Categories
Archives
Defining the boundary between authentic news and synthetic content has never been more critical. In 2025, IPTC didn’t just participate in that conversation—we led it.
Through a record year of new memberships and global events spanning from Juan-les-Pins to New York, we connected thousands of professionals to the future of media technology. Whether through new AI opt-out mechanisms or robust provenance tools, our work is now empowering hundreds of the world’s leading organisations to face the challenges of tomorrow.
Here is a look at the milestones, events, and releases that defined our work in 2025.
Global Connections: A Year of Events
This year, we prioritised bringing the media community together to solve shared challenges. From exclusive member gatherings to public conferences, we held events around the world – and plan to be even more international in 2026. Our events included:
- Member Meetings: We kicked off the year with our Spring Meeting in Juan-les-Pins, France, held alongside CEPIC. It was a vital opportunity to bring IPTC members together and align with the licensed photography world. Later in the year, our Autumn Meeting was held online, allowing our global membership to convene efficiently to discuss strategy and standards updates.
- Media Provenance Series: Trust was a central theme of 2025. We partnered with leading organisations to host a series of high-impact events focused on Media Provenance:
- Paris: Held at the AFP offices, IPTC participated in this event that was organised by AFP along with the BBC and Media Cluster Norway.
- New York: The Content Authenticity Summit was held at the Cornell University campus. IPTC co-hosted the event in association with the Content Authenticity Initiative (CAI) and C2PA.
- Bergen, Norway: A landmark event held in association with Media Cluster Norway, the BBC, and the EBU.
- Photo Metadata Conference: Our annual conference remains a must-attend event for the industry, this year attracting more than 200 attendees to hear from industry legends such as Tim Bray on the technical evolution of visual media.
Critical Guidelines for the AI Era
As Generative AI continues to reshape the landscape, the IPTC provided the industry with the necessary guidance to adapt.
- AI Opt-Out: We published comprehensive guidelines allowing content owners to express their machine learning and data mining preferences, ensuring publishers retain control over how their content is ingested by AI crawlers.
- Implementing C2PA: While the demand for provenance is high, the technical path can be complex. We released specific guidelines on implementing C2PA for news publishers, helping newsrooms bridge the gap between technical specification and practical workflow application.
Powering the Industry: Standards and Tools
We continued to maintain and evolve the technical backbone of the news industry. 2025 saw significant updates across our portfolio to ensure our standards remain modern and accessible.
New Standard Versions We published updated versions of our core standards, including NewsML-G2, IPTC Video Metadata Hub, IPTC Photo Metadata Standard, and ninjs (News in JSON). We also made many updates to the IPTC NewsCodes controlled vocabularies, ensuring that our taxonomies keep pace with a rapidly changing world.
Open Source Tooling To lower the barrier to entry for developers, we expanded our open-source offerings. This year we released a new Python module for NewsML-G2 and a WordPress plugin for C2PA, making it easier than ever for CMS developers and newsrooms to implement IPTC standards directly.
Online Tools Tools such as the Simple Rights Service make it easier than ever for rightsholders to express complex rights statements in the form of simple URLs. And of course our Origin Verify Validator allows anyone to inspect content signed with C2PA metadata, including all of the metadata fields recommended by IPTC and showing when the publisher that signed the content is on the Origin Verified News Publishers List.
Be Part of the Future
As we look toward 2026, the intersection of AI, provenance, and metadata will only become more critical.
If you want to be part of the conversation rather than just following it, we invite you to join us. By becoming an IPTC member, you can contribute to the standards that run the global news ecosystem and network with the technical leaders of the world’s biggest media organisations.
Become a Member of IPTC and help us build the future of media standards
We would like to thank our members, Working Group leads, volunteers and invited experts for their contributions to IPTC’s vital work this year. We look forward to many more years of defining and influencing technology standards for the media and beyond.
IPTC member France Télévisions has started signing its daily news broadcasts using C2PA and FranceTV’s C2PA certificate, which is on the IPTC Origin Verified News Publisher List.
This makes France TV the first news provider in the world to routinely sign its daily news output with a C2PA certificate.
The work won FranceTV the EBU Technology & Innovation Award this year.
IPTC has assisted FranceTV in this work and continues to work with FranceTV along with other broadcasters and publishers on signing their content using the C2PA specification.
