Categories
Archives

Together with partner organisation the PLUS Coalition, the IPTC has submitted a response to the UK Intellectual Property Office’s consultation on Copyright and Artificial Intelligence.
Our position can be summarised as the following:
- On behalf of our memberships, IPTC and PLUS respectfully suggest that existing UK copyright law is sufficient to enable licensing of content to AI platforms. There is no “fair use” provision in UK copyright law, and “fair dealing” does not cover commercial AI training. Existing copyright law should be enforced.
- IPTC and PLUS Photo Metadata provide a technical means for expressing the creator’s intent as to whether their creations may be used in generative AI training data sets. This takes the form of metadata embedded in image and video files. This solution, in combination with other solutions such as the Text and Data Mining Reservation Protocol, could take the place of a formal licence agreement between parties, making an opt-in approach technically feasible and scalable.
- It is true that our technical solutions would also be relevant if the UK government chooses to implement an “opt-out” approach similar to that adopted in the EU. However, an opt-out-based approach does not currently protect owners’ rights well, due to the routine activity of “metadata stripping” – removing important rights and accessibility metadata that is embedded in media files, in the misguided belief that it will improve site performance. Metadata stripping is performed by many publishers and publishing systems – often inadvertently. (See our research on metadata stripping by social media platforms from 2019; very little has changed since then)
- As a result, we can only recommend that the UK adopts an opt-in approach. We request that the UK ensures metadata embedded in media files be declared as a core part of any technical mechanism to declare content owner’s desire for content to be included or excluded from training data sets.
During the course of this consultation, it has become clear that content creators are a core part of the UK economy and have a strong voice. We agree with their position, but we don’t simply come with another voice of complaint: we bring a viable, ready-made technical solution that can be used today to implement true opt-in data mining permissions and reservations.
The full document in PDF form can be viewed here:
At the IPTC Autumn Meeting, the IPTC Standards Committee voted on a change proposed by the Photo Metadata Working Group, which created version 2024.1 of the IPTC Photo Metadata Standard.
The change is minor but important to some: the definition of the Keywords property now includes the following text:
Keywords to express the subject and other aspects of the content of the image. Keywords may be free text and don’t have to be taken from a controlled vocabulary. Codes from the controlled vocabulary IPTC Subject NewsCodes must go to the “Subject Code” field.
This aligns the property definition with the way in which many photo agencies and photographers were already using the field: to convey aspects such as the lighting or lens effects used, “mood” of the image, dominant colour and more.
We give examples of how the Keywords property may be used in the IPTC Photo Metadata User Guide.
The relevant files have all been updated for the new version:
- The IPTC Photo Metadata Standard Specification
- The IPTC Photo Metadata User Guide
- The IPTC Photo Metadata TechReference, in both YAML and JSON formats
- The IPTC Photo Metadata Reference Image
{kind=link}
We thank Agence France-Presse for their help in offering examples for how the Keywords property may be used.
 The IPTC has responded to a multi-stakeholder consultation on the recently-agreed European Union Artificial Intelligence Act (EU AI Act).
The IPTC has responded to a multi-stakeholder consultation on the recently-agreed European Union Artificial Intelligence Act (EU AI Act).
Although the IPTC is officially based in the UK, many of our members and staff operate from the European Union, and of course all of our members’ content is available in the EU, so it is very important to us that the EU regulates Artificial Intelligence providers in a way that is fair to all parts of the ecosystem, including content rightsholders, AI providers, AI application developers and end users.
In particular, we drew the EU AI Office’s attention to the IPTC Photo Metadata Data Mining property, which enables rightsholders to inform web crawlers and AI training systems of the rightsholders’ agreement as to whether or not the content can be used as part of a training data set for building AI models.
The points made are the same as the ones that we made to the IETF/IAB Workshop consultation: that embedded data mining declarations should be part of the ecosystem of opt-outs, because robots.txt, W3C TDM, C2PA and other solutions are not sufficient for all use cases.
The full consultation text and all public responses will be published by the EU in due course via the consultation home page.
The IPTC has signed a liaison agreement with the Japanese camera-makers organisation and creators of the Exif metadata standard, CIPA.
