Categories
Archives

The survey describes various technologies which could be used by content owners and rights holders to express opt-in or opt-out information regarding whether rights holders allow AI engines to train on media content. It asked our thoughts on how widely they have been adopted and how suitable they would be to be adopted as a mechanism for expressing machine-readable opt-out preferences.
This is the first step in a multi-stage process, which will culminate in the publication by the European Commission of the final list of generally agreed TDM opt-out protocols.
We feel that the IPTC is well-suited to participate in this work for several reasons:
- IPTC has created one such mechanism (the Data Mining property of the IPTC Photo Metadata Standard, created in conjunction with the PLUS Coalition)
- IPTC has been involved in the creation of other technologies in this area as such the W3C Community’s Text and Data Mining Reservation Protocol (TDMRep), C2PA, and the IETF’s work in the AIPrefs Working Group
- IPTC has published a guidance document for publishers on best practices for implementing AI opt-out technologies
We look forward to continuing work with the European Commission, and others, on this subject.

The IPTC Photo Metadata Working Group has released version 2025.1 of the IPTC Photo Metadata Standard, including properties that can be used for AI-generated content.
The new properties are:
- AI System Used
Definition: The AI engine and/or the model name used to generate this image.
User Note: For example, ChatGPT DALL-E, Google Gemini, ChatGPT
Suggest help text: Enter the name of the AI system and/or the model name used to generate this image. - AI System Version Used
Definition: The version of the AI system used to generate this image, if known.
Suggested help text: Enter the name or number of the version of the AI system used to generate this image. - AI Prompt Information
Definition: The information that was given to the generative AI service as “prompt(s)” in order to generate this image.
User Note: This may include negative [excludes] and positive [includes] statements in the prompt.
Suggested help text: Enter the information given to the generative AI service as “prompt(s)” in order to generate this image. - AI Prompt Writer Name
Definition: Name of the person who wrote the prompt used for generating this image.
User Note: This person should not be considered as the image creator.
Suggested help text: Enter the name of the person who wrote the prompt used for generating this image.
IPTC’s specification materials have been updated to accommodate the new properties:
- IPTC Photo Metadata Standard Specification 2025.1
- The IPTC Photo Metadata User Guide has been updated, particularly the guidance on Applying Metadata to AI-generated images
- The IPTC Photo Metadata Reference Image 2025.1 which contains values for all IPTC Photo Metadata properties, including the four properties added in version 2025.1
- IPTC Photo Metadata TechReference:
- The GetPMD photo metadata reading tool has been updated to read the new fields.
{kind=link}
The new properties are expected to be implemented in software tools soon. The popular open-source tool Exiftool already supports the new properties, since version 13.40 which was released on October 24th 2025.
Thanks to everyone who contributed to our request for comments on these new properties. We made several changes based on feedback from IPTC members and others, so your contributions were well appreciated.
For more information please contact IPTC or join our public iptc-photometadata@groups.io mailing list.

The IPTC is pleased to announce the full agenda for the 2025 IPTC Photo Metadata Conference, which will be held online on Thursday September 18th from 15.00 to 18.00 UTC. The focus this year is on how image metadata can improve real-world workflows.
We are excited to be joined by the following speakers:
- Brendan Quinn, IPTC Managing Director, presenting two sessions: presenting IPTC’s AI Opt-Out Best Practices guidelines and also an update on IPTC’s work with C2PA and the Media Provenance Committee
- David Riecks, Lead of the IPTC Photo Metadata Working Group, presenting two sessions: the latest on IPTC’s proposed new properties for Generative AI, and also an update on the Adobe Custom Metadata Panel plugin and how it makes the complete IPTC Photo Metadata Standard available in Adobe products
- Paul Reinitz, consultant previously with Getty Images, discussing AI opt-out and copyright issues
- Ottar A. B. Anderson, previously a photographer with the Royal Norwegian Air Force and with over 15 years of experience as a commercial photographer, on proposals for metadata for image archiving and his work on the Digital Object Authenticity Working Group (DOAWG)
- Jerry Lai, previously a photographer for Getty Images, Reuters and Associated Press and now with Imagn, presenting a case study on using AI for captioning huge numbers of images for Super Bowl LIX
- Marcos Armstrong, Senior Specialist, Content Provenance at CBC/Radio-Canada, speaking about CBC’s project to map editorial workflows and identify where content authenticity technologies can be used in the newsroom
- Tim Bray, creator of XML and founder of OpenText Corporation, among many others, speaking on his experiences with C2PA and his ideas for how it can be adopted in the future

This year’s conference promises to be a great one, with topics ranging from Generative AI and media provenance technology to the technical details of scanning historical documents, but always with a focus on how new technologies can be applied in the real world.
