Categories
Archives
The Digital Media Licensing Association (DMLA) is holding its annual conference this week. IPTC and IPTC members have a strong presence – particularly IPTC’s Video Metadata Hub.

Mark Milstein of IPTC member Microstocksolutions joined in hosting the opening “virtual cocktail party” on Sunday 25 October. Mark is leading efforts to promote IPTC’s Video Metadata Hub at DMLA, see his recent post on DMLA’s site.
Angela Weiss, a staff photographer with IPTC member Agence France-Presse, took part in a panel “Tales from the Trenches – True Stories from Working Photojournalists” on Monday. Then Mark Milstein was back on the “Hot Topics in Tech” panel along with Matthew O’Such of IPTC member Getty Images. Matthew also spoke on our panel at the IPTC Photo Metadata Conference two weeks ago.
On Tuesday, Andy Parsons of IPTC member Adobe is presenting a keynote on the Content Authenticity Initiative. Of course IPTC members already heard Andy speak at the Photo Metadata Conference, and at the Adobe MAX conference last week. Andy is very busy getting the word out!
On Wednesday, Mathieu Desoubeaux of new IPTC member IMATAG speaks on the “Image Protection – Creating a More Secure Ecosystem” panel.
On Thursday, Matthew O’Such of Getty Images is back along with Francois Spies of Google giving a reprise of his IPTC Photo Metadata Conference talk on the Google search “Licensable Images” features. Also on the panel is Roxana Stingu of Alamy, part of IPTC member PA Media.
Thursday afternoon, IPTC metadata gets a front-row seat at DMLA with the “Taming Video Metadata” panel, moderated by Mark Milstein of Microstocksolutions and featuring a presentation by Pam Fisher, IPTC individual member and lead of the IPTC Video Metadata Working Group. On the panel, Zach Bernstein of Storyblocks will be speaking about his implementation of IPTC’s Video Metadata Hub.
The conference also features panels on synthetic content, the legal aspects of the photo licensing industry, artificial intelligence and more.
Thanks to DMLA for putting together such an interesting event!
Through our work with The Trust Project, Reporters Sans Frontières’ Journalism Trust Initiative, Credibility Coalition and others, we have been able to create extensions to IPTC standards to enable news organisations to express various “Trust Indicators”.
Learn more about how this works and how it can lead to a more trustworthy news media.
Register for the webinar here via Zoom
UPDATE: The webinar has now ended, but you can view the recording by registering on the link above.
For information on other World News Day events, please see the main site at https://worldnewsday.org/
 Michael Steidl, Lead of the IPTC Photo Metadata Working Group, spoke on a workshop panel at the Perpignan Photojournalism Conference “Visa Pour L’Image”.
Michael Steidl, Lead of the IPTC Photo Metadata Working Group, spoke on a workshop panel at the Perpignan Photojournalism Conference “Visa Pour L’Image”.
The panel session was pre-recorded and released this week.
This joint workshop from Google, IPTC and Alamy covers some product updates from Google Images, including Image Rights Metadata and the new features on Google Images highlighting licensing information for images that we announced earlier this week. The speakers share best practices and experience on these features.
The speakers are:
- John Mueller, Google Senior Webmaster Trends Analyst
- Michael Steidl, IPTC working group lead
- Roxana Stingu, Alamy SEO Head
The IPTC is very happy to announce that as a result of our collaboration with Google and CEPIC, Google Images’s new licensable badge and other related features are now live.
This means that when photo owners include a photograph’s Web Statement of Rights (also known as Copyright Info URL) in an image’s embedded metadata, Google will display a “Licensable” badge on the image in Google Images search results and the image will appear when the “View all images with Commercial or other licenses” filter is selected. If the Licensor URL is also added, Google will feature a “get this image on” link that takes users directly to a page on the photo owner’s site enabling the user to easily obtain a license to re-use the image elsewhere.
