Categories
Archives

Together with partner organisation the PLUS Coalition, the IPTC has submitted a response to the UK Intellectual Property Office’s consultation on Copyright and Artificial Intelligence.
Our position can be summarised as the following:
- On behalf of our memberships, IPTC and PLUS respectfully suggest that existing UK copyright law is sufficient to enable licensing of content to AI platforms. There is no “fair use” provision in UK copyright law, and “fair dealing” does not cover commercial AI training. Existing copyright law should be enforced.
- IPTC and PLUS Photo Metadata provide a technical means for expressing the creator’s intent as to whether their creations may be used in generative AI training data sets. This takes the form of metadata embedded in image and video files. This solution, in combination with other solutions such as the Text and Data Mining Reservation Protocol, could take the place of a formal licence agreement between parties, making an opt-in approach technically feasible and scalable.
- It is true that our technical solutions would also be relevant if the UK government chooses to implement an “opt-out” approach similar to that adopted in the EU. However, an opt-out-based approach does not currently protect owners’ rights well, due to the routine activity of “metadata stripping” – removing important rights and accessibility metadata that is embedded in media files, in the misguided belief that it will improve site performance. Metadata stripping is performed by many publishers and publishing systems – often inadvertently. (See our research on metadata stripping by social media platforms from 2019; very little has changed since then)
- As a result, we can only recommend that the UK adopts an opt-in approach. We request that the UK ensures metadata embedded in media files be declared as a core part of any technical mechanism to declare content owner’s desire for content to be included or excluded from training data sets.
During the course of this consultation, it has become clear that content creators are a core part of the UK economy and have a strong voice. We agree with their position, but we don’t simply come with another voice of complaint: we bring a viable, ready-made technical solution that can be used today to implement true opt-in data mining permissions and reservations.
The full document in PDF form can be viewed here:
The IPTC is happy to announce that EIDR and IPTC have signed a liaison agreement, committing to work together on projects of mutual interest including media metadata, content distribution technologies and work on provenance and authenticity for media.
The Entertainment Identifier Registry Association (EIDR) was established to provide a universal identifier registry that supports the full range of asset types and relationships between assets. Members of EIDR include Apple, Amazon MGM Studios, Fox, the Library of Congress, Netflix, Paramount, Sony Pictures, Walt Disney Studios and many more.
As EIDR said in their release:
EIDR’s primary focus is managing globally unique, curated, and resolvable content identification (which applies equally to news and entertainment media), via the Emmy Award-winning EIDR Content ID, and content delivery services, via the EIDR Video Service ID. In support of this, EIDR is built upon and helps promulgate the MovieLabs Digital Distribution Framework (MDDF), a suite of standards and specifications that address core aspects of digital distribution, including identification, metadata, avails, asset delivery, and reporting.
IPTC’s Video Metadata Hub standard already provides a mapping to EIDR’s Data Fields and the MDDF fields from related organisation MovieLabs. The organisations will work together to keep these mappings up-to-date and to work on future initiatives including making C2PA metadata work for both the news and the entertainment sides of the media industry. IPTC members have already started working in this area via IPTC’s Media Provenance Committee.
“In the Venn diagram of media, there is significant overlap between news and entertainment interests in descriptive metadata standards, globally-unique content identification, and media provenance and authenticity,” said Richard W. Kroon, EIDR’s director of technical operations. “By working together, we each benefit from the other’s efforts and can bring forth useful standards and practices that span the entire commercial media industry.
“Our hope here is to find common ground that can align our respective metadata standards to support seamless metadata management across the commercial media landscape.”
In October 2024, 70 people representing 30 organisations from 15 countries across four continents gathered at the BBC building in Salford to join the Origin Media Provenance Seminar. The seminar was organised by BBC R&D with partners from Media Cluster Norway (MCN) in Bergen.
Media provenance is a way to record digitally signed information about the provenance of imagery, video and audio – information (or signals) that shows where a piece of media has come from and how it’s been edited. Like an audit trail or a history, these signals are called ‘content credentials’, and are developed as an open standard by the C2PA (Coalition for Content Provenance and Authenticity). Content credentials have just been selected by Time magazine as one of their ‘Best Inventions of 2024’.
Attendees came from all over the world, including the US, Japan, all over Europe, and also sub-Saharan Africa.
According to the BBC blog post:
In order for news organisations to show their consumers that they really are looking at some content from the real “BBC”, content credentials use the same technology as websites – digital certificates – to prove who signed it. The International Press Telecommunications Council (IPTC) has created a programme called “Origin Verified News Publishers”, which allows news organisations to register to get their identity checked. Once their ID has been verified, they can get a certificate, which gives consumers assurance that the content certifiably comes from the organisation they have chosen to trust.
For more information about the event, see the blog post on the BBC Research & Development blog.
For more information about the IPTC Origin Verified News Publishers List, please see the Media Provenance section of the IPTC website or contact the IPTC directly.

