Categories
Archives

On Thursday, Google announced that it will be extending its usage of AI content labelled using the IPTC Digital Source Type vocabulary.
We have previously shared that Google uses IPTC Photo Metadata to signal AI-generated and AI-edited media, for example labelling images edited with the Magic Eraser tool on Pixel phones.
In a blog post published on Friday, John Fisher, Engineering Director for Google Photos and Google One posted that “[n]ow we’re taking it a step further, making this information visible alongside information like the file name, location and backup status in the Photos app.”
This is based on IPTC’s Digital Source Type vocabulary, which was updated a few weeks ago to include new terms such as “Multi-frame computational capture sampled from real life” and “Screen capture“.
Google already surfaces Digital Source Type information in search results via the “About this image” feature.
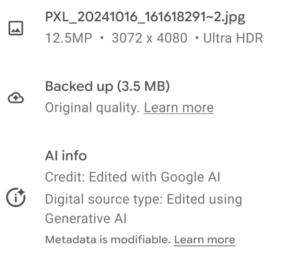
Also, the human-readable label for the term http://cv.iptc.org/newscodes/digitalsourcetype/trainedAlgorithmicMedia was clarified to be “Created using Generative AI” and similarly the label for the term http://cv.iptc.org/newscodes/digitalsourcetype/compositeWithTrainedAlgorithmicMedia was clarified to be “Edited with Generative AI.” These terms are both used by Google.
Last week we held the latest IPTC member meeting, the IPTC Autumn Meeting 2024. With over 80 attendees, it was a great success. We heard from IPTC members and invited guests on new developments in the world of media technology and metadata.
Speakers from Axel Springer, Reuters, Global Media Registry and the EBU
We heard from Axel Springer who have implemented an internal video management system based on IPTC Video Metadata Hub as a metadata model; from Reuters who are basing their live events streaming API on the forthcoming DPP Live Production Exchange (DPP LPX) protocol based on the recently approved ninjs 3.0, from Global Media Registry who are developing a “Unique Media ID” standard to identify media publishers, and from the EBU on the Trusted European Media Data Space (TEMS) project.
Committees and Working Groups
Our new Media Provenance Committee and its Working Groups are working very hard on the details for implementing C2PA in the media industry, including launching the IPTC Origin Verified News Publisher List. We also heard from Tessa Sproule of CBC / Radio Canada on their implementation of C2PA.
Our Standards Committee Working Groups are also working hard, with new developments on all of our standards and three new standard versions, as described below.
New Versions of Sport Schema, ninjs and Photo Metadata
The Standards Committee approved three new standard versions at its meeting on Wednesday 2nd October.
IPTC Sport Schema version 1.1 was approved, adding a Club class so we can model Clubs that contain multiple Teams, even teams that play different sports (who knew that Bayern Munich had a chess team?!). The update also added Associate relationships for individual athletes (such as a coach for a tennis player or a boxer), and facets for sports so we can now declare that an event was a women’s 200 metres breaststroke swimming event using IPTC facets metadata taken from our NewsCodes sports facet vocabulary.
IPTC Photo Metadata Standard version 2024.1 modifies the text of the Keywords property to broaden its scope, matching current industry usage.
IPTC’s JSON standard for news ninjs version 3.0 was also approved, adding requirements for the DPP LPX project including events and planning information, plus renditions support for live event streams. The 3.0 version of the standard also moves property names to “camelCase”, which is the de facto standard for GraphQL and many other JSON-based technologies.
All three updates, plus the NewsML-G2 v2.34_2 errata update, will be released in the coming weeks.
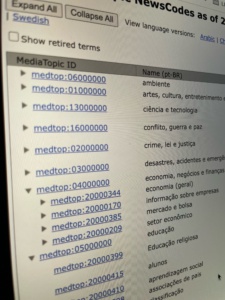
The IPTC NewsCodes Working Group is pleased to announce the latest release of the IPTC NewsCodes, our set of controlled vocabularies for the news industry.
Updates this time span many vocabularies, with the biggest updates to Media Topic and Digital Source Type.
Media Topic updates
Most of the recent work has been in the politics branch.
3 new concepts: by-election, recall election, coalition building
2 retired concepts: political campaigns, church elections
4 modified concept names (in English): voting system, referendum, fundamental rights, football (yes we finally refer to the sport as “football” in en-GB and “soccer” in en-US!)
Modified concept definitions: 22 civil rights, election, voting system, intergovernmental elections, local elections, primary elections, referendum, regional elections, voting, fundamental rights, censorship and freedom of speech, freedom of religion, freedom of the press, human rights, football, political debates, privacy, women’s rights, breaking (breakdance)
1 hierarchy move: fundamental rights has been moved from politics to society.
