Categories
Archives
IPTC Managing Director Brendan Quinn spoke at the FIBEP World Media Intelligence Congress 2020 on Wednesday 18th November.
FIBEP is the industry body for the “media intelligence” industry, including media monitoring, public relations and marketing organisations.
FIBEP was founded over 65 years ago (so it is even older than IPTC!) and the FIBEP World Media Intelligence Congress has become one of the largest events for communications, public relations, technology, social media monitoring and marketing professionals alike. It brings together communications professionals from around the world to share best practices, discuss industry developments and innovations, present the latest technology and network through a variety of presentations and panel discussions from industry leaders. So it is in many ways similar to IPTC for the technical side of the news industry.
This year’s theme was Exploring and Expanding the Media Intelligence World and the program included a wide range of best practices and topics relevant for media intelligence and communication professionals including social media monitoring, privacy, and data integrity, copyright, the evolution of data consumption, measurement, PR trends, technological developments and future outlooks for communications and media intelligence industries.
Brendan was invited to speak about IPTC’s view of the news ecosystem, particularly with a view to online misinformation and disinformation and how the news industry can work together to combat those problems. Brendan discussed IPTC’s work on trust and credibility, including the content of the recent IPTC webinar on Trust and Credibility.
Questions from the media intelligence community included what individuals could do to avoid misinformation and spreading false news on social media. Brendan’s advice to those who want to learn more about misinformation are in the table:
Educate your teams to “think before you share” on social media |
|
Reuters has put together a course on “manipulated media” including “deep fake” videos: https://www.reuters.com/manipulatedmedia The EU has created a “Think before you share” campaign: https://euvsdisinfo.eu/think-before-you-share/ |
Stay in touch with fact checking organisations |
| Fact checking organisations such as FullFact, PolitiFact, FactCheck.org and Snopes often release information about topics that are often the subject of disinformation and misinformation such as vaccines, elections and conspiracy theories. Many local organisations can be found via the International Fact-Checking Network. |
Thanks very much to FIBEP, especially Romina Gersuni, for inviting us to present. We realised during the preparations for the event that IPTC and FIBEP have a lot in common, so hopefully this will be the first of many collaborations between the two organisations!
 It is with great sadness that we report that Andrew Read passed away suddenly on Sunday 8 November, 2020.
It is with great sadness that we report that Andrew Read passed away suddenly on Sunday 8 November, 2020.
Andy was a passionate member of the IPTC for over 20 years, first through Reuters, then Thomson Reuters and most recently as the BBC’s main representative at the IPTC.
Andy contributed to NewsML-G2 and the IPTC News Architecture, RightsML and other rights-related work, and followed our other work including Photo Metadata and our sports standards. A frequent attendee and speaker at our face-to-face IPTC member meetings, Andy also helped to organise IPTC’s London meetings, including the special Rights Day in 2013 and Rights Management in News day in 2017.
A committed believer in the benefit of industry organisations, he also contributed to the EBU’s metadata activities and organised collaborations with the DPP. Just a few weeks ago at the IPTC Autumn 2020 Meeting, Andy presented his most recent project at the BBC, an adaptation of the Guardian’s open-source digital asset management system for use as the BBC’s main image asset library. He was always making connections between IPTC members and outside organisations, research projects and startups, and loved bringing people together to discuss what technology can bring to the media industry.
Andy will be fondly remembered by all of his IPTC colleagues for his friendly, supportive manner and willingness to help anyone with anything.
When IPTC members get together it often feels like a family reunion, and Andy has been a key part of the IPTC family for the past 20 years. He will be sorely missed.
UPDATE: If you would like to share your memories of Andy or make a donation to his preferred charity, please see the tribute site: https://andyread.muchloved.com/
We’re very happy that we can make public some of the video recordings from the recent IPTC Photo Metadata Conference 2020, held on Tuesday 13 October 2020.
Thanks to all who attended – we had over 200 registrations for the webinar.
The videos are embedded below or can be viewed directly on YouTube by following the link above the embedded video.
Introduction
Brendan Quinn, Managing Director of IPTC, opened the day with an introduction to IPTC and an overview of what was to come (10 minutes):
Michael Steidl, Photo Metadata WG lead on IPTC Photo Metadata
Michael Steidl presented on why we should care about photo metadata in his presentation “About IPTC Photo Metadata” (48 minutes including Q&A)
Google’s Licensable Images features
Francois Spies, a Product Manager for Google Images in Mountain View, presented on the Licensable Images features which they developed in consultation with IPTC this year.
