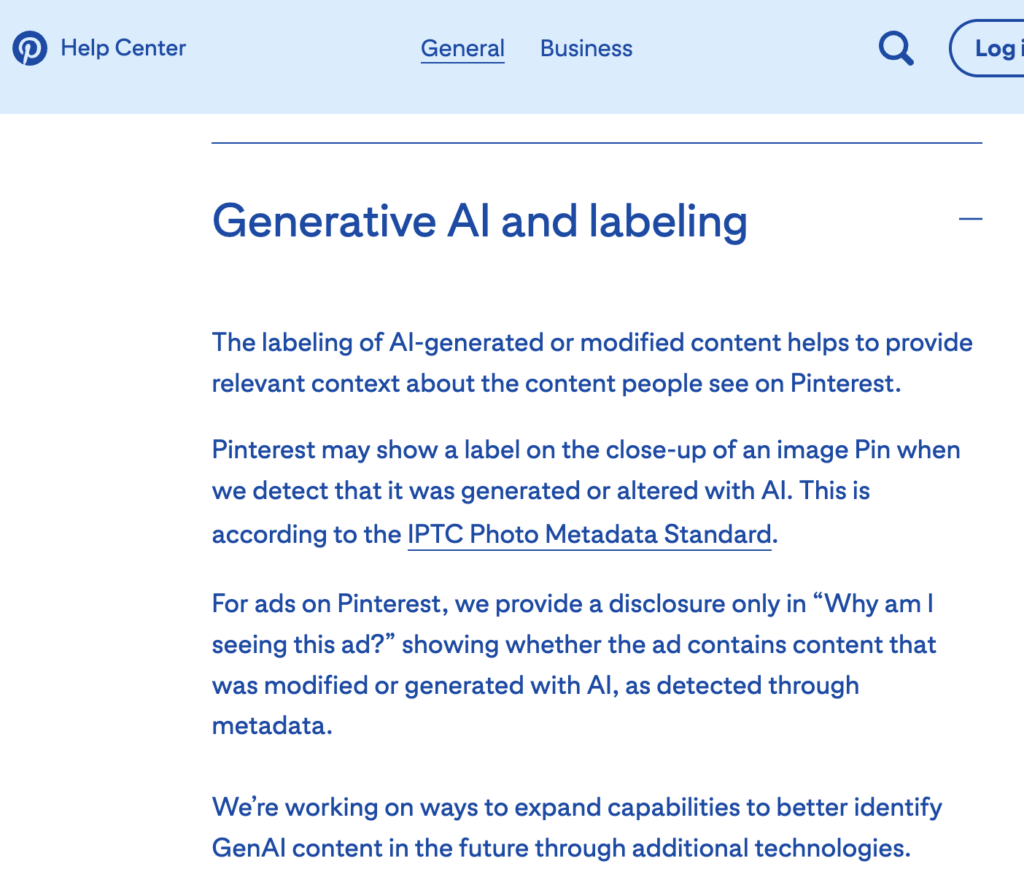
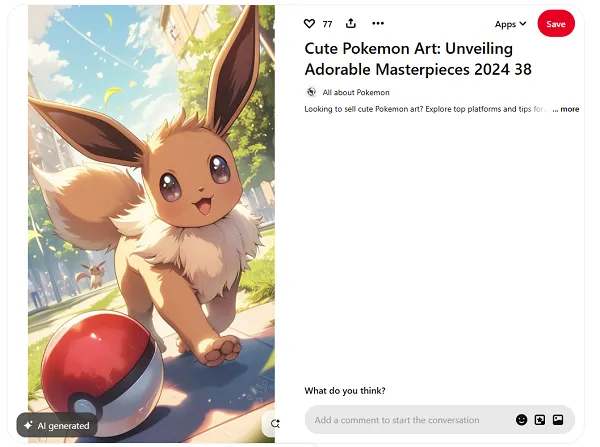
Close-up screenshot of Pinterest’s label for AI-generated content.
As reported in Social Media Today, Pinterest has started using IPTC embedded Photo Metadata to signal when content in “Image Pins” has been generated by AI.
Reports started in February that Pinterest had started labelling AI-generated images. Now it has been confirmed via an official update to Pinterest’s user documentation.