Also, the Wikidata mapping URIs have all been changed to point to the http:// version of the URI instead of the https:// version. This follows the official Wikidata guidance.
See the official Media Topic vocabulary on the IPTC Controlled Vocabulary server, and an easier-to-navigate tree view. An Excel version of IPTC Media Topics is also available.
Digital Source Type updates
5 new concepts have been added:
- Multi-frame computational capture sampled from real life, intended to cover media recorded by modern cameras and smartphones that may process several captured images together to create the saved media file, without any interaction with the photographer.
- Human-edited media, intended to replace the retired Original media with minor human edits, given that it is subjective to decide what is a “minor” edit.
- Digital creation, intended to replace the retired Digital art so that we can avoid the existential question of “what is art?”
- Screen capture, covering screenshots and screen recordings made on a device
- Composite of elements, as a generic form of the more specific “composite” terms.
2 concepts have been retired: Original media with minor human edits, and Digital art, as explained above.
8 concepts have had their names and definitions modified, while retaining the same machine-readable ID for backwards-compatibility purposes:
- Digital capture sampled from real life (ID: digitalCapture), replacing the previous name “Original digital capture sampled from real life”
- Digitised from a transparent negative (ID: negativeFilm), replacing the previous name “Digitised from a negative on film”
- Digitised from a transparent positive (ID: positiveFilm), replacing the previous name “Digitised from a positive on film”
- Digitised from a non-transparent medium (ID: print), replacing the previous name “Digitised from a print on non-transparent medium”
- Edited using Generative AI (ID: compositeWithTrainedAlgorithmicMedia), replacing the previous name “Composite with Trained algorithmic media”
- Algorithmically-altered media (ID: algorithmicallyEnhanced), replacing the previous name “Algorithmically Enhanced”
- Created using Generative AI (ID: trainedAlgorithmicMedia), replacing the previous name “Trained Algorithmic Media”
- Virtual event recording (ID: virtualRecording), replacing the previous name “Virtual recording”
Our thanks go to IPTC representatives and experts from Partnership on AI, Google, Adobe, C2PA, CIPA and many others on making these updates to our vocabulary, which is now widely used to identify Generative AI content.
Updates to other NewsCodes vocabularies
Alternative Identifier Role (altidrole)
- Vocabulary’s name changed to fix a spelling mistake.
- New concept: IPTC Video Metadata Hub ID (altidrole:vmhVideoId)
Event Occur Status (eocstat)
- Fix spelling mistake “occurence” -> “occurrence” throughout.
Golf Shot (spgolshot)
- New concept: Chip (spgolshot:chip)
Rights Property (rightsprop)
- New concept: Copyright Year (rightsprop:copyrightyear)
- 4 modified definitions: Minor Model Age Disclosure, Model Release Id, Model Release Status, Property Release Status.
Sports Concept (spct)
- New concept: Recurring Competition (spct:recurring-competition)
- New concept: Governing Body (spct:governing-body)

Over a weekend in mid-September every year, Europe’s (and increasingly the world’s) broadcast media industry gets together at IBC, the International Broadcasting Convention.
IPTC members were well represented at this year’s event:
- IPTC Startup Members Factiverse were out in full force promoting their automated fact-checking solution, which can now be integrated into any media asset management tool via an API.
- Fellow Startup Members HAND – Human & Digital presented their work on an IBC Accelerator project looking at called “Digital Replicas and Talent ID: Provenance, Verification and New Automated Workflows” along with Paramount, ITV, EZDRM and The Scan Truck.
- Moments Lab (previously known as Newsbridge) presented their video segmentation and annotation systems on a very well attended stand.
- The BBC featured in many sessions. Judy Parnall, lead of IPTC’s Media Provenance Committee’s Advocacy and Education Working Group, presented two papers, both concerning the BBC’s work with C2PA, leading to the BBC’s work with Project Origin and the IPTC Media Provenance Committee. One was presented along with new IPTC Individual Member, John Simmons.
- Newly upgraded to IPTC Voting Members, he European Broadcasting Union (EBU) had a very popular stand demonstrating several accelerator projects, including the best demonstrator of C2PA we have yet seen: an end-to-end workflow from a Content Credential-enabled Leica camera, along with AI-generated content from Adobe Firefly, edited in Adobe Premiere Pro, and published using WDR’s publisher certificate which is on the new IPTC Verified News Publisher list. IPTC Managing Director Brendan Quinn gave a short presentation at the EBU stand’s C2PA meet-up event, explaining the IPTC’s recently-announced work on the Verified News Publisher List. Other speakers at the meet-up were Kenneth from WDR, Andy Parsons from Adobe and the Content Authenticity Initiative, Go Ohtake of NHK (who demonstrated a prototype C2PA application running on a Web TV platform), and project lead Lucille Verbaere of the EBU.
