Categories
Archives

With less than two weeks to go, we are pleased to announce the full agenda for the IPTC Spring Meeting 2022.
The IPTC Spring Meeting 2022 will be held virtually from Monday May 16th to Wednesday May 18th, from 1300 – 1800 UTC each day.
IPTC member representatives can view the full agenda and register at https://iptc.org/moz/events/spring-meeting-2022/
Highlights of the meeting include:
- Updates from all IPTC Working Groups, including Photo Metadata, Video Metadata, NewsCodes, Sports Content, NewsML-G2 and News in JSON
- Updates from the IPTC PR Committee and the IPTC Standards Committee, including votes on proposed new versions of IPTC standards
- Invited presentations from:
- United Robots, presenting their “robot journalism” system built for media companies
- Axate‘s micropayments system for publishers
- Kairntech presenting their content classification system used by Agence France-Presse among others
- Bria.ai‘s image generation and manipulation API backed with cutting-edge artificial intelligence
- Consultant Henrik de Gyor speaking on the latest developments in synthetic media
- Laurent Le Meur from EDRLab discussing the W3C Text and Data Mining Community Group’s recommendation for a Text and Data Mining Reservation Protocol
- Member presentations:
- Recently-joined IPTC members will have a chance to introduce themselves and their organisations to the IPTC membership
- The New York Times presenting their “Papertrail” system used to target advertising based on content metadata
- Margaret Warren from ImageSnippets discussing what she learned when creating NFTs from her artwork
- Member discussions:
- IPTC members will be discussing how we might be able to simplify rights management with a cut-down basic set of rights assertions, possibly creating a simpler alternative to RightsML
- IPTC members will also be discussing the News Architecture and how we can better utilise the key data model that underlies both NewsML-G2 and ninjs
- and more!
Attendance to the 2022 IPTC Spring Meeting is free for all delegates and member experts from IPTC member organisations.
Invited speakers are welcome to attend the day on which they are speaking.
IPTC members will be appearing at imaging.org’s Imaging Science and Technology DigiTIPS 2022 meeting series tomorrow, April 26.
The session description is as follows:
Unmuting Your ‘Silent Images’ with Photo Metadata
Caroline Desrosiers, founder and CEO, Scribely
David Riecks and Michael Steidl, IPTC Photo Metadata Working GroupAbstract: Learn how embedded photo metadata can aid in a data-driven workflow from capture to publish. Discover what details exist in your images; and learn how you can affix additional information so that you and others can manage your collection of images. See how you can embed info to automatically fill in “Alt Text” to images shown on your website. Explore how you can test your metadata workflow to maximize interoperability.”
Registration is still open. You can register at https://www.imaging.org/Site/IST/Conferences/DigiTIPS/DigiTIPS_Home.aspx?Entry_CCO=3#Entry_CCO

{kind=link}
A hot topic in media circles these days is “synthetic media”. That is, media that was created either partly or fully by a computer. Usually the term is used to describe content created either partly or wholly by AI algorithms.
IPTC’s Video Metadata Working Group has been looking at the topic recently and we concluded that it would be useful to have a way to describe exactly what type of content a particular media item is. Is it a raw, unmodified photograph, video or audio recording? Is it a collage of existing photos, or a mix of synthetic and captured content? Was it created using software trained on a set of sample images or videos, or is it purely created by an algorithm?
We have an existing vocabulary that suits some of this need: Digital Source Type. This vocabulary was originally created to be able to describe the way in which an image was scanned into a computer, but it also represented software-created images at a high level. So we set about expanding and modifying that vocabulary to cover more detail and more specific use cases.
It is important to note that we are only describing the way a media object has been created: we are not making any statements about the intent of the user (or the machine) in creating the content. So we deliberately don’t have a term “deepfake”, but we do have “trainedAlgorithmicMedia” which would be the term used to describe a piece of content that was created by an AI algorithm such as a Generative Adversarial Network (GAN).