Registration is free and open to anyone.
See more information at the event page on the IPTC web site or simply sign up at the Zoom webinar page.
We look forward to seeing you there!

The IPTC participated in a “design team” workshop for the Internet Engineering Task Force (IETF)’s AI Preferences Working Group. Brendan Quinn, IPTC Managing Director attended the workshop in London along with representatives from Mozilla, Google, Microsoft, Cloudflare, Anthropic, Meta, Adobe, Common Crawl and more.
As per the group’s charter, “The AI Preferences Working Group will standardize building blocks that allow for the expression of preferences about how content is collected and processed for Artificial Intelligence (AI) model development, deployment, and use.” The intent is that this will take the form of an extension to the commonly-used Robots Exclusion Protocol (RFC9309). This document defines the way that web crawlers should interact with websites.
The idea is that the Robots Exclusion Protocol would specify how website owners would like content to be collected, and the AI Preferences specification defines the statements that rights-holders can use to express how they would like their content to be used.
The Design Team is discussing and iterating the group’s draft documents: the Vocabulary for Expressing AI Usage Preferences and the “attachment” definition document, Indicating Preferences Regarding Content Usage. The results of the discussions will be taken to the IETF plenary meeting in Madrid next week, and
Discussions have been wide-ranging and include use cases for varying options of opt-in and opt-out, the ability to opt out of generative AI training but to allow search engine indexing, and the difference between preferences for training and preferences for how content can be used at inference time (also known as prompt time or query time, such as RAG or “grounding” use cases) and the varying mechanisms for attaching these preferences to content, i.e. a website’s robots.txt file, HTTP headers and embedded metadata.
The IPTC has already been looking at this area and defined a data mining usage vocabulary in conjunction with the PLUS Coalition in 2023. There is a possibility that our work will change to reflect the IETF agreed vocabulary.
The work also relates to IPTC’s recently-published guidance for publishers on opting out of Generative AI training. Hopefully we will be able to publish a much simpler version of this guidance in the future because of the work from the IETF.

The IPTC is excited to announce the latest updates to ninjs, our JSON-based standard for representing news content metadata. Version 3.1 is now available, along with updated versions 2.2 and 1.6 for those using earlier schemas.
These releases reflect IPTC’s ongoing commitment to supporting structured, machine-readable news content across a variety of technical and editorial workflows.
What is ninjs?
ninjs (News in JSON) is a flexible, developer-friendly format for describing news items in a structured way. It allows publishers, aggregators, and news tech providers to encode rich metadata about articles, images, videos, and more, using a clean JSON format that fits naturally into modern content pipelines.
What’s new in ninjs 3.1, 2.2 and 1.6?
The new releases add a new property for the IPTC Digital Source Type property, which was first used with the IPTC Photo Metadata Standard but now used across the industry to declare the source of media content, including content generated or manipulated by a Generative AI engine.
The new property (called digitalSourceType in 3.1 and digitalsourcetype in 2.2 and 1.6 to match the case conventions of each standard version) has the following properties:
- Name: the name of the digital source type, such as “Created using Generative AI”
- URI: the official identifier of the digital source type from the IPTC Digital Source Type vocabulary or another vocabulary, such as http://cv.iptc.org/newscodes/digitalsourcetype/trainedAlgorithmicMedia (the official ID for generative AI content)
- Literal: an optional way to add new digital source types that are not part of a controlled vocabulary.
IPTC supports multiple versions of ninjs in parallel to ensure stability and continuity for publishers and platforms that depend on long-term schema support.
The new property is part of the general ninjs schema, and so can be used in the main body of a ninjs object to describe the main news item and can also be used in an “association” object which refers to an associated media item.
Access the schemas
All versions are publicly available on the IPTC website:
ninjs generator and user guide
The ninjs Generator tool has been updated to cover the latest versions. Fill in the form fields and see what that content looks like in ninjs format. You can switch between the schema versions to see how the schema changes between 1.6, 2.2 and 3.1.