A specific page Retrouvez nos JT certifiés (“Find our certified news programmes”) is available on FranceTV’s site franceinfo.fr, where the latest 1pm and 8pm news programmes are published containing a C2PA signature. The page Pour vous informer en toute sécurité contains more information (in French) about FranceTV’s work on transparency and authenticity.
We congratulate FranceTV for their work and look forward to further collaboration in 2026 and beyond.

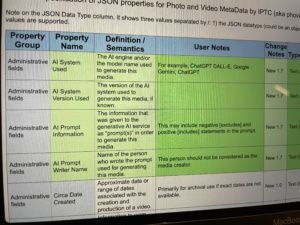
The IPTC Photo Metadata Working Group has released version 2025.1 of the IPTC Photo Metadata Standard, including properties that can be used for AI-generated content.
The new properties are:
- AI System Used
Definition: The AI engine and/or the model name used to generate this image.
User Note: For example, ChatGPT DALL-E, Google Gemini, ChatGPT
Suggest help text: Enter the name of the AI system and/or the model name used to generate this image. - AI System Version Used
Definition: The version of the AI system used to generate this image, if known.
Suggested help text: Enter the name or number of the version of the AI system used to generate this image. - AI Prompt Information
Definition: The information that was given to the generative AI service as “prompt(s)” in order to generate this image.
User Note: This may include negative [excludes] and positive [includes] statements in the prompt.
Suggested help text: Enter the information given to the generative AI service as “prompt(s)” in order to generate this image. - AI Prompt Writer Name
Definition: Name of the person who wrote the prompt used for generating this image.
User Note: This person should not be considered as the image creator.
Suggested help text: Enter the name of the person who wrote the prompt used for generating this image.
IPTC’s specification materials have been updated to accommodate the new properties:
- IPTC Photo Metadata Standard Specification 2025.1
- The IPTC Photo Metadata User Guide has been updated, particularly the guidance on Applying Metadata to AI-generated images
- The IPTC Photo Metadata Reference Image 2025.1 which contains values for all IPTC Photo Metadata properties, including the four properties added in version 2025.1
- IPTC Photo Metadata TechReference:
- The GetPMD photo metadata reading tool has been updated to read the new fields.
{kind=link}
The new properties are expected to be implemented in software tools soon. The popular open-source tool Exiftool already supports the new properties, since version 13.40 which was released on October 24th 2025.
Thanks to everyone who contributed to our request for comments on these new properties. We made several changes based on feedback from IPTC members and others, so your contributions were well appreciated.
For more information please contact IPTC or join our public iptc-photometadata@groups.io mailing list.
The IPTC News in JSON Working Group today released the latest in each version of the ninjs: 3.2, 2.3 and 1.7.
ninjs is IPTC’s standard for storage and distribution of news in JSON format. Using JSON means that ninjs works well for fast and simple exchange of news content for APIs, search engine platforms such as Elasticsearch and AWS OpenSearch, and for lightweight storage in databases, CMSs and cloud storage. It can be used to distribute news content in any format such as text, audio, video or images; can handle event and news coverage planning, rich metadata descriptions including relevant people, places, subjects and events; and can include packages of related news content via an associations mechanism.
The IPTC News in JSON Working Group maintains three parallel versions of ninjs so that those who implement the 1.x, 2.x or 3.x branch can all receive the latest additions in a backwards-compatible manner.
The changes adopt a new structure within the renditions array. Each rendition can now have resources associated, which allows a ninjs feed to express multiple channels or tracks within a media stream. For example, a live video stream from the EU Parliament may include several different audio tracks featuring live translations in different spoken languages; a subtitle track in WebVTT or TTML format, audio description tracks and more.
The changes have been added to all three versions of ninjs in accordance with the conventions of each version.
- https://www.iptc.org/std/ninjs/ninjs-schema_3.2.json
- https://www.iptc.org/std/ninjs/ninjs-schema_2.3.json
- https://www.iptc.org/std/ninjs/ninjs-schema_1.7.json
The ninjs User Guide, ninjs Generator tool has also been updated for the new version.
For any comments or suggestions for new properties that we should add to future versions of ninjs,
The IPTC Video Metadata Working Group is happy to announce that version 1.7 of its flagship standard, Video Metadata Hub, has now been released.