Here are the terms we propose to include in the new version of the Digital Source Type vocabulary. (New terms and definition changes are marked in bold text. Existing terms are included in the list for clarity.)
| Term ID | digitalCapture |
| Term name | Original digital capture sampled from real life |
| Term description | The digital media is captured from a real-life source using a digital camera or digital recording device |
| Examples | Digital photo or video taken using a digital SLR or smartphone camera |
| Term ID | negativeFilm |
| Term name | Digitised from a negative on film |
| Term description | The digital media was digitised from a negative on film on any other transparent medium |
| Examples | Film scanned from a moving image negative |
| Term ID | positiveFilm |
| Term name | Digitised from a positive on film |
| Term description | The digital media was digitised from a positive on a transparency or any other transparent medium |
| Examples | Digital photo scanned from a photographic positive |
| Term ID | |
| Term name | Digitised from a print on non-transparent medium |
| Term description | The digital image was digitised from an image printed on a non-transparent medium |
| Examples | Digital photo scanned from a photographic print |
| Term ID | humanEdited |
| Term name | Original media with minor human edits |
| Term description | Minor augmentation or correction by a human, such as a digitally-retouched photo used in a magazine |
| Examples | Video camera recording, manipulated digitally by a human editor |
| Term ID | compositeCapture |
| Term name | Composite of captured elements |
| Term description | Mix or composite of several elements that are all captures of real life |
| Examples | * A composite image created by a digital artist in Photoshop based on several source images * Edited sequence or composite of video shots |
| Term ID | algorithmicallyEnhanced |
| Term name | Algorithmically-enhanced media |
| Term description | Minor augmentation or correction by algorithm |
| Examples | A photo that has been digitally enhanced using a mechanism such as Google Photos’ “de-noise” feature |
| Term ID | dataDrivenMedia |
| Term name | Data-driven media |
| Term description | Digital media representation of data via human programming or creativity |
| Examples | A representation of a distant galaxy created by analysing the outputs of a deep-space telescope (as opposed to a regular camera) An infographic created using a computer drawing tool such as Adobe Illustrator or AutoCAD |
| Term ID | digitalArt |
| Term name | Digital art |
| Term description | Media created by a human using digital tools |
| Examples | * A cartoon drawn by an artist into a digital tool using a digital pencil, a tablet and a drawing package such as Procreate or Affinity Designer * A scene from a film/movie created using Computer Graphic Imagery (CGI) * Electronic music composition using purely synthesised sounds |
| Term ID | virtualRecording |
| Term name | Virtual recording |
| Term description | Live recording of virtual event based on synthetic and optionally captured elements |
| Examples | * A recording of a computer-generated sequence, e.g. from a video game * A recording of a Zoom meeting |
| Term ID | compositeSynthetic |
| Term name | Composite including synthetic elements |
| Term description | Mix or composite of several elements, at least one of which is synthetic |
| Examples | * Movie production using a combination of live-action and CGI content, e.g. using Unreal engine to generate backgrounds * A capture of an augmented reality interaction with computer imagery superimposed on a camera video, e.g. someone playing Pokemon Go |
| Term ID | trainedAlgorithmicMedia |
| Term name | Trained algorithmic media |
| Term description | Digital media created algorithmically using a model derived from sampled content |
| Examples | * Image based on deep learning from a series of reference examples * A “speech-to-speech” generated audio or “deepfake” video using a combination of a real actor and an AI model * “Text-to-image” using a text input to feed an algorithm that creates a synthetic image |
| Term ID | algorithmicMedia |
| Term name | Algorithmic media |
| Term description | Media created purely by an algorithm not based on any sampled training data, e.g. an image created by software using a mathematical formula |
| Examples | * A purely computer-generated image such as a pattern of pixels generated mathematically e.g. a Mandelbrot set or fractal diagram * A purely computer-generated moving image such as a pattern of pixels generated mathematically |
We propose that the following term, which exists in the current DigitalSourceType CV, be retired:
| Term ID | RETIRE: softwareImage |
| Term name | Created by software |
| Term description | The digital image was created by computer software |
| Note | We propose that trainedAlgorithmicMedia or algorithmnicMedia be used instead of this term. |
We welcome all feedback from across the industry to these proposed terms.
Please contact Brendan Quinn, IPTC Managing Director at mdirector@iptc.org use the IPTC Contact Us form to send your feedback.
Anyone who has managed photo metadata can attest that it is often difficult to know which metadata properties to use for different purposes. It is especially tricky to know how to tag consistently across different metadata standards. For example, how should a copyright notice be expressed in Exif, IPTC Photo Metadata and schema.org metadata?