After Francois’ presentation, Matthew O’Such, VP SEO for Getty Images and Marcin Czyzewski, CTO and Picturemaxx joined us to share their views on implementing the changes to IPTC Photo Metadata required to power the Google Licensable Images feature. Then we had a Q&A session including Michael, Francois, Matthew and Marcin.
Unfortunately, Google asked us not to make a recording of their presentation or the panel available. However the resources that Francois shared are all available via our Quick Guide to IPTC Photo Metadata and Google Images.
Andy Parsons on the Content Authenticity Initiative
Next up, Andy Parsons (Adobe) introduced the Content Authenticity Initiative (47 minutes including Q&A and a wrap-up of the day from Brendan Quinn):
Thanks again to all our speakers and panellists for their contributions. We’re already looking forward to next year’s event!
Currently next year’s IPTC Photo Metadata Conference is scheduled to be in late May 2021 in Mallorca, Spain in conjunction with the CEPIC Congress 2021. If that proves impractical then we will host another online event.
The Digital Media Licensing Association (DMLA) is holding its annual conference this week. IPTC and IPTC members have a strong presence – particularly IPTC’s Video Metadata Hub.

Mark Milstein of IPTC member Microstocksolutions joined in hosting the opening “virtual cocktail party” on Sunday 25 October. Mark is leading efforts to promote IPTC’s Video Metadata Hub at DMLA, see his recent post on DMLA’s site.
Angela Weiss, a staff photographer with IPTC member Agence France-Presse, took part in a panel “Tales from the Trenches – True Stories from Working Photojournalists” on Monday. Then Mark Milstein was back on the “Hot Topics in Tech” panel along with Matthew O’Such of IPTC member Getty Images. Matthew also spoke on our panel at the IPTC Photo Metadata Conference two weeks ago.
On Tuesday, Andy Parsons of IPTC member Adobe is presenting a keynote on the Content Authenticity Initiative. Of course IPTC members already heard Andy speak at the Photo Metadata Conference, and at the Adobe MAX conference last week. Andy is very busy getting the word out!
On Wednesday, Mathieu Desoubeaux of new IPTC member IMATAG speaks on the “Image Protection – Creating a More Secure Ecosystem” panel.
On Thursday, Matthew O’Such of Getty Images is back along with Francois Spies of Google giving a reprise of his IPTC Photo Metadata Conference talk on the Google search “Licensable Images” features. Also on the panel is Roxana Stingu of Alamy, part of IPTC member PA Media.
Thursday afternoon, IPTC metadata gets a front-row seat at DMLA with the “Taming Video Metadata” panel, moderated by Mark Milstein of Microstocksolutions and featuring a presentation by Pam Fisher, IPTC individual member and lead of the IPTC Video Metadata Working Group. On the panel, Zach Bernstein of Storyblocks will be speaking about his implementation of IPTC’s Video Metadata Hub.
The conference also features panels on synthetic content, the legal aspects of the photo licensing industry, artificial intelligence and more.
Thanks to DMLA for putting together such an interesting event!
We had a great IPTC Member Meeting last week, our second online event. We’re getting used to online events now!
After introductions and a get-to-know-your-fellow-members session, Dave Compton of Refinitiv presented the NewsML-G2 Working Group‘s report. We didn’t have a new version of NewsML-G2 this time but we are doing work on making NewsML-G2 easier to understand and to use. We have been working on a NewsML-G2 Generator (soon to be launched), NewsML-G2 unit tests and a Python module. Some proposals for additions to NewsML-G2 were also discussed.
Brendan Quinn, IPTC Managing Director then hosted a re-introduction to semantic web technology: RDF, SPARQL, schema.org and how they relate to GraphQL, knowledge graphs and other buzzwords in 2020’s world of data. This proved to be a useful background and refresher for many of the following sessions over the next three days that touched upon semantic technology in almost every presentation!
Paul Kelly, individual member and group lead, presented the Sports Content Working Group‘s report highlighting the work that the group is pursuing on looking at a more semantically rich successor to SportsML.
Jennifer Parrucci of The New York Times presented the NewsCodes Working Group report. The focus since the last meeting was on a new batch of Media Topics terms, refreshing some labels and definitions, and adding more translations – we are now up to 11 languages in the Media Topics vocabulary! We have also updated the Genres vocabulary and launched the Trust Indicators CV.