The new version has four new properties which allow users and tools to embed metadata about AI prompt information that was used to generate the image, if applicable.
The new properties in detail are:
- AI System Used (text string, single-valued, optional)
The AI engine and/or the model name used to generate this media.
Note: For example, ChatGPT DALL-E, Google Gemini, ChatGPT - AI System Version Used (text string, single-valued, optional)
The version of the AI system used to generate this media, if known. - AI Prompt Information (text string, single-valued, optional)
The information that was given to the generative AI service as “prompt(s)” in order to generate this media.
Note: This may include negative [excludes] and positive [includes] statements in the prompt. - AI Prompt Writer Name (text string, single-valued, optional)
Name of the person who wrote the prompt used for generating this media.
Note: this person should not be considered as the media creator.
Please note that users should not expect that the contents of the “AI Prompt Information” property could be given directly to an AI system to generate the same video; there are many reasons why generated media files differ even for the same input information. The Working Group decided to add “AI Prompt Information” as a generic property that creators could use to describe the process that was used to prompt an AI system to create the content.
The official IPTC Video Metadata Hub recommendation files and user documentation have all been updated for the new version:
- IPTC Video Metadata Hub 1.7 properties table
- IPTC Video Metadata Hub 1.7 full mappings table
- IPTC Video Metadata Hub 1.7 user guide
- IPTC Video Metadata Hub generator – A tool that can help developers to understand how Video Metadata Hub works and to generate example files
- IPTC Video Metadata Hub 1.7 JSON Schema
The Video Metadata Working Group welcomes feedback. Please post to the IPTC Video Metadata public discussion group or use the IPTC Contact Us form.
Last week saw the 60th Annual General Meeting of IPTC, held as part of the IPTC Autumn Meeting 2025. The event was held online from Tuesday 14th to Thursday 16th October.
As one could imagine, AI was the hot topic, being mentioned in almost every presentation.
Highlights included:
- Hearing the latest on the TEMS Media Dataspace project, including an overview of the data model, which is of interest to IPTC members due to its mappings to many IPTC standards;
- Hearing the latest from the IPTC Media Provenance Committee and its three working groups, with updates on the Verified News Publisher List and the recent Media Provenance Summits;
- A presentation on “vibe coding” and AI-assisted development, including it being used to update many of IPTC’s tools and services;
- Discussions on a possible new publisher metadata best practice, an update on our AI preferences work and the IETF AI Preferences Working Group;
- We also heard from StoryGo, Copyright Exchange, Global Media Identifier, Time Addressable Media Store, and the IBC Accelerator “Stamping Your Content” project that focused on bringing C2PA metadata to broadcast video content, with many IPTC member organisations as participants.
At the Standards Committee meeting, members voted to approve three new IPTC standard versions: Video Metadata Hub 1.7, Photo Metadata 2025.1, and ninjs version updates. The Photo and Video Metadata updates are to add new properties for AI Prompts and AI models used to create synthetic content. The ninjs updates were to add “resources” to renditions, to cover for example multiple audio tracks or a subtitle feed as part of a live video stream. These updates will be announced separately when they are published.
At the 2025 Annual General Meeting, the Board was re-elected by all Voting Members. Members heard updates from IPTC Managing Director Brendan Quinn and the Chair of IPTC’s Board of Directors, Robert Schmidt-Nia. The 2026 budget was approved and a change to IPTC’s Articles of Association was voted through.
Thanks very much to all who participated and presented their work, and to all IPTC Working Group and Committee members who contributed to the event.
We’re already looking forward to the IPTC Spring Meeting 2026, which will be held in Toronto, Canada, hosted by Thomson Reuters.
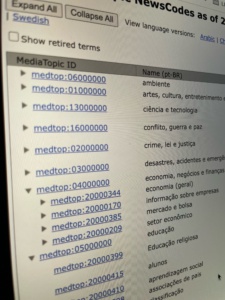
The NewsCodes Working Group is pleased to release the Q3 2025 update to our NewsCodes vocabularies.
MediaTopics updates
As usual most of the updates are to the Media Topic vocabulary.