- Media Cluster Norway (previously known as Media City Bergen) ran an awesome breakfast event about Project Reynir, their project to make Norway’s media ecosystem a pathfinder for C2PA technology from one end of the production workflow to the other, including vendors such as VizRT and Wolftech, Norwegian news agency NTB and more.
- Liaison partner The DPP had a great reception where the industry came together to discuss future projects including the Live Production Exchange project on which IPTC is assisting via our News in JSON (ninjs) Working Group.
- Of course Adobe and Google both had enormous and well attended stands, Associated Press and Reuters were receiving a lot of attention (particular after Reuters’ acquisition of digital content management company Imagen last year). Arqiva and Broadcast Solutions were also represented with well-attended stands.
From what we could see, all IPTC members who attended the convention had a very successful time, and we look forward to many future successful events.
We hope to see all of you again at the IPTC Autumn Meeting next week!
 The IPTC has responded to a multi-stakeholder consultation on the recently-agreed European Union Artificial Intelligence Act (EU AI Act).
The IPTC has responded to a multi-stakeholder consultation on the recently-agreed European Union Artificial Intelligence Act (EU AI Act).
Although the IPTC is officially based in the UK, many of our members and staff operate from the European Union, and of course all of our members’ content is available in the EU, so it is very important to us that the EU regulates Artificial Intelligence providers in a way that is fair to all parts of the ecosystem, including content rightsholders, AI providers, AI application developers and end users.
In particular, we drew the EU AI Office’s attention to the IPTC Photo Metadata Data Mining property, which enables rightsholders to inform web crawlers and AI training systems of the rightsholders’ agreement as to whether or not the content can be used as part of a training data set for building AI models.
The points made are the same as the ones that we made to the IETF/IAB Workshop consultation: that embedded data mining declarations should be part of the ecosystem of opt-outs, because robots.txt, W3C TDM, C2PA and other solutions are not sufficient for all use cases.
The full consultation text and all public responses will be published by the EU in due course via the consultation home page.
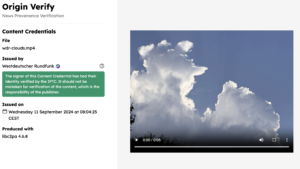
AMSTERDAM, 13 September 2024 — The International Press Telecommunications Council (IPTC) has announced Phase 1 of the IPTC Verified News Publishers List at the International Broadcast Convention (IBC).
The list uses C2PA technology to enable verified provenance for the news media industry. News outlets apply for a certificate from a partner Certificate Authority (currently Truepic), with the IPTC verifying the identity of the publisher. The certificate is then used by the news outlet to sign content, in accordance with the C2PA specification’s handling of “additional trust anchor stores”. This means that the news publisher is the signer of the content. This is a key requirement for many media outlets.
Currently the BBC (UK), CBC / Radio Canada (Canada) and broadcaster WDR (Germany) have certificates on the Verified News Publishers List. Many more publishers and broadcasters are currently in the process of obtaining a certificate. To register your interest as a news publisher, please fill out the Verified News Publisher expression of interest form.
To make the process of verifying and approving certificate requests transparent and accountable, the IPTC has released a set of policies for issuing Verified News Publisher certificates covering Phase 1 of the project. The process includes a “fast track” process for media organisations that are already well known to IPTC, and also a self-certification track. The policies were approved by the IPTC membership at a recent meeting of the IPTC Media Provenance Committee.
Verifying publisher identity, not trustworthiness
Note: as we have always made clear, the IPTC is making no claims about the truth or trustworthiness of content published by news publishers on the IPTC Verified News Publisher List. We simply verify that the publisher is “who they say they are”, and then the signature will verify that the content was published by that publisher, and has not been tampered with since the point of publishing.
We make it clear in the governance policies that a certificate can be revoked if the certificate’s private key has been compromised in some way, but we will not revoke certificates for editorial reasons.
Online verifier tool
The IPTC has worked with the BBC to launch a simple Verified News Publisher content verifier tool hosted at https://originverify.iptc.org. The tool displays a special indicator when content has been signed by an organisation whose certificate is on the Verified News Publisher list. The IPTC has also published a set of Verified News Publisher sample content that can be used with the verifier to demonstrate the process in action.