For software vendors wanting to build accurate mapping into their tools to make life easier for their customers, it’s no easier. For a while, a document created by a consortium of vendors known as the Metadata Working Group solved some of the problems, but the MWG Guidelines are no longer available online.
To solve this problem, the IPTC collaborated with Exif experts at CIPA, the camera products industry group that maintains the Exif standard. We also spoke with the team behind schema.org. Based on these conversations, we created a document that describes how to map properties between these formats. The aim is to remove any ambiguity regarding which IPTC Photo Metadata properties are semantically equivalent to Exif tags and schema.org properties.
Generally, Exif tags and IPTC Photo Metadata properties represent different things: Exif mainly represents the technical data around capturing an image, while IPTC focuses on describing the image and its administrative and rights metadata, and schema.org covers expressing metadata in a web page. However, quite a few properties are shared by all standards, such as who is the Creator of the image, the free-text description of what the image shows, or the date when the image was taken. Therefore it is highly recommended to have the same value in the corresponding fields of the different standards.
The IPTC Photo Metadata Mapping Guidelines outlines the 17 IPTC Photo Metadata Standard properties with corresponding fields in Exif and/or Schema.org. Further short textual notes help to implement these mappings correctly.
The intended audience of the document is those managing the use of photo metadata in businesses and the makers of software that handles photo metadata.The IPTC Photo Metadata Mapping Guidelines document can be accessed on the iptc.org website. We encourage IPTC members to provide feedback through the usual channels, and non-members to respond with feedback and questions on the public IPTC Photo Metadata email discussion group.
Next Thursday 10th March, IPTC members will be presenting a webinar on IPTC Media Topics and Wikidata. It will be held in association with the European Broadcasting Union as part of the EBU Wikidata Workshop.

The webinar is part of our series of “member-to-member” webinars, but as this is a special event in conjunction with EBU, attendance is open to the public.
The IPTC component of the workshop features Jennifer Parrucci of The New York Times, lead of the IPTC NewsCodes Working Group which manages the Media Topics vocabulary, and Managing Director of IPTC Brendan Quinn, introducing Media Topics and how they can be used with Wikidata. Then Tor Kristian Flage of Norwegian agency NTB and Gustav Carlberg of vendor and IPTC member iMatrics will present on their recent project to integrate IPTC Media Topics and Wikidata into their newsroom workflow.