In the Pinterest documentation, a new section has recently been added that describes how it works:
Screenshot of Pinterest’s help pages showing how IPTC metadata is used to signal AI-generated content.
“Pinterest may display a label in the foreground of an image Pin when we detect that it has been generated or modified with AI. This is in accordance with IPTC standard for photo metadata. We’re working on ways to expand our capabilities to better identify GenAI content in the future through additional technologies.”
On behalf of our memberships, IPTC and PLUS respectfully suggest that existing UK copyright law is sufficient to enable licensing of content to AI platforms. There is no “fair use” provision in UK copyright law, and “fair dealing” does not cover commercial AI training. Existing copyright law should be enforced.
IPTC and PLUS Photo Metadata provide a technical means for expressing the creator’s intent as to whether their creations may be used in generative AI training data sets. This takes the form of metadata embedded in image and video files. This solution, in combination with other solutions such as the Text and Data Mining Reservation Protocol, could take the place of a formal licence agreement between parties, making an opt-in approach technically feasible and scalable.
It is true that our technical solutions would also be relevant if the UK government chooses to implement an “opt-out” approach similar to that adopted in the EU. However, an opt-out-based approach does not currently protect owners’ rights well, due to the routine activity of “metadata stripping” – removing important rights and accessibility metadata that is embedded in media files, in the misguided belief that it will improve site performance. Metadata stripping is performed by many publishers and publishing systems – often inadvertently. (See our research on metadata stripping by social media platforms from 2019; very little has changed since then)
As a result, we can only recommend that the UK adopts an opt-in approach. We request that the UK ensures metadata embedded in media files be declared as a core part of any technical mechanism to declare content owner’s desire for content to be included or excluded from training data sets.
During the course of this consultation, it has become clear that content creators are a core part of the UK economy and have a strong voice. We agree with their position, but we don’t simply come with another voice of complaint: we bring a viable, ready-made technical solution that can be used today to implement true opt-in data mining permissions and reservations.
At the IPTC Autumn Meeting, the IPTC Standards Committee voted on a change proposed by the Photo Metadata Working Group, which created version 2024.1 of the IPTC Photo Metadata Standard.
The change is minor but important to some: the definition of the Keywords property now includes the following text:
Keywords to express the subject and other aspects of the content of the image. Keywords may be free text and don’t have to be taken from a controlled vocabulary. Codes from the controlled vocabulary IPTC Subject NewsCodes must go to the “Subject Code” field.
This aligns the property definition with the way in which many photo agencies and photographers were already using the field: to convey aspects such as the lighting or lens effects used, “mood” of the image, dominant colour and more.
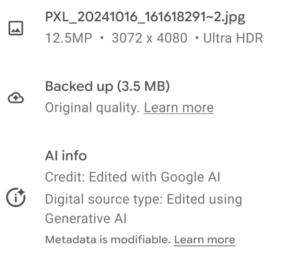
An image created with Google’s Gemini model. The image contains values for the IPTC Photo Metadata properties Digital Source type (trainedAlgorithmnicMedia) and Credit (“Made with Google AI”).
On Thursday, Google announced that it will be extending its usage of AI content labelled using the IPTC Digital Source Type vocabulary.
In a blog post published on Friday, John Fisher, Engineering Director for Google Photos and Google One posted that “[n]ow we’re taking it a step further, making this information visible alongside information like the file name, location and backup status in the Photos app.”
The IPTC has responded to a multi-stakeholder consultation on the recently-agreed European Union Artificial Intelligence Act (EU AI Act).
Although the IPTC is officially based in the UK, many of our members and staff operate from the European Union, and of course all of our members’ content is available in the EU, so it is very important to us that the EU regulates Artificial Intelligence providers in a way that is fair to all parts of the ecosystem, including content rightsholders, AI providers, AI application developers and end users.
In particular, we drew the EU AI Office’s attention to the IPTC Photo Metadata Data Mining property, which enables rightsholders to inform web crawlers and AI training systems of the rightsholders’ agreement as to whether or not the content can be used as part of a training data set for building AI models.
The points made are the same as the ones that we made to the IETF/IAB Workshop consultation: that embedded data mining declarations should be part of the ecosystem of opt-outs, because robots.txt, W3C TDM, C2PA and other solutions are not sufficient for all use cases.