Sharing best practices, resources and knowledge among news publishers
For IPTC members, the Media Provenance Committee has created an internal members-only wiki detailing best practices and lessons learned while implementing C2PA and the Verified News Publisher List at broadcasters and publishers. Information on the wiki includes technical details on how to generate a certificate signing request to obtain a certificate, how to sign content with open-source and commercial tools, how to deal with publishing and distribution technology such as streaming servers and content delivery networks, and how to add metadata to C2PA assertions embedded in media content.
The Committee has also created a public-facing area of the IPTC site describing IPTC’s work in the area of Media Provenance, helping news publishers to get up to speed and understand how C2PA technology works and how it can be implemented in publishing workflows.
Other IPTC and Media Provenance-related events at IBC this weekend:
- Judy Parnall (BBC), Lead of the IPTC Media Provenance Advocacy Working Group, spoke on a panel on “Content Tracing and Provenance” this morning (Friday) at the AI Zone.
- Judy is also presenting a paper at the IBC Conference on Saturday 14 September: Provenance: What can we Trust?, along with IPTC Individual Member John Simmons.
- Combating disinformation in News: A critical year for democracies at the IPTC Conference on Saturday. Laura Ellis (BBC) is on the panel along with representatives from CBS and GLOBO.
- On Sunday 15 September, Judy presents IBC’s Accelerator Project “Design Your Weapons in Fight Against Disinformation” on the IBC Innovation Stage, along with tech leaders from CBS, Associated Press and ITN.
The IPTC is excited to announce that the IPTC Autumn Meeting 2024 is fast approaching, taking place from Monday September 30 to Wednesday October 2. This year’s event will be held virtually, providing IPTC members with the opportunity to stay informed and connected with industry leaders, no matter their location.

The Autumn Meeting will focus on the latest innovations in news metadata, standards, and tools that are shaping the future of digital content and journalism.
One of the key highlights of the meeting will be presentations by IPTC’s various Working Groups. These sessions will dive deep into advancements in metadata standards, addressing challenges like improving interoperability and adapting to the rapid rise of artificial intelligence in media.
Another focal point of the event will be updates on how new and existing IPTC standards like NewsML-G2, ninjs, Video Metadata Hub are helping news and media organisations to streamline the exchange of information. These tools play a critical role in ensuring that news content is delivered in a trusted and structured manner across platforms.
In addition to the technical presentations, the meeting will also feature case studies from IPTC member organizations. These will explore innovative uses of IPTC standards, such as the DPP Live Production Exchange project and the TEMS Trusted European Media Data Space.
The new IPTC Media Provenance Committee will come together to present to IPTC members recent activity in the working groups on Governance, Best Practices and Advocacy & Education around implementing media provenance technologies such as C2PA in newsrooms and media publishing workflows. We will hear from members such as CBC / Radio Canada on how these standards are helping media companies tackle issues like misinformation and content verification.
The event also includes the official IPTC Annual General Meeting (AGM), where Voting Members will participate in elections for the IPTC Board of Directors and vote on important decisions regarding the management of IPTC. The AGM is a great opportunity for members to shape the future direction of IPTC and its work on evolving industry standards.
The IPTC Standards Committee will meet to vote on proposed new standards from several working groups, including new versions of ninjs, NewsML-G2 and IPTC Sport Schema.
As always, registration for the IPTC Autumn Meeting is free for IPTC members. It’s an unmissable chance to engage with cutting-edge developments in the industry and collaborate with fellow professionals committed to improving news and media standards worldwide.
For more information and to register, visit IPTC Autumn Meeting 2024.
The IPTC has signed a liaison agreement with the Japanese camera-makers organisation and creators of the Exif metadata standard, CIPA.
CIPA members include all of the major camera manufacturers, including Nikon, Canon, Sony, Panasonic, FUJIFILM and more. Several software vendors who work with imaging are also members, including Adobe, Apple and Microsoft.
CIPA publishes guidelines and standards for camera manufacturers and imaging software developers. The most important of these from an IPTC point of view is the Exif standard for photographic metadata.
The IPTC and CIPA have had an informal relationship for many years, staying in touch regularly regarding developments in the world of image metadata. Given that the two organisations manage two of the most important standards for embedding metadata into image and video files, it’s important that we keep each other up to date.
Now the relationship has been formalised, meaning that the organisations can request to observe each other’s meetings, exchange members-only information when needed, and share information about forthcoming developments and industry requirements for new work in the field of media metadata and in related areas.