On Thursday, Google announced that it will be extending its usage of AI content labelled using the IPTC Digital Source Type vocabulary.
We have previously shared that Google uses IPTC Photo Metadata to signal AI-generated and AI-edited media, for example labelling images edited with the Magic Eraser tool on Pixel phones.
In a blog post published on Friday, John Fisher, Engineering Director for Google Photos and Google One posted that “[n]ow we’re taking it a step further, making this information visible alongside information like the file name, location and backup status in the Photos app.”
This is based on IPTC’s Digital Source Type vocabulary, which was updated a few weeks ago to include new terms such as “Multi-frame computational capture sampled from real life” and “Screen capture“.
Google already surfaces Digital Source Type information in search results via the “About this image” feature.
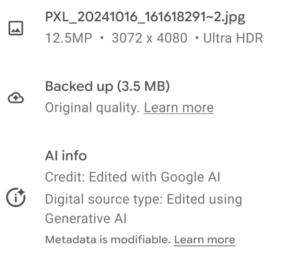
Also, the human-readable label for the term http://cv.iptc.org/newscodes/digitalsourcetype/trainedAlgorithmicMedia was clarified to be “Created using Generative AI” and similarly the label for the term http://cv.iptc.org/newscodes/digitalsourcetype/compositeWithTrainedAlgorithmicMedia was clarified to be “Edited with Generative AI.” These terms are both used by Google.