The ninjs User Guide has also been updated to reflect the newly added property.
Why it matters
As the news industry becomes increasingly reliant on metadata for content distribution, discoverability, and rights management, ninjs provides a modern, extensible foundation that supports both human and machine workflows. It’s trusted by major news agencies, technology platforms, and AI developers alike.
Get involved
We welcome feedback from the community and encourage you to share how you’re using ninjs in your own products or platforms. If you would like to discuss ninjs, you can join the public mailing list at https://groups.io/g/iptc-ninjs.
If you’re interested in contributing to the development of IPTC standards, join us!

The IPTC has released a set of guidelines expressing best practices that publishers can follow to express the fact that they reserve data-mining rights on their copyrighted content.
All of the recommended techniques use currently available technologies. While the IPTC is advocating both for better acknowledgement in law of current techniques and for clearer, more stable and more scalable techniques for expressing data-mining opt-out, it is important to remember that opt-out can be expressed today, and that publishers shouldn’t wait for future standards to emerge if they want to control data mining rights on their copyrighted content.
Summary of the recommendations
For full detail, please view the PDF opt-out best practices guidelines. A summary of the guidance is provided below.
-
Display a plain-language, visible rights reservation declaration for all copyrighted content
To ensure no misrepresentation, ensure that copyright and rights reservations are plainly displayed to human readers. -
Display a rights reservation declaration in metadata tags on copyrighted content
Using schema.org, the IPTC Photo Metadata Standard and/or IPTC Video Metadata Hub, the same human-readable copyright notice and usage terms should be attached to media content where possible. -
Use Internet firewalls to block AI crawler bots from accessing your content
To ensure that crawlers that ignore robots.txt and other metadata cannot access your content, publishers can employ network-level protection to block crawler bots before they can reach your content. -
Instruct AI crawler bots using their user agent IDs in your robots.txt file
Seemingly the simplest method, this is actually one of the most difficult because each AI system’s crawler user-agent must be blocked separately. -
Implement a site-wide tdmrep.json file instructing bots which areas of the site can be used for Generative AI training
The Text and Data Mining Reservation Protocol can and should be used, in combination with other techniques. -
Use the trust.txt “datatrainingallowed” parameter to declare site-wide data mining restrictions or permissions
The trust.txt specification allows a publisher to declare a single, site-wide data mining reservation with a simple command:datatrainingallowed=no. Sites that already use trust.txt should add this parameter if they want to block their entire site from all AI data training. -
Use the IPTC Photo Metadata Data Mining property on images and video files
Announced previously by the IPTC and developed in collaboration with the PLUS Coalition, the Data Mining property allows asset-level control of data mining preferences. An added benefit is that the opt-out preferences travel along with the content, for example when an image supplied by a picture agency is published by one of their customers. -
Use the CAWG Training and Data Mining Assertion in C2PA-signed images and video files
For C2PA-signed content, a special assertion can be used to indicate data mining preferences. -
Use in-page metadata to declare whether robots can archive or cache page content
HTML meta tags can be used to signal to AI crawlers what should be done with content in web pages. We give specific recommendations in the guidelines. -
Use TDMRep HTML meta tags where appropriate to implement TDM declarations on a per-page basis
The HTML meta tag version of TDMRep can be used to convey rights reservations for individual web pages. -
Send Robots Exclusion Protocol directives in HTTP headers where appropriate
X-Robots-Tag headers to HTTP responses can be used alongside or instead of in-page metadata. -
Use TDMRep HTTP headers where appropriate to implement TDM declarations on a per-URL basis
TDMRep also has an HTTP version, so we recommend that it is used if the top-level tdmrep.json file cannot easily convery asset-level opt-out restrictions.
Feedback and comments welcome
The IPTC welcomes feedback and comments on the guidance. We expect to create further iterations of this document in the future as best practices and opt-out technologies change.
Please use the IPTC Contact Us form to provide feedback or ideas on how we could improve the guidance in the future.
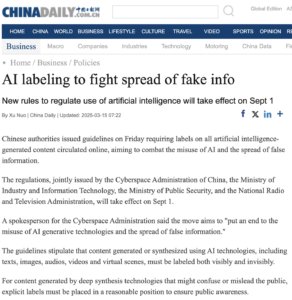
The news outlet China Daily reported on Friday that China will require all AI-generated content to be labelled from September 1st, 2025.