Other speakers at the workshop on March 10th include France TV, RAI Italy, YLE Finland, Gruppo RES, Media Press and Perfect Memory.
Register to attend the full workshop (including the IPTC webinar) for free here.
The IPTC has an ongoing project to the news and media industry deal with content credibility and provenance. As part of this, we have started working with Project Origin, a consortium of news and technology organisations who have come together to fight misinformation through the use of content provenance technologies.
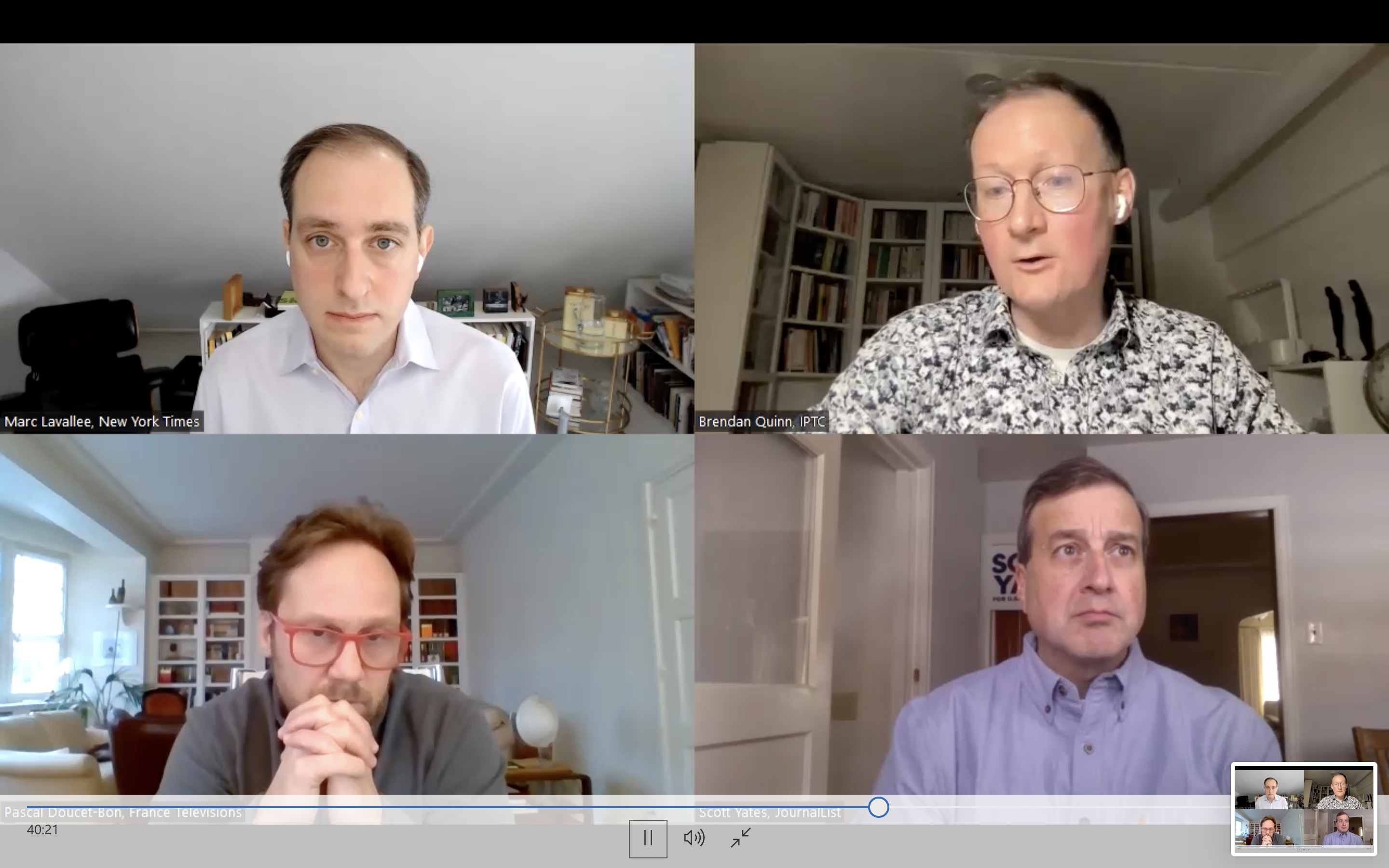
On Tuesday 22nd February, Managing Director of IPTC Brendan Quinn spoke on a panel at an invite-only Executive Briefing event attended by leaders from news organisations around the world.
Other speakers at the event included Marc Lavallee, Head of R&D for The New York Times, Pascale Doucet of France Télévision, Eric Horvitz of Microsoft Research, Andy Parsons of Adobe, and Laura Ellis, Jamie Angus and Jatin Aythora of the BBC.
The event marks the beginning of the next phase of the industry’s work on content credibility. C2PA has now delivered the 1.0 version of its spec, so the next phase of the work is for the news industry to get together to create best practices around implementing it in news workflows.
IPTC and Project Origin will be working together with stakeholders from all parts of the news industry to establish guidelines for making provenance work in a practical way across the entire news ecosystem.
We have just released a small update to the Media Topics contr olled vocabulary for news and media content. The changes support the Winter Olympics which starts this week.
olled vocabulary for news and media content. The changes support the Winter Olympics which starts this week.
The changes are:
- The definition of bobsleigh (medtop:20000854) was changed to reflect the fact that bobsleigh now offers a one-person version (which is incidentally referred to as “monobob”). The new definition is: One, two or four people racing down a course in a sled that consists of a main hull, a frame, two axles and sets of runners. The total time of all heats in a competition is added together to determine the winner.
- Similarly, the definition of freestyle skiing (medtop:20001058) was changed to reflect new events this year. The new definition is: Skiing competitions which, in contrast to alpine skiing, incorporate acrobatic moves and jumps. Events include aerials, halfpipe, slopestyle, ski cross, moguls and big air.