Still on metadata and controlled vocabularies, we hosted a presentation and discussion session about Named Entities for News, including presentations by IPTC members Christoffer Krona from iMatrics, Jennifer Parrucci from The New York Times and Jeremy Tarling from BBC showing their organisations’ approach to managing metadata for named entities such as people, places and organisations. We had an interesting discussion about how IPTC can help the industry to move forward in managing named entities. Look out for more information from us soon!
On Tuesday, we started with Michael Steidl‘s Photo Metadata Working Group presentation, including a report on how the Google Licensable Images work has been received. Pam Fisher, lead of the Video Metadata Working Group then presented ongoing work towards a new user guide for video metadata, based on use cases and scenarios so we can make video metadata more approachable for people in different parts of the media industry.
Johan Lindgren of TT Nyhetsbyrån presented the work of the News in JSON Working Group, including discussions of work towards a ninjs 2.0, looking at how ninjs can map to binary serialisation formats such as Protocol Buffers and Avro, and support for machine-readable rights in ninjs documents.
The second half of Tuesday was filled by the IPTC Photo Metadata Conference 2020 – see our separate news post about that event!
Wednesday morning was dedicated to important IPTC internal business, including the IPTC 2020 Annual General Meeting, where we re-elected the current board including Robert Schmidt-Nia of DATAGROUP as IPTC Chair. Linda Burman, individual member and Chair of the PR Committee,
We also held the Autumn 2020 IPTC Standards Committee Meeting, chaired by Stéphane Guérillot of Agence France-Presse, where we discussed our ongoing project to “make IPTC standards more usable”. If you have any ideas about how we can make our work more usable or more accessible, please get in touch!
We ended the day with presentations from Laurent Le Meur of EDRLab, Steve Callanan of WireWax presenting their video analysis and manipulation tools, and Andy Read of the BBC speaking about their implementation of the GRID open source image management system.
IPTC members can find PDFs of all presentation files on the members-only event page.
 The IPTC Autumn Meeting 2020 will take place next week, from Monday 12 October to Wednesday 14 October. The meeting will be held online using the Zoom platform, as we did for the IPTC Spring Meeting in May.
The IPTC Autumn Meeting 2020 will take place next week, from Monday 12 October to Wednesday 14 October. The meeting will be held online using the Zoom platform, as we did for the IPTC Spring Meeting in May.
Over 30 IPTC member organisations will be represented, with more still finalising their attendance.
Presentations will range from Working Group updates and our 2020 Annual General Meeting to presentations from invited startups, discussions on IPTC participation in industry projects, and exciting presentations from members on relevant projects within their companies.
The IPTC Photo Metadata Conference 2020 is “co-located” with the IPTC Autumn Meeting – so we will be moving from the member meeting to the Photo Metadata Conference on the Tuesday afternoon.
Attendance is free for IPTC members. If you are not already registered, please go to the Members-Only event page to register.
![]() We are very happy to announce that this year’s IPTC Photo Metadata Conference will be conducted fully online, and for the first time ever, is free for all to attend.
We are very happy to announce that this year’s IPTC Photo Metadata Conference will be conducted fully online, and for the first time ever, is free for all to attend.
This year’s conference takes place on Tuesday October 13, 2020 from 15:00 – 18:00 UTC time (see times in other timezones below).
We have some very special guests for this year’s conference:
 Michael Steidl, Lead of the IPTC Photo Metadata Working Group, will introduce IPTC Photo Metadata, and discuss recent developments, and what we see in the future of photo metadata.
Michael Steidl, Lead of the IPTC Photo Metadata Working Group, will introduce IPTC Photo Metadata, and discuss recent developments, and what we see in the future of photo metadata.
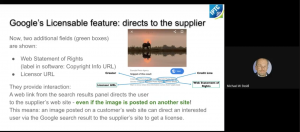
 Francois Spies, Product Manager, Google Images will present Google’s recent work on the “Licensable Images” project, which adds a “licensable” badge to images in Google search results, and links from the image preview panel in search results pages directly back to a place where users can obtain a licence to re-use the image.
Francois Spies, Product Manager, Google Images will present Google’s recent work on the “Licensable Images” project, which adds a “licensable” badge to images in Google search results, and links from the image preview panel in search results pages directly back to a place where users can obtain a licence to re-use the image.
 Andy Parsons, Director of Content Authenticity Initiative, Adobe will present the Content Authenticity Initiative, which is “designing components and drafting standards specifications for a simple, extensible and distributed media provenance solution.”