China Daily reports:
Chinese authorities issued guidelines on Friday requiring labels on all artificial intelligence-generated content circulated online, aiming to combat the misuse of AI and the spread of false information.
The regulations, jointly issued by the Cyberspace Administration of China, the Ministry of Industry and Information Technology, the Ministry of Public Security, and the National Radio and Television Administration, will take effect on Sept 1.
A spokesperson for the Cyberspace Administration said the move aims to “put an end to the misuse of AI generative technologies and the spread of false information.”
According to China Daily, “[t]he guidelines stipulate that content generated or synthesized using AI technologies, including texts, images, audios, videos and virtual scenes, must be labeled both visibly and invisibly” (emphasis added by IPTC). This potentially means that IPTC or another form of embedded metadata must be used, in addition to a visible watermark.
“Content identification numbers”
The article goes on to state that “[t]he guideline requires that implicit labels be added to the metadata of generated content files. These labels should include details about the content’s attributes, the service provider’s name or code, and content identification numbers.”
It is not clear from this article which particular identifiers should be used. There is currently no globally-recognised mechanism to identify individual pieces of content by identification numbers, although IPTC Photo Metadata does allow for image identifiers to be included via the Digital Image GUID property and the Video Metadata Hub Video Identifier field, which is based on Dublin Core’s generic dc:identifier property.
IPTC Photo Metadata’s Digital Source Type property is the global standard for identifying AI-generated images and video files, being used by Meta, Apple, Pinterest, Google and others, and also being adopted by the C2PA specification for digitally-signed metadata embedded in media files.
According to the article, “Service providers that disseminate content online must verify that the metadata of the content files contain implicit AIGC labels, and that users have declared the content as AI-generated or synthesized. Prominent labels should also be added around the content to inform users.”
Spain’s equivalent legislation on labelling AI-generated content
This follows on from Spain’s legislation requiring labelling of AI-generated content, announced last week.
The Spanish proposal has been approved by the upper house of parliament but must still be approved by the lower house. The legislation will be enforced by the newly-created Spanish AI supervisory agency AESIA.
If companies do not comply with the proposed Spanish legislation, they could incur fines of up to 35 million euros ($38.2 million) or 7% of their global annual turnover.
 The IPTC has responded to a multi-stakeholder consultation on the recently-agreed European Union Artificial Intelligence Act (EU AI Act).
The IPTC has responded to a multi-stakeholder consultation on the recently-agreed European Union Artificial Intelligence Act (EU AI Act).
Although the IPTC is officially based in the UK, many of our members and staff operate from the European Union, and of course all of our members’ content is available in the EU, so it is very important to us that the EU regulates Artificial Intelligence providers in a way that is fair to all parts of the ecosystem, including content rightsholders, AI providers, AI application developers and end users.
In particular, we drew the EU AI Office’s attention to the IPTC Photo Metadata Data Mining property, which enables rightsholders to inform web crawlers and AI training systems of the rightsholders’ agreement as to whether or not the content can be used as part of a training data set for building AI models.
The points made are the same as the ones that we made to the IETF/IAB Workshop consultation: that embedded data mining declarations should be part of the ecosystem of opt-outs, because robots.txt, W3C TDM, C2PA and other solutions are not sufficient for all use cases.
The full consultation text and all public responses will be published by the EU in due course via the consultation home page.
Tuesday’s IPTC Photo Metadata Conference was a great success. With 12 speakers from the media and software industries and over 200 people registered, it continues to be the largest gathering of photo and image metadata experts globally.
Introduction and welcome, 20 years of IPTC Photo Metadata, Recent work on Photo Metadata at IPTC
We started off with David Riecks and Michael Steidl, co-leads of the IPTC Photo Metadata Working Group, giving an update on what the IPTC has been working on in the areas of photo metadata since the last conference in 2022, along with Brendan Quinn, IPTC Managing Director.
A lot has been happening, including Meta announcing support for IPTC metadata for Generative AI, launching the IPTC Media Provenance Committee and updating the IPTC Photo Metadata User Guide, including our guidance for how to tag Generative AI content with metadata and how to use the DigitalSourceType field.