We also took the opportunity to add a term which was recently suggested by ABC Australia and Fourth Estate in the US:
- tsunami (medtop:20001353), child of medtop:20000151 natural disaster – High and powerful ocean waves caused by an underwater land disturbance, such as an earthquake or volcanic eruption, known to cause significant damage and loss when they hit land
We would like to thank to all Media Topics users and maintainers for their feedback and support.
Welcome to 2022! We thought a good way to kick off the new year would be to share the text of the speech given by our new Standards Committee Chair, Paul Harman of Bloomberg, at the IPTC Standards Committee meeting on 20 October 2021. In this piece, Paul does a particularly good job of explaining IPTC’s mission and calls on all IPTC members to participate in our standards work.
The IPTC was founded to secure fair access to modern telecommunications infrastructure. Using satellite technology would enable news providers and distributors to report from conflict zones, or from the other side of the world, at greater speed and with less risk of disruption from regional disputes or actions which could affect landline alternatives.
Once such access was secured, they had to decide how to use it. News agencies required technical standards for information interchange, and that’s what IPTC set out to provide, in the name of interoperability. It’s a remit we continue to carry out today. Organisations both inside the news technology arena, and outside, look to IPTC for guidance on media metadata; IPTC is perhaps best known for the Photo Metadata standards that were incorporated into Adobe products, and from there across the photo ecosystem.
Today we face a different problem: not a lack of standards, but an over-abundance of them; and alongside that, regular misuse – or lack of use – of the standards we actually have. As the popular XKCD comic highlights, the solution isn’t to create “one new standard to rule them all”, as this just perpetuates the problem. Increasingly the activities of our Working Groups are about documenting how to use the standards – IPTC and external – that already exist, and how to map between them.

To do this, we need an understanding of what news is, and what each step in the workflow is trying to achieve. We must step away from the bits and bytes of transfer protocols, and instead examine the semantics of news – define an abstract data model representing the concepts in news collection, curation, distribution and feedback, and how those concepts inter-relate – separating the meaning of the metadata from the mechanics of how they are expressed. Only then can we successfully reflect that understanding back into whatever formats our members can use based on the constraints they are operating within.
New protocols and representations evolve all the time: SGML, XML, JSON, YAML, Turtle, Avro, protobuf… they are just serialisation formats. It shouldn’t have to matter whether you choose schema.org or rNews or RDFa or microdata or JSON-LD to embed metadata into HTML; what matters is a consistency of meaning, regardless of the mechanism.
Our Working Groups are already doing this, to a greater or lesser extent. The Video Metadata Hub is precisely an abstract model that defines serialisations into existing formats. The Photo Metadata Standard grew out of IIM and XMP work and describes the serialisations into, and necessary synchronisations between, current and future photo metadata standards. The News in JSON Working Group is attempting to map the same data model across JSON, Avro and Protocol Buffers, based on the News Architecture which was conceived as a data model but quickly became defined via its expression in XML, namely NewsML-G2. The Sports Content Working Group is currently working on taking the semantics from SportsML and SportsJS and re-expressing them in terms of RDF. For machine-readable rights, IPTC worked with the W3C on ODRL and used it as the basis for RightsML. And the NewsCodes Working Group is taking the Media Topics scheme and mapping it to Wikidata, which could be used as a lingua franca between any classification systems.
But this work is far from trivial, and requires continuous effort. IPTC is a member organisation, and it is through the time volunteered by delegates and their organisations that the work progresses. IPTC has but one member of staff – Brendan – who does a huge amount of work across all of our standards, but he also needs to run the business. Therefore we need your help to create and maintain our standards for the benefit of your businesses. Please join the working group sessions, or recommend somebody from your organisation to get involved, in the areas of interest to you and your organisation.
In particular, we have heard again at this meeting the need for machine-readable rights. The standard exists, in the form of RightsML. What it needs now is tooling to support the standard, a user guide with use cases, and potentially some how-tos or templates for typical use cases – similar maybe to Creative Commons licences – that cover the majority of our use cases. Most meetings, we hear from members on how crucial machine-readable rights are to effective workflows in their business, but the Working Group is currently without a lead. If you work at a member organisation who would benefit, please consider volunteering to participate in this group.
I would remind the Working Groups that IPTC has provision in the budget for technical authoring and software development – so I would encourage you to propose to the Board how you might use that. We can then decide where to spend, and also use this as input on future budgets. Let the Board know how we can help and support you.