CIPA members include all of the major camera manufacturers, including Nikon, Canon, Sony, Panasonic, FUJIFILM and more. Several software vendors who work with imaging are also members, including Adobe, Apple and Microsoft.
CIPA publishes guidelines and standards for camera manufacturers and imaging software developers. The most important of these from an IPTC point of view is the Exif standard for photographic metadata.
The IPTC and CIPA have had an informal relationship for many years, staying in touch regularly regarding developments in the world of image metadata. Given that the two organisations manage two of the most important standards for embedding metadata into image and video files, it’s important that we keep each other up to date.
Now the relationship has been formalised, meaning that the organisations can request to observe each other’s meetings, exchange members-only information when needed, and share information about forthcoming developments and industry requirements for new work in the field of media metadata and in related areas.
The news has also been announced by CIPA. According to the news post on CIPA’s website, “CIPA has signed a liaison agreement regarding the development of technical standards for metadata attached to captured image with International Press Telecommunications Council (IPTC), the international organization consists of the world’s leading news agencies, publishers and industry vendors.”

The Internet Architecture Board (IAB), a Committee of the Internet Engineering Task Force (IETF) which decides on standards and protocols that are used to govern the workings of Internet infrastructure, is having a workshop in September on “AI Control”. Discussions will include whether one or more new IETF standards should be defined to govern how AI systems work with Internet content.
As part of the lead-up to this workshop, the IAB and IETF have put out a call for position papers on AI opt-out techniques.
Accordingly, the IPTC Photo Metadata Working Group, in association with partner organisation the PLUS Coalition, submitted a position paper discussing in particular the Data Mining property which was added to the IPTC Photo Metadata Standard last year.
In the paper, the IPTC and PLUS set out their position that data mining opt-out information embedded in the metadata of media files is an essential part of any opt-out solution.
Here is a relevant section of the IPTC submission:
We respectfully suggest that Robots.txt alone is not a viable solution. Robots.txt may allow for communication of rights information applicable to all image assets on a website, or within a web directory, or on specific web pages. However, it is not an efficient method for communicating rights information for individual image files published to a web platform or website; as rights information typically varies from image to image, and as the publication of images to websites is increasingly dynamic.
In addition, the use of robots.txt requires that each user agent must be blocked separately, repeating all exclusions for each AI engine crawler robot. As a result, agents can only be blocked retrospectively — after they have already indexed a site once. This requires that publishers must constantly check their server logs, to search for new user agents crawling their data, and to identify and block bad actors.
In contrast, embedding rights declaration metadata directly into image and video files provides media-specific rights information, protecting images and video resources whether the site/page structure is preserved by crawlers — or the image files are scraped and separated from the original page/site. The owner, distributor, or publisher of an image can embed a coded signal into each image file, allowing downstream systems to read the embedded XMP metadata and to use that information to sort/categorise images and to comply with applicable permissions, prohibitions and constraints.
IPTC, PLUS and XMP metadata standards have been widely adopted and are broadly supported by software developers, as well as in use by major news media, search engines, and publishers for exchanging images in a workflow as part of an “operational best practice.” For example, Google Images currently uses a number of the existing IPTC and PLUS properties to signal ownership, licensor contact info and copyright. For details see https://iptc.org/standards/photo-metadata/quick-guide-to-iptc-photo-metadata-and-google-images/
The paper in PDF format can be downloaded from the IPTC site.
Thanks to David Riecks, Margaret Warren, Michael Steidl from the IPTC Photo Metadata Working Group and to Jeff Sedlik from PLUS for their work on the paper.

Media consultant and IPTC Individual Member Denise Durand Kremer gave a presentation on IPTC Photo Metadata at the Seminário Fototeca Brasileira – the Brazilian Photo Library Seminar.
Over three days, more than 80 people got together to discuss the idea of a national photo library for Brazil. Denise was invited by the Collection and Market group Acervo e Mercado to talk about her experience as an iconographic researcher and about the IPTC standard for photographic metadata.
Photographers, teachers, researchers, archivists and public managers from institutions such as the Museu da Imagem e do Som de São Paulo – MIS (Museum of Image and Sound of São Paulo), Funarte, Instituto Moreira Salles, Zumví and Arquivo Afro Fotográfico participated in the event.