Andy Parsons, Director of Content Authenticity Initiative, Adobe will present the Content Authenticity Initiative, which is “designing components and drafting standards specifications for a simple, extensible and distributed media provenance solution.”
How will the Content Authenticity Initiative work? What work has been done so far and what still needs to be done? How can you help?
Please register here via Zoom – it’s free!
The IPTC Photo Metadata Conference has been held in conjunction with the CEPIC Congress for many years. The 2020 CEPIC Congress has been postponed to 19 to 21 May 2021, but with so much going on in the world of image metadata, we didn’t want to miss out on the opportunity, so we are holding a virtual event this year. We look forward to joining CEPIC again next year, hopefully in Mallorca in May 2021.
IPTC Photo Metadata Conference 2020: times around the world
- UTC / GMT: Weds 13 October, 1500 – 1800 UTC
- London: Weds 13 October, 1600 – 1900 BST
- Paris, Berlin, Amsterdam, Vienna: Weds 13 October, 1700 – 2000 CEST
- Helsinki, Dubai, Tallinn: Weds 13 October, 1800 – 2100 EEST
- New York, Toronto: Weds 13 October, 1100 – 1400 EDT
- Beijing, Shanghai: Weds 13 October, 2300 – Thurs 14 October, 0200
When you register for the webinar on Zoom you will be sent a calendar invitation so you can make sure you attend at the right time!
Through our work with The Trust Project, Reporters Sans Frontières’ Journalism Trust Initiative, Credibility Coalition and others, we have been able to create extensions to IPTC standards to enable news organisations to express various “Trust Indicators”.
Learn more about how this works and how it can lead to a more trustworthy news media.
Register for the webinar here via Zoom
UPDATE: The webinar has now ended, but you can view the recording by registering on the link above.
For information on other World News Day events, please see the main site at https://worldnewsday.org/
![]() The IPTC is excited to announce a new membership category aimed exclusively at tech startups working in the news and media industry.
The IPTC is excited to announce a new membership category aimed exclusively at tech startups working in the news and media industry.
The International Press Telecommunications Council is the community of leading members of the news, media and technology industries who share ideas and create technical standards that drive the industry forward.
The IPTC works across a broad range of technical areas in the news and media industry: from multi-media news syndication, to subject taxonomies used to classify news content, embedded image standards, machine-readable rights and semantic web standards.
Until now, IPTC members have mostly been large media companies (such as Bloomberg, Associated Press, Agence France Presse, Deutsche Press Agentur, Reuters News & Media, New York Times, and the BBC), large companies in the photo industry (Getty Images, Shutterstock, Visual China Group) and key technology vendors that serve the media industry (Adobe, Sourcefabric and Fotoware).
But today, more than ever, key innovations in the media industry come from large established companies and small startups working together.
Therefore, the IPTC has created a new membership category: Startup Membership.
With the new membership category, IPTC will become the forum where large and small companies can connect to share ideas, to start projects and to collaborate on creating standards for information exchange.
The IPTC regularly collaborates with all parts of the media industry plus standards organisations such as ISO and W3C and organisations in related industries such as CEPIC and camera manufacturers organisation CIPA. We also work with huge platforms such as Google, Facebook and Twitter. This new membership category will bring startup members into those conversations.
For more details, please get in touch with IPTC Managing Director Brendan Quinn at mdirector@iptc.org. Fees will vary depending on criteria such as the age and funding status of your startup.
We are excited to see the creative projects and new innovations that will emerge from the combination of startups with larger organisations in the IPTC community.
— Robert Schmidt-Nia, Chair of the Board, IPTC
 Michael Steidl, Lead of the IPTC Photo Metadata Working Group, spoke on a workshop panel at the Perpignan Photojournalism Conference “Visa Pour L’Image”.
Michael Steidl, Lead of the IPTC Photo Metadata Working Group, spoke on a workshop panel at the Perpignan Photojournalism Conference “Visa Pour L’Image”.
The panel session was pre-recorded and released this week.
This joint workshop from Google, IPTC and Alamy covers some product updates from Google Images, including Image Rights Metadata and the new features on Google Images highlighting licensing information for images that we announced earlier this week. The speakers share best practices and experience on these features.
The speakers are:
- John Mueller, Google Senior Webmaster Trends Analyst
- Michael Steidl, IPTC working group lead
- Roxana Stingu, Alamy SEO Head