I’d like to close by thanking the Working Group Leads, and their organisations, for so generously giving of their time: Dave, Jennifer, Johan, Paul, Michael and Pam. Special thanks to David Riecks for agreeing to co-chair the Photo Metadata group, and to Brendan for his support and development work on tools such as the Generators and Unit Testing frameworks. Thanks also to Kelvin Holland, our technical author, for his work on the NewsML-G2 Specification and User Guide. And thanks to the members of all of the working groups for their efforts on our standards which play such a crucial role in the newstech industry.
Thank you.
Paul Harman
Chair, IPTC Standards Committee
20 October 2021
The IPTC NewsCodes Working Group has now released the Q4 update to Media Topics, IPTC’s subject taxonomy used for classifying news content.
The main changes were made to the religion branch as part of our regular review cycle, and to sport events after discussing the terms with the Sports Content Working Group. This means that we have retired 29 terms and added 15 others. So in total we currently have 1,159 active terms in the vocabulary.
All new terms were created in en-GB and en-US versions, and have translations in Norwegian thanks to NTB. Other language translations will be added as they are contributed.
Below is a list of all of the changes.
New terms:
- medtop:20001338 education policy
- medtop:20001339 wellness
- medtop:20001340 mental wellbeing
- medtop:20001341 regular competition
- medtop:20001342 playoff championship
- medtop:20001343 final game
- medtop:20001344 Catholicism
- medtop:20001345 bar and bat mitzvah
- medtop:20001346 canonisation
- medtop:20001347 Shia Islam
- medtop:20001348 Sunni Islam
- medtop:20001349 atheism and agnosticism
- medtop:20001350 Eid al-Adha
- medtop:20001351 Hasidism
- medtop:20001352 Hanukkah
Retired terms:
- medtop:20000660 ecumenism
- medtop:20000662 Old Catholic
- medtop:20000665 Anglican
- medtop:20000666 Baptist
- medtop:20000667 Lutheran
- medtop:20000668 Mennonite
- medtop:20000669 Methodist
- medtop:20000670 Reformed
- medtop:20000671 Roman Catholic
- medtop:20000672 concordat
- medtop:20000675 Freemasonry
- medtop:20000687 interreligious dialogue
- medtop:20000689 religious event
- medtop:20000701 temple
- medtop:20001109 continental championship
- medtop:20001110 continental cup
- medtop:20001111 continental games
- medtop:20001112 international championship
- medtop:20001113 international cup
- medtop:20001114 international games
- medtop:20001115 national championship
- medtop:20001116 national cup
- medtop:20001117 national games
- medtop:20001118 regional championship
- medtop:20001119 regional cup
- medtop:20001120 regional games
- medtop:20001121 world championship
- medtop:20001122 world cup
- medtop:20001123 world games
Label changes:
- medtop:12000000 religion and belief -> religion
- medtop:20000128 international court or tribunal -> international court and tribunal
- medtop:20000423 environmental politics -> environmental policy
- medtop:20000458 mental health and disorders -> mental health
- medtop:20000657 religious belief -> belief systems
- medtop:20000661 Mormon -> Mormonism
- medtop:20000663 Orthodoxy -> Christian Orthodoxy
- medtop:20000664 Protestant -> Protestantism
- medtop:20000674 cult and sect -> cult
- medtop:20000690 religious festival or holiday -> religious festival and holiday
- medtop:20000697 religious facilities -> religious facility
- medtop:20000702 religious institutions and state relations -> relations between religion and government
Definition changes:
- medtop:12000000 religion
- medtop:20000117 arbitration and mediation
- medtop:20000423 environmental policy
- medtop:20000657 belief systems
- medtop:20000658 Buddhism
- medtop:20000659 Christianity
- medtop:20000661 Mormonism
- medtop:20000664 Protestantism
- medtop:20000673 Confucianism
- medtop:20000674 cult
- medtop:20000676 Hinduism
- medtop:20000677 Islam
- medtop:20000678 Jainism
- medtop:20000679 Judaism
- medtop:20000680 nature religion
- medtop:20000681 Zoroastrianism
- medtop:20000682 Scientology
- medtop:20000683 Shintoism