The meeting ended with a commitment from the Executive Secretary of the Ministry of Culture, to set up a working group to take the idea forward.
The seminar was recorded and will be available on SescTV.
Update, 6 August 2024: The video has now been released publicly. You can view Denise’s section below (in Brazilian Portuguese):
Thanks very much Denise for spreading the word about IPTC standards in Brazil!

The 2024 IPTC Photo Metadata Conference takes place as a webinar on Tuesday 7th May from 1500 – 1800 UTC. Speakers hail from Adobe (makers of Photoshop), CameraBits (makers of PhotoMechanic), Numbers Protocol, Colorhythm, vAIsual and more.
First off, IPTC Photo Metadata Working Group co-leads, David Riecks and Michael Steidl, will give an overview of what has been happening in the world of photo metadata since our last Conference in November 2022, including IPTC’s work on metadata for AI labelling, “do not train” signals, provenance, diversity and accessibility.
Next, a panel session on AI and Image Authenticity: Bringing trust back to photography? discusses approaches to the problem of verifying trust and credibility for online images. The panel features C2PA lead architect Leonard Rosenthol (Adobe), Dennis Walker (Camera Bits), Neal Krawetz (FotoForensics) and Bofu Chen (Numbers Protocol).
Next, James Lockman of Adobe presents the Custom Metadata Panel, which is a plugin for Photoshop, Premiere Pro and Bridge that allows for any XMP-based metadata schema to be used – including IPTC Photo Metadata and IPTC Video Metadata Hub. James will give a demo and talk about future ideas for the tool.
Finally, a panel on AI-Powered Asset Management: Where does metadata fit in? discusses teh relevance of metadata in digital asset management systems in an age of AI. Speakers include Nancy Wolff (Cowan, DeBaets, Abrahams & Sheppard, LLP), Serguei Fomine (IQPlug), Jeff Nova (Colorhythm) and Mark Milstein (vAIsual).
The full agenda and links to register for the event are available at https://iptc.org/events/photo-metadata-conference-2024/
Registration is free and open to anyone who is interested.
See you there on Tuesday 7th May!
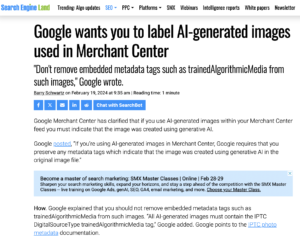
Google has added Digital Source Type support to Google Merchant Center, enabling images created by generative AI engines to be flagged as such in Google’s products such as Google search, maps, YouTube and Google Shopping.
In a new support post, Google reminds merchants who wish their products to be listed in Google search results and other products that they should not strip embedded metadata, particularly the Digital Source Type field which can be used to signal that content was created by generative AI.
We at the IPTC fully endorse this position. We have been saying for years that website publishers should not strip metadata from images. This should also include tools for maintaining online product inventories, such as Magento and WooCommerce. We welcome contact from developers who wish to learn more about how they can preserve metadata in their images.
Here’s the full text of Google’s recommendation:
![Preserving metadata tags for AI-generated images in Merchant Center
February 2024
If you’re using AI-generated images in Merchant Center, Google requires that you preserve any metadata tags which indicate that the image was created using generative AI in the original image file.
Don't remove embedded metadata tags such as trainedAlgorithmicMedia from such images. All AI-generated images must contain the IPTC DigitalSourceType trainedAlgorithmicMedia tag. Learn more about IPTC photo metadata.
These requirements apply to the following image attributes in Merchant Center Classic and Merchant Center Next:
Image link [image_link]
Additional image link [additional_image_link]
Lifestyle image link [lifestyle_image_link]
Learn more about product data specifications.](https://iptc.org/wp-content/uploads/2024/02/Screenshot-2024-02-20-at-09.56.52-1024x724.png)
 The IPTC is happy to announce the latest version of our guidance for mapping between photo metadata standards.
The IPTC is happy to announce the latest version of our guidance for mapping between photo metadata standards.
Following our publication of IPTC’s rules for mapping photo metadata between IPTC, Exif and schema.org standards in 2022, the IPTC Photo Metadata Working Group has been monitoring updates in the photo metadata world.