Over a weekend in mid-September every year, Europe’s (and increasingly the world’s) broadcast media industry gets together at IBC, the International Broadcasting Convention.
IPTC members were well represented at this year’s event:
- IPTC Startup Members Factiverse were out in full force promoting their automated fact-checking solution, which can now be integrated into any media asset management tool via an API.
- Fellow Startup Members HAND – Human & Digital presented their work on an IBC Accelerator project looking at called “Digital Replicas and Talent ID: Provenance, Verification and New Automated Workflows” along with Paramount, ITV, EZDRM and The Scan Truck.
- Moments Lab (previously known as Newsbridge) presented their video segmentation and annotation systems on a very well attended stand.
- The BBC featured in many sessions. Judy Parnall, lead of IPTC’s Media Provenance Committee’s Advocacy and Education Working Group, presented two papers, both concerning the BBC’s work with C2PA, leading to the BBC’s work with Project Origin and the IPTC Media Provenance Committee. One was presented along with new IPTC Individual Member, John Simmons.
- Newly upgraded to IPTC Voting Members, he European Broadcasting Union (EBU) had a very popular stand demonstrating several accelerator projects, including the best demonstrator of C2PA we have yet seen: an end-to-end workflow from a Content Credential-enabled Leica camera, along with AI-generated content from Adobe Firefly, edited in Adobe Premiere Pro, and published using WDR’s publisher certificate which is on the new IPTC Verified News Publisher list. IPTC Managing Director Brendan Quinn gave a short presentation at the EBU stand’s C2PA meet-up event, explaining the IPTC’s recently-announced work on the Verified News Publisher List. Other speakers at the meet-up were Kenneth from WDR, Andy Parsons from Adobe and the Content Authenticity Initiative, Go Ohtake of NHK (who demonstrated a prototype C2PA application running on a Web TV platform), and project lead Lucille Verbaere of the EBU.
- Media Cluster Norway (previously known as Media City Bergen) ran an awesome breakfast event about Project Reynir, their project to make Norway’s media ecosystem a pathfinder for C2PA technology from one end of the production workflow to the other, including vendors such as VizRT and Wolftech, Norwegian news agency NTB and more.
- Liaison partner The DPP had a great reception where the industry came together to discuss future projects including the Live Production Exchange project on which IPTC is assisting via our News in JSON (ninjs) Working Group.
- Of course Adobe and Google both had enormous and well attended stands, Associated Press and Reuters were receiving a lot of attention (particular after Reuters’ acquisition of digital content management company Imagen last year). Arqiva and Broadcast Solutions were also represented with well-attended stands.
From what we could see, all IPTC members who attended the convention had a very successful time, and we look forward to many future successful events.
We hope to see all of you again at the IPTC Autumn Meeting next week!
AMSTERDAM, 13 September 2024 — The International Press Telecommunications Council (IPTC) has announced Phase 1 of the IPTC Verified News Publishers List at the International Broadcast Convention (IBC).
The list uses C2PA technology to enable verified provenance for the news media industry. News outlets apply for a certificate from a partner Certificate Authority (currently Truepic), with the IPTC verifying the identity of the publisher. The certificate is then used by the news outlet to sign content, in accordance with the C2PA specification’s handling of “additional trust anchor stores”. This means that the news publisher is the signer of the content. This is a key requirement for many media outlets.
Currently the BBC (UK), CBC / Radio Canada (Canada) and broadcaster WDR (Germany) have certificates on the Verified News Publishers List. Many more publishers and broadcasters are currently in the process of obtaining a certificate. To register your interest as a news publisher, please fill out the Verified News Publisher expression of interest form.
To make the process of verifying and approving certificate requests transparent and accountable, the IPTC has released a set of policies for issuing Verified News Publisher certificates covering Phase 1 of the project. The process includes a “fast track” process for media organisations that are already well known to IPTC, and also a self-certification track. The policies were approved by the IPTC membership at a recent meeting of the IPTC Media Provenance Committee.
Verifying publisher identity, not trustworthiness
Note: as we have always made clear, the IPTC is making no claims about the truth or trustworthiness of content published by news publishers on the IPTC Verified News Publisher List. We simply verify that the publisher is “who they say they are”, and then the signature will verify that the content was published by that publisher, and has not been tampered with since the point of publishing.
We make it clear in the governance policies that a certificate can be revoked if the certificate’s private key has been compromised in some way, but we will not revoke certificates for editorial reasons.
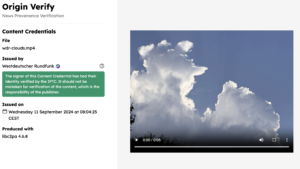
Online verifier tool
The IPTC has worked with the BBC to launch a simple Verified News Publisher content verifier tool hosted at https://originverify.iptc.org. The tool displays a special indicator when content has been signed by an organisation whose certificate is on the Verified News Publisher list. The IPTC has also published a set of Verified News Publisher sample content that can be used with the verifier to demonstrate the process in action.
Sharing best practices, resources and knowledge among news publishers
For IPTC members, the Media Provenance Committee has created an internal members-only wiki detailing best practices and lessons learned while implementing C2PA and the Verified News Publisher List at broadcasters and publishers. Information on the wiki includes technical details on how to generate a certificate signing request to obtain a certificate, how to sign content with open-source and commercial tools, how to deal with publishing and distribution technology such as streaming servers and content delivery networks, and how to add metadata to C2PA assertions embedded in media content.
The Committee has also created a public-facing area of the IPTC site describing IPTC’s work in the area of Media Provenance, helping news publishers to get up to speed and understand how C2PA technology works and how it can be implemented in publishing workflows.
Other IPTC and Media Provenance-related events at IBC this weekend:
- Judy Parnall (BBC), Lead of the IPTC Media Provenance Advocacy Working Group, spoke on a panel on “Content Tracing and Provenance” this morning (Friday) at the AI Zone.
- Judy is also presenting a paper at the IBC Conference on Saturday 14 September: Provenance: What can we Trust?, along with IPTC Individual Member John Simmons.
- Combating disinformation in News: A critical year for democracies at the IPTC Conference on Saturday. Laura Ellis (BBC) is on the panel along with representatives from CBS and GLOBO.
- On Sunday 15 September, Judy presents IBC’s Accelerator Project “Design Your Weapons in Fight Against Disinformation” on the IBC Innovation Stage, along with tech leaders from CBS, Associated Press and ITN.
The IPTC has signed a liaison agreement with the Japanese camera-makers organisation and creators of the Exif metadata standard, CIPA.
CIPA members include all of the major camera manufacturers, including Nikon, Canon, Sony, Panasonic, FUJIFILM and more. Several software vendors who work with imaging are also members, including Adobe, Apple and Microsoft.
CIPA publishes guidelines and standards for camera manufacturers and imaging software developers. The most important of these from an IPTC point of view is the Exif standard for photographic metadata.
The IPTC and CIPA have had an informal relationship for many years, staying in touch regularly regarding developments in the world of image metadata. Given that the two organisations manage two of the most important standards for embedding metadata into image and video files, it’s important that we keep each other up to date.
Now the relationship has been formalised, meaning that the organisations can request to observe each other’s meetings, exchange members-only information when needed, and share information about forthcoming developments and industry requirements for new work in the field of media metadata and in related areas.
The news has also been announced by CIPA. According to the news post on CIPA’s website, “CIPA has signed a liaison agreement regarding the development of technical standards for metadata attached to captured image with International Press Telecommunications Council (IPTC), the international organization consists of the world’s leading news agencies, publishers and industry vendors.”