Panel 1: AI and Image Authenticity
The first panel saw Leonard Rosenthol of Adobe, Lead of the C2PA Technical Working Group; Dennis Walker of Camera Bits, creators of Photo Mechanic; Dr. Neal Krawetz, Computer security specialist, forensic researcher, and founder of FotoForensics; and Bofu Chen, Founder & CTO of Numbers Protocol speak about image provenance and authenticity, covering the C2PA spec, the problems of fraudulent images, what it’s like to implement C2PA technology in existing software, and how blockchain-based systems could be built on top of C2PA to potentially extend its capabilities.
Session on Adobe’s Custom Metadata Panel
James Lockman, Group Manager, Digital Media Services at Adobe demonstrated the Custom Metadata Panel plugin for some Adobe tools (Bridge, Illustrator, Photoshop and Premiere Pro) that allows the full range of IPTC Photo Metadata Standard and IPTC Video Metadata Hub, or any other metadata schema, to be edited directly in Adobe’s interface.
Panel 2: AI-powered asset management
Speakers Nancy Wolff, Partner at Cowan, DeBaets, Abrahams & Sheppard, LLP; Serguei Fomine, Founder and CEO of IQPlug; Jeff Nova, Chief Executive Officer at Colorhythm and Mark Milstein, co-founder and Director of Business Development at vAIsual discussed the impact of AI on copyright, metadata and media asset management.
The full event recording is also available as a YouTube playlist.
Thanks to everyone for coming and especial thanks to our speakers. We’re already looking forward to next year!
The IPTC News Architecture Working Group is happy to announce the release of NewsML-G2 version 2.34.
This version, approved at the IPTC Standards Committee Meeting at the New York Times offices on Wednesday 17th April 2024, contains one small change and one additional feature:
Change Request 218, increase nesting of <related> tags: this allows for <related> items to contain child <related> items, up to three levels of nesting. This can be applied to many NewsML-G2 elements:
- pubHistory/published
- QualRelPropType (used in itemClass, action)
- schemeMeta
- ConceptRelationshipsGroup (used in concept, event, Flex1PropType, Flex1RolePropType, FlexPersonPropType, FlexOrganisationPropType, FlexGeoAreaPropType, FlexPOIPropType, FlexPartyPropType, FlexLocationPropType)
Note that we chose not to allow for recursive nesting because this caused problems with some XML code generators and XML editors.
Change Request 219, add dataMining element to rightsinfo: In accordance with other IPTC standards such as the IPTC Photo Metadata Standard and Video Metadata Hub, we have now added a new element to the <rightsInfo> block to convey a content owner’s wishes in terms of data mining of the content. We recommend the use of the PLUS Vocabulary that is also recommended for the other IPTC standards: https://ns.useplus.org/LDF/ldf-XMPSpecification#DataMining
Here are some examples of its use:
Denying all Generative AI / Machine Learning training using this content:
<rightsInfo> <dataMining uri="http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-AIMLTRAINING"/> </rightsInfo>
A simple text-based constraint:
<rightsInfo> <usageTerms> Data mining allowed for academic and research purposes only. </usageTerms> <dataMining uri="http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEECONSTRAINT" /> </rightsInfo>
A simple text based constraint, expressed using a QCode instead of a URI:
<rightsInfo> <usageTerms> Reprint rights excluded. </usageTerms> <dataMining qcode="plusvocab:DMI-PROHIBITED-SEECONSTRAINT" /> </rightsInfo>
A text-based constraint expressed in both English and French:
<rightsInfo> <usageTerms xml:lang="en"> Reprint rights excluded. </usageTerms> <usageTerms xml:lang="fr"> droits de réimpression exclus </usageTerms> <dataMining uri="http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEECONSTRAINT" /> </rightsInfo>
Using the “see embedded rights expression” constraint to express a complex machine-readable rights expression in RightsML:
<rightsInfo>
<rightsExpressionXML langid="http://www.w3.org/ns/odrl/2/">
<!-- RightsML goes here... -->
</rightsExpressionXML>
<dataMining uri="http://ns.useplus.org/ldf/vocab/DMI-PROHIBITED-SEEEMBEDDEDRIGHTSEXPR"/>>
</rightsInfo>
For more information, contact the IPTC News Architecture Working Group via the public NewsML-G2 mailing list.