In particular, the IPTC gave support and advice to CIPA while it was working on Exif 3.0 and we have updated our mapping rules to work with the latest changes to Exif expressed in Exif 3.0.
As well as guidelines for individual properties between IPTC Photo Metadata Standard (in both the older IIM form and the newer XMP embedding format), Exif and schema.org, we have included some notes on particular considerations for mapping contributor, copyright notice, dates and IDs.
The IPTC encourages all developers who previously consulted the out-of-date Metadata Working Group guidelines (which haven’t been updated since 2008 and are no longer published) to use this guide instead.

Updated in June 2024 to include an image containing the new metadata property
Many image rights owners noticed that their assets were being used as training data for generative AI image creators, and asked the IPTC for a way to express that such use is prohibited. The new version 2023.1 of the IPTC Photo Metadata Standard now provides means to do this: a field named “Data Mining” and a standardised list of values, adopted from the PLUS Coalition. These values can show that data mining is prohibited or allowed either in general, for AI or Machine Learning purposes or for generative AI/ML purposes. The standard was approved by IPTC members on 4th October 2023 and the specifications are now publicly available.
Because these data fields, like all IPTC Photo Metadata, are embedded in the file itself, the information will be retained even after an image is moved from one place to another, for example by syndicating an image or moving an image through a Digital Asset Management system or Content Management System used to publish a website. (Of course, this requires that the embedded metadata is not stripped out by such tools.)
Created in a close collaboration with PLUS Coalition, the publication of the new properties comes after the conclusion of a public draft review period earlier this year. The properties are defined as part of the PLUS schema and incorporated into the IPTC Photo Metadata Standard in the same way that other properties such as Copyright Owner have been specified.
The new properties are now finalised and published. Specifically, the new properties are as follows:
- Data Mining: a field with a value from a controlled value vocabulary. Values come from the PLUS Data Mining vocabulary, reproduced here:
- http://ns.useplus.org/ldf/vocab/DMI-UNSPECIFIED (Unspecified – no prohibition defined)
- http://ns.useplus.org/ldf/vocab/DMI-ALLOWED (Allowed)
- http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-AIMLTRAINING (Prohibited for AI/ML training)
- http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-GENAIMLTRAINING (Prohibited for Generative AI/ML training)
- http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-EXCEPTSEARCHENGINEINDEXING (Prohibited except for search engine indexing)
- http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED (Prohibited)
- http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEECONSTRAINT (Prohibited, see Other Constraints property)
- http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEEEMBEDDEDRIGHTSEXPR (Prohibited, see Embedded Encoded Rights Expression property)
- http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEELINKEDRIGHTSEXPR (Prohibited, see Linked Encoded Rights Expression property)
- Other Constraints: Also defined in the PLUS specification, this text property is to be used when the Data Mining property has the value “http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEECONSTRAINT“. It can specify, in a human-readable form, what other constraints may need to be followed to allow Data Mining, such as “Generative AI training is only allowed for academic purposes” etc.
The IPTC and PLUS Consortium wish to draw users attention to the following notice included in the specification:
Regional laws applying to an asset may prohibit, constrain, or allow data mining for certain purposes (such as search indexing or research), and may overrule the value selected for this property. Similarly, the absence of a prohibition does not indicate that the asset owner grants permission for data mining or any other use of an asset.
The prohibition “Prohibited except for search engine indexing” only permits data mining by search engines available to the public to identify the URL for an asset and its associated data (for the purpose of assisting the public in navigating to the URL for the asset), and prohibits all other uses, such as AI/ML training.
The IPTC encourages all photo metadata software vendors to incorporate the new properties into their tools as soon as possible, to support the needs of the photo industry.
ExifTool, the command-line tool for accessing and manipulating metadata in image files, already supports the new properties. Support was added in the ExifTool version 12.67 release, which is available for download on exiftool.org.
The new version of the specification can be accessed at https://www.iptc.org/std/photometadata/specification/IPTC-PhotoMetadata or from the navigation menu on iptc.org. The IPTC Get Photo Metadata tool and IPTC Photo Metadata Reference images been updated to use the new properties.
The IPTC and PLUS Coalition wish to thank many IPTC and PLUS member organisations and others who took part in the consultation process around these changes. For further information, please contact IPTC using the Contact Us form.