New concepts (3)
Retired concepts (1)
- water –
Label changes (3)
- hazardous materials -> hazardous material
- waste materials -> waste material
- pests -> pest and pest control
Definition changes (16)
- environment
- environmental pollution
- air pollution
- environmental clean-up
- hazardous material
- water pollution
- nature
- ecosystem
- endangered species
- invasive species
- animal disease
- plant disease
- animal
- flowers and plants
- pest and pest control
- sustainability
Modified notes (2)
animal disease,
pest and pest control
No concepts were retired, had hierarchy moves or modified wikidata mappings this time.
Translation updates
Many terms and definitions in the German translation were updated to reflect recent changes in the English versions.
Norwegian and Swedish terms were updated to reflect recent changes in the English versions.
2025-Q2 updates recap
It seems that we didn’t post a news item about the 2025-Q2 changes to Media Topics. Here’s a summary:
- New term vegetarianism and veganism
- climate change – definition changed
- global warming retired. Use climate change instead.
- conservation – definition changed
- energy saving – retired. Use medtop:20001374 sustainability instead.
- parks -> nature preserve
- New Term: park and playground (Child of leisure venue medtop:20000553)
- natural resources -> natural resource
- energy resources retired. Use the relevant term from the business branch instead.
- land resources retired.
- forests -> forest. Moved to be child of nature.
- mountains -> mountain. Moved to be child of nature.
- population growth – retired. Use “population and census” instead.
- oceans -> ocean. Moved to be child of nature.
- rivers -> river. Moved to be child of nature.
- wetlands -> wetland. Moved to be child of nature.
- mankind -> demographic group.
Trust Indicator updates
The Trust Indicator vocabulary had one hierarchy change: factCheckingPolicy was made a child of editorialPolicy.
Also, the notes on terms have been updated to give credit to The Trust Project for their work and to indicate that the term “Trust Indicators®” is now a registered trademark of The Trust Project.
Working with IPTC NewsCodes
See the official Media Topic vocabulary on the IPTC Controlled Vocabulary server, and an easier-to-navigate tree view. An Excel version of IPTC Media Topics is also available. Other NewsCodes are available via the CV Server .
See the IPTC NewsCodes Guidelines document for information on our vocabularies and how you can use them in your projects.
IPTC’s Python library for creating manipulating and managing NewsML-G2 documents, python-newsmlg2, has reached version 1.0.
The earliest versions of the library were created back in 2021, but the code has seen significant changes over that period and we are happy to endorse the latest version as a production-ready 1.0 release.
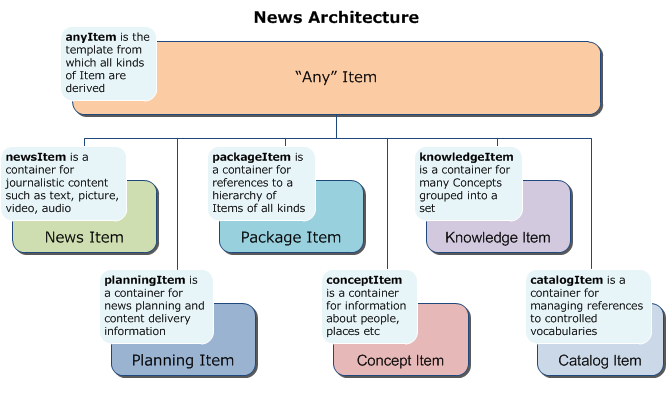
Created as free, open source library that can be integrated into any Python code, the library supports all parts of the NewsML-G2 specification:
- multi-media news stories (NewsItem)
- packages of news content (PackageItem)
- planned news coverage and information about upcoming and past events (PlanningItem and EventsML-G2)
- news content classification concepts and sets of concepts (knowledge graphs) (ConceptItem, KnowledgeItem and CatalogItem)
- syndicated news content transactions (NewsMessage)
The 1.0 version has 98% unit test coverage, which can give users confidence that future changes will not introduce regression bugs.
The code can also handle non-NewsML-G2 content embedded within NewsML-G2 files using XML Schema’s “xs:any” construct. This is a feature of NewsML-G2 that allows any type of markup, such as but not limited to XHTML, NITF or RightsML, to be carried as the payload in a NewsML-G2 NewsItem. The 1.0 version adds “round-trip” support of all xs:any constructs allowing additional markup to be captured, retained and output verbatim, without any loss of fidelity.