The IPTC’s Managing Director, Brendan Quinn, has written an article for the latest edition of the European Broadcasting Union’s technical magazine, EBU tech-i.
In the article, Brendan promotes the IPTC’s work in Media Provenance, including the founding of the IPTC Media Provenance Committee.
Brendan’s article can be found on page 17 of the PDF or print copy or the magazine.
The issue also contains a piece by Judy Parnall of the BBC, current Chair of the Committee, also covering C2PA and our joint work on media provenance.
The issue also contains interesting insights from European broadcasters on AI in media production, innovating to meet the challenges of covering the Paris 2024 Olympics, the creation of an Enterprise Architecture working group within the EBU membership, cybersecurity for media outlets, the future of broadcast radio in a world connected cars, and more.

Media consultant and IPTC Individual Member Denise Durand Kremer gave a presentation on IPTC Photo Metadata at the Seminário Fototeca Brasileira – the Brazilian Photo Library Seminar.
Over three days, more than 80 people got together to discuss the idea of a national photo library for Brazil. Denise was invited by the Collection and Market group Acervo e Mercado to talk about her experience as an iconographic researcher and about the IPTC standard for photographic metadata.
Photographers, teachers, researchers, archivists and public managers from institutions such as the Museu da Imagem e do Som de São Paulo – MIS (Museum of Image and Sound of São Paulo), Funarte, Instituto Moreira Salles, Zumví and Arquivo Afro Fotográfico participated in the event.
The meeting ended with a commitment from the Executive Secretary of the Ministry of Culture, to set up a working group to take the idea forward.
The seminar was recorded and will be available on SescTV.
Update, 6 August 2024: The video has now been released publicly. You can view Denise’s section below (in Brazilian Portuguese):
Thanks very much Denise for spreading the word about IPTC standards in Brazil!

Last week CEPIC, the “centre of the picture industry”, held its annual Congress in Juan-les-Pins in France. This was the second time that the event was held at the Palais du Congres in Juan-les-Pins near Antibes, which is proving to be a great venue for the Congress with many repeat visitors who also attended last year.
IPTC was well represented at the event, with Managing Director Brendan Quinn presenting on two panels and many other IPTC members involved in presentations, panels or simply attending the event. IPTC members either presenting or in attendance included Google, Shutterstock, Getty Images, ANSA, IMATAG, PA Media / Alamy, TT, dpa, Adobe, Xinhua, Activo, APA, European Pressphoto Agency EPA and possibly more that we have missed!

One of the highlights for us was the Provenance and AI panel moderated by Anna Dickson, who until recently was with Google but is now with another IPTC member, Shutterstock. Presenters on this panel included Katharina Familia Almonte, product manager at Google, Andy Parsons, Director of the Content Authenticity Initiative (although Brendan ended up presenting his slides due to it being 4.30am for Andy in New York at the time!); Mathieu Desoubeaux, CEO of IPTC startup member IMATAG, and Brendan Quinn, Managing Director of IPTC.
Brendan used the opportunity to introduce the IPTC Media Provenance Committee and the work that the IPTC is doing on creating a C2PA Trust List for media organisations. Brendan put out a call for other media organisations who may be interested in joining the next cohort of certificate holders who will be able to obtain a certificate stored on the trust list and use it to cryptographically sign their media content. The discussion went on to look at the issues around using both C2PA and watermarking technology to protect image content.
Later in the day was the panel “Where Law and Technology Meet.” Moderated by Lars Modie (CEPIC, previously of IBL Bildbyrå / TT in Swededn) with speakers: Serguei Fomin (IQPlug, IPTC CEPIC representative), Brendan Quinn (IPTC), Franck Bardol (University of Geneva), Nancy Wolff (partner at the intellectual property, media and entertainment law firm of Cowan, DeBaets, Abrahams & Sheppard, LLP and DMLA counsel) and Katherine Briggs of Australian agency Envato which was recently acquired by Shutterstock.

At this panel, Brendan outlined IPTC’s recent guidance on metadata for generative AI images. This includes the Digital Source Type property but also guidance on using the Creator, Contributor, and Data Mining properties to signal ownership and rights licensing information associated with images, particularly for engines that “scrape” web content to train generative AI models.
Many stimulating conversations always make the CEPIC Congress a valuable event for us to attend, and we are already looking forward to next year’s instalment.