The news has also been announced by CIPA. According to the news post on CIPA’s website, “CIPA has signed a liaison agreement regarding the development of technical standards for metadata attached to captured image with International Press Telecommunications Council (IPTC), the international organization consists of the world’s leading news agencies, publishers and industry vendors.”

The Internet Architecture Board (IAB), a Committee of the Internet Engineering Task Force (IETF) which decides on standards and protocols that are used to govern the workings of Internet infrastructure, is having a workshop in September on “AI Control”. Discussions will include whether one or more new IETF standards should be defined to govern how AI systems work with Internet content.
As part of the lead-up to this workshop, the IAB and IETF have put out a call for position papers on AI opt-out techniques.
Accordingly, the IPTC Photo Metadata Working Group, in association with partner organisation the PLUS Coalition, submitted a position paper discussing in particular the Data Mining property which was added to the IPTC Photo Metadata Standard last year.
In the paper, the IPTC and PLUS set out their position that data mining opt-out information embedded in the metadata of media files is an essential part of any opt-out solution.
Here is a relevant section of the IPTC submission:
We respectfully suggest that Robots.txt alone is not a viable solution. Robots.txt may allow for communication of rights information applicable to all image assets on a website, or within a web directory, or on specific web pages. However, it is not an efficient method for communicating rights information for individual image files published to a web platform or website; as rights information typically varies from image to image, and as the publication of images to websites is increasingly dynamic.
In addition, the use of robots.txt requires that each user agent must be blocked separately, repeating all exclusions for each AI engine crawler robot. As a result, agents can only be blocked retrospectively — after they have already indexed a site once. This requires that publishers must constantly check their server logs, to search for new user agents crawling their data, and to identify and block bad actors.
In contrast, embedding rights declaration metadata directly into image and video files provides media-specific rights information, protecting images and video resources whether the site/page structure is preserved by crawlers — or the image files are scraped and separated from the original page/site. The owner, distributor, or publisher of an image can embed a coded signal into each image file, allowing downstream systems to read the embedded XMP metadata and to use that information to sort/categorise images and to comply with applicable permissions, prohibitions and constraints.
IPTC, PLUS and XMP metadata standards have been widely adopted and are broadly supported by software developers, as well as in use by major news media, search engines, and publishers for exchanging images in a workflow as part of an “operational best practice.” For example, Google Images currently uses a number of the existing IPTC and PLUS properties to signal ownership, licensor contact info and copyright. For details see https://iptc.org/standards/photo-metadata/quick-guide-to-iptc-photo-metadata-and-google-images/
The paper in PDF format can be downloaded from the IPTC site.
Thanks to David Riecks, Margaret Warren, Michael Steidl from the IPTC Photo Metadata Working Group and to Jeff Sedlik from PLUS for their work on the paper.
 The IPTC NewsCodes Working Group has released the latest update to IPTC NewsCodes vocabularies.
The IPTC NewsCodes Working Group has released the latest update to IPTC NewsCodes vocabularies.
The changes are quite minor this time, but we still recommend that users stay up to date with the latest version.
Changes to Media Topics vocabulary
Our main subject classification taxonomy, IPTC Media Topics, has seen the following updates:
1 new concept
- breaking (breakdance) (added earlier this year in time for the Paris 2024 Olympics)
1 retired concept
- missing in action (duplicate term added in error in the 2024 Q1 update. The existing term missing in action medtop:20000061 was moved to replace the newer term))
32 modified definitions
These changes mostly correct spelling errors in en-GB where US spellings had slipped in, such as changing “behavior” to “behaviour” for en-GB:
wireless technology, tobacco and nicotine, economic trends and indicators, international economic institution, stocks and securities, adult and continuing education, upper secondary education, social learning, medical condition, Confucianism, relations between religion and government, road cycling, competitive dancing, sexual misconduct, developmental disorder, fraternal and community group, cyber warfare, public transport, taxi and ride-hailing, shared transport, business reporting and performance, business restructuring, commercial real estate, residential real estate, podcast, financial service, business service, news industry, diversity, equity and inclusion, sustainability, profit sharing, breaking (breakdance).
As usual, the Media Topics vocabularies can be viewed in the following ways:
- In a collapsible tree view
- As a downloadable Excel spreadsheet
- On one page on the cv.iptc.org server
- In machine readable formats such as RDF/XML and Turtle using the SKOS vocabulary format: see the cv.iptc.org guidelines document for more detail.
Updates to other vocabularies
Horse Position (sphorposition)
New term “trainer” added to https://cv.iptc.org/newscodes/sphorposition. This term is needed by IPTC Sport Schema.
For more information on IPTC NewsCodes in general, please see the IPTC NewsCodes Guidelines.