The library’s documentation also gives examples of how the library can be used to create, process, manipulate and output NewsML-G2 documents.
The code offers some “helper functions” that make working with NewsML-G2 easier, such as:
- Automatic resolution between QCodes and URIs, two equivalent formats for controlled vocabulary terms, that can now be used interchangeably. The code uses NewsML-G2 Catalogs to look up QCode prefixes and resolve them to URI format.
- Automatic handling of repeatable items and traversal of the NewsML-G2 element structure to provide easy access to child elements such as “
digsrctype = newsitem.contentmeta.digitalsourcetype.uri“
The library can be installed by any Python user using PyPI: pip install newsmlg2.
The source code of the library is freely available, licensed under the open-source MIT licence, at https://github.com/iptc/python-newsmlg2.
Feedback on the library is very welcome. Please let us know what you think on the IPTC Contact Us page or the public NewsML-G2 discussion list.
Software industry legend Tim Bray gave a resounding call to IPTC and to others working on media provenance and C2PA: his verdict was that while the specification and its implementation had issues, they were slowly being resolved and he lauded the project’s goal of, in Tim’s words, “making it harder for liars to lie and easier for truth tellers to be believed”.
The 2025 Photo Metadata Conference, held on September 18th, was a great success, with 280 registered attendees from hundreds of organisations around the world. Video recordings from the event are now available.
Speakers included:
- David Riecks, lead of the IPTC Photo Metadata Working Group, describing some new IPTC Photo Metadata properties concerning Generative AI models and prompts that will be proposed for a vote at the next Standards Committee meeting to be held at the IPTC Autumn Meeting.
- Brendan Quinn, Managing Director of IPTC, gave an update on the IPTC’s guidelines for opting out of Generative AI training and ongoing work to standardise AI training preferences at the Internet Engineering Task Force (IETF)
- Ottar A. B. Anderson, Head of Photography at SEDAK, the GLAM imaging service of Møre og Romsdal County in Norway, spoke about Metadata for Image Quality in Galleries, Libraries, Archives and Museums (GLAM) and his work on the Digital Object Authenticity Working Group.
- David Riecks gave an update on IPTC Photo Metadata Panel in Adobe Custom Metadata.
- AI caption tagging for the Superbowl – Jerry Lai, Senior Director of Content, Imagn Images – Download Jerry’s slides
- Paul Reinitz, previously with Getty Images and now a consultant on business and legal issues around copyright, spoke about recent developments in the area including updates in the US, EU and China
- Brendan Quinn spoke again to give an update on the IPTC’s work with C2PA and the world of Media Provenance, including our work on the Verified News Publishers List
- Tim Bray, creator of tech standards like XML and Atom and companies like OpenText
- Marcos Armstrong of CBC / Radio Canada spoke about his work on mapping image publishing workflows at CBC.
Feedback from the event was almost universally positive:
- “While I knew I wouldn’t understand all of the terms, I was so impressed the amount of topics that were touched upon. I had no problem following along. I loved the passion and the openess to different perspectives”
- “Great topic choices- perfect level of beginner/more advanced content presentation.”
- “It was a good critical look at the pluses and minuses of various decisions being made, ultimately pointing to developing public trust about authorship.”
- “Informative, I really liked the expertise all the speaker brought to the virtual table”
- “Learning about strategies to protect from and tools for blocking AI, as well as metadata fields to record AI use”
- “Informative, good presentations and presenters. Very relevant to today – AI.”
- “Focus on Content Credentials and AI. Range of speaker roles provided different perspectives on the topic area. Excellent organization, presentation quality and management of the zoom space.”
- “Three things in particular stood out. Tim Bray’s talk was great as it brought everything to my world as a photographer and is pretty much what I’ve found. Brendan Quinn’s opt out information was definitely worth knowing and now I’m going to look at it. Finally, David Riecks talk about Adobe’s Metadata Panel gave me more insight into it and if it should be included in my workflow but his information for the proposed new properties for Generative AI was very good to hear.”
Thanks to everyone who attended and to our speakers David, Brendan, Paul, Ottar, Tim and Marcos.
Special thanks to David and the IPTC Photo Metadata Working Group for organising the event.
We look forward to seeing even more attendees next year!
To be sure of being notified about next year’s event, subscribe to the (very low volume) “Friends of IPTC Newsletter”.