- medtop:20000684 Sikhism
- medtop:20000685 Taoism
- medtop:20000686 Unificationism
- medtop:20000690 religious festival and holiday
- medtop:20000691 Christmas
- medtop:20000692 Easter
- medtop:20000693 Pentecost
- medtop:20000694 Ramadan
- medtop:20000695 Yom Kippur
- medtop:20000696 religious ritual
- medtop:20000697 religious facility
- medtop:20000698 church
- medtop:20000699 mosque
- medtop:20000700 synagogue
- medtop:20000702 relations between religion and government
- medtop:20000704 pope
- medtop:20000705 religious text
- medtop:20000706 Bible
- medtop:20000708 Torah
- medtop:20001271 All Saints Day
- medtop:20001273 baptism
Hierarchy moves:
- medtop:20000423 environmental policy moved from medtop:06000000 environment to medtop:20000621 government policy
- medtop:20000479 healthcare policy moved from medtop:07000000 health to medtop:20000621 government policy
- medtop:20000480 government health care moved from medtop:20000479 healthcare policy to medtop:07000000 health
- medtop:20000483 health insurance moved from medtop:20000479 healthcare policy to medtop:07000000 health
- medtop:20000690 religious festival and holiday moved from medtop:20000689 religious event to medtop:12000000 religion
- medtop:20000696 religious ritual moved from medtop:20000689 religious event to medtop:12000000 religion
- medtop:20001177 Olympic Games moved from medtop:20001123 world gamesto medtop:20001108 sport event
- medtop:20001178 Paralympic Games moved from medtop:20001123 world games to medtop:20001108 sport event
- medtop:20001239 exercise and fitness moved from medtop:10000000 lifestyle and leisure to medtop:20001339 wellness
- medtop:20001293 streaming service moved from medtop:20000045 mass media to medtop:20000304 media
As always, the Media Topics vocabularies can be viewed in the following ways:
- In a collapsible tree view
- As a downloadable Excel spreadsheet
- On one page on the cv.iptc.org server
- In machine readable formats such as RDF/XML and Turtle using the SKOS vocabulary format: see the cv.iptc.org guidelines document for more detail.
For more information on IPTC NewsCodes in general, please see the IPTC NewsCodes Guidelines.
At the recent IPTC Standards Committee Meeting, NewsML-G2 version 2.30 was approved.
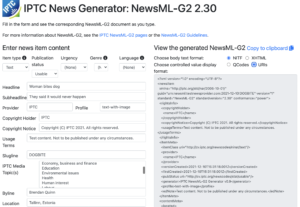
The full NewsML-G2 XML Schema, NewsML-G2 Guidelines document and NewsML-G2 specification document have all now been updated.
The biggest change (Change Request CR00211) is that <catalogRef/> and <catalog/> elements are now optional. This is so that users who choose to use full URIs instead of QCodes do not need to include an unnecessary element.
The other user-facing change is CR00212 which adds residrefformat and residrefformaturi attributes to the targetResourceAttributes attribute group, used in <link>, <icon> and <remoteContent>.
Other changes CR00213 and CR00214 aren’t visible to end users and don’t change any functionality, but make the XML Schema easier to read and maintain.
- The top-level folder of the NewsML-G2 v2.30 release is http://iptc.org/std/NewsML-G2/2.30/.
- The NewsML-G2 Implementation Guidelines document, updated to cover version 2.30 is available at https://www.iptc.org/std/NewsML-G2/guidelines
- The latest NewsML-G2 Specification document is available at https://www.iptc.org/std/NewsML-G2/specification/
- The XML Schema for NewsML-G2 v2.30 is at http://iptc.org/std/NewsML-G2/2.30/specification/NewsML-G2_2.30-spec-All-Power.xsd
XML Schema documentation of version 2.30 version is available on GitHub and at http://iptc.org/std/NewsML-G2/2.30/specification/XML-Schema-Doc-Power/.
NewsML-G2 Generator updated
The NewsML-G2 Generator has been updated to use version 2.30. This means that catalogRef is only included if QCode mode is chosen. The Generator also uses the new layout which means that the target document is updated in real time as the form is completed.
To follow our work on GitHub, please see the IPTC NewsML-G2 GitHub repository.
The full NewsML-G2 change log showing the Change Requests included in each new version is available at the dev.iptc.org site.