The full consultation text and all public responses will be published by the EU in due course via the consultation home page.
Screenshot of the English version of cipa.jp, the home page of the Camera and Imaging Products Association (CIPA), a consortium of camera manufacturers mostly based in Japan.
The IPTC has signed a liaison agreement with the Japanese camera-makers organisation and creators of the Exif metadata standard, CIPA.
CIPA members include all of the major camera manufacturers, including Nikon, Canon, Sony, Panasonic, FUJIFILM and more. Several software vendors who work with imaging are also members, including Adobe, Apple and Microsoft.
CIPA publishes guidelines and standards for camera manufacturers and imaging software developers. The most important of these from an IPTC point of view is the Exif standard for photographic metadata.
The IPTC and CIPA have had an informal relationship for many years, staying in touch regularly regarding developments in the world of image metadata. Given that the two organisations manage two of the most important standards for embedding metadata into image and video files, it’s important that we keep each other up to date.
Now the relationship has been formalised, meaning that the organisations can request to observe each other’s meetings, exchange members-only information when needed, and share information about forthcoming developments and industry requirements for new work in the field of media metadata and in related areas.
The news has also been announced by CIPA. According to the news post on CIPA’s website, “CIPA has signed a liaison agreement regarding the development of technical standards for metadata attached to captured image with International Press Telecommunications Council (IPTC), the international organization consists of the world’s leading news agencies, publishers and industry vendors.”
Screenshot of the Call for Papers for the IETF IAB workshop on AI Control, to be held in September 2024.
The Internet Architecture Board (IAB), a Committee of the Internet Engineering Task Force (IETF) which decides on standards and protocols that are used to govern the workings of Internet infrastructure, is having a workshop in September on “AI Control”. Discussions will include whether one or more new IETF standards should be defined to govern how AI systems work with Internet content.
Accordingly, the IPTC Photo Metadata Working Group, in association with partner organisation the PLUS Coalition, submitted a position paper discussing in particular the Data Mining property which was added to the IPTC Photo Metadata Standard last year.
In the paper, the IPTC and PLUS set out their position that data mining opt-out information embedded in the metadata of media files is an essential part of any opt-out solution.
Here is a relevant section of the IPTC submission:
We respectfully suggest that Robots.txt alone is not a viable solution. Robots.txt may allow for communication of rights information applicable to all image assets on a website, or within a web directory, or on specific web pages. However, it is not an efficient method for communicating rights information for individual image files published to a web platform or website; as rights information typically varies from image to image, and as the publication of images to websites is increasingly dynamic.
In addition, the use of robots.txt requires that each user agent must be blocked separately, repeating all exclusions for each AI engine crawler robot. As a result, agents can only be blocked retrospectively — after they have already indexed a site once. This requires that publishers must constantly check their server logs, to search for new user agents crawling their data, and to identify and block bad actors.
In contrast, embedding rights declaration metadata directly into image and video files provides media-specific rights information, protecting images and video resources whether the site/page structure is preserved by crawlers — or the image files are scraped and separated from the original page/site. The owner, distributor, or publisher of an image can embed a coded signal into each image file, allowing downstream systems to read the embedded XMP metadata and to use that information to sort/categorise images and to comply with applicable permissions, prohibitions and constraints.
IPTC, PLUS and XMP metadata standards have been widely adopted and are broadly supported by software developers, as well as in use by major news media, search engines, and publishers for exchanging images in a workflow as part of an “operational best practice.” For example, Google Images currently uses a number of the existing IPTC and PLUS properties to signal ownership, licensor contact info and copyright. For details see https://iptc.org/standards/photo-metadata/quick-guide-to-iptc-photo-metadata-and-google-images/
Thanks to David Riecks, Margaret Warren, Michael Steidl from the IPTC Photo Metadata Working Group and to Jeff Sedlik from PLUS for their work on the paper.



{kind=link}

{kind=link}

 The IPTC has responded to a multi-stakeholder consultation on the recently-agreed European Union Artificial Intelligence Act (EU AI Act).
The IPTC has responded to a multi-stakeholder consultation on the recently-agreed European Union Artificial Intelligence Act (EU AI Act).