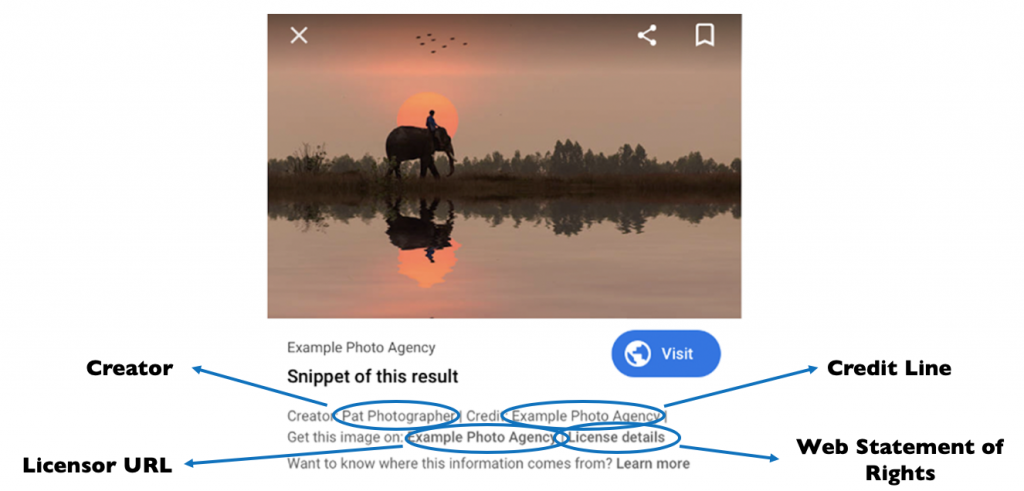
The launch on Google Images comprises three different components:
- “Licensable” badge on image search results for images that have the required metadata fields
- Two new links in the Image Viewer (the panel that appears when a user selects an image result) for people to access the image supplier’s licensing information, namely:
- A “License details” link. This directs users to a page defined by the image supplier explaining how they can license and use the image responsibly
- A “Get this image on” link, which directs users to a page from the image supplier where users can directly take the necessary steps to license the image
- A “License details” link. This directs users to a page defined by the image supplier explaining how they can license and use the image responsibly
- A Usage Rights drop-down filter in Google Image search results pages to support filtering results for Creative Commons, commercial, and other licenses.
“As a result of a multi-year collaboration between IPTC and Google, when an image containing embedded IPTC Photo Metadata is re-used on a popular website, Google Images will now direct interested users back to the supplier of the image,” said Michael Steidl, Lead of the IPTC Photo Metadata Working Group. “This is a huge benefit for image suppliers and an incentive to add IPTC metadata to image files.”
The features have been in beta since February, and after extensive testing, refinement and discussion with IPTC, CEPIC and others, Google is rolling out the new features this week.
As we describe in the Quick guide to IPTC Photo Metadata and Google Images, image owners can choose from two methods to enable the Licensable badge and “Get this image” link: embedding IPTC metadata in image files, or including structured schema.org metadata in the HTML of the web page hosting the image.
Of the two approaches, using embedded IPTC metadata has two benefits. Firstly, the embedded metadata stays with the image even when it is re-used, so that the Licensable badge will appear even when the image is re-published on another website.
Secondly, the “Creator”, “Copyright” and “Credit” messages are only displayed in search results when they are declared using embedded IPTC metadata.
“The IPTC anticipates that this will lead to increased awareness of image ownership, copyright and licensing issues amongst content creators and users,” said Brendan Quinn, Managing Director of IPTC. “By providing direct leads to image owners’ websites, we hope that this leads to increased business for image suppliers both large and small.”
The Google announcements can be found here:
 On July 1st 2020, IPTC was invited to participate in an online workshop held by the Arab States Broadcasting Union (ASBU).
On July 1st 2020, IPTC was invited to participate in an online workshop held by the Arab States Broadcasting Union (ASBU).
In a joint presentation, Brendan Quinn (IPTC Managing Director) and Robert Schmidt-Nia (Chair of IPTC and consultant with DATAGROUP Consulting Services) spoke on behalf of IPTC and Jürgen Grupp (data architect with the German public broadcaster SWR) spoke on behalf of the European Broadcasting Union.
The invitation was extended to IPTC and EBU because ASBU is looking at creating a common framework for sharing content between ASBU member broadcasters.
Jürgen Grupp started with an overview of why metadata is important in broadcasting and media organisations, and introduced the EBU’s high-level architecture for media, the EBU Class Conceptual Data Model (CCDM). and the EBUCore metadata set. Jürgen then gave examples of how CCDM and EBUCore are implemented by some European broadcasters.
Next, Brendan Quinn introduced IPTC and the IPTC News Architecture, the underlying logical model behind all of IPTC’s standards. We then took a deep dive into some video-related NewsML-G2 constructs like partMeta (used to describe metadata for parts of a video such as the rights and descriptive metadata for multiple time-based shots within a single video file) and contentSet (used to link to multiple renditions of the same video in different formats, resolutions or quality levels).
Then Robert Schmidt-Nia described some real-world examples of implementation of NewsML-G2 and the IPTC News Architecture at broadcasters and news agencies in Europe, in particular touching on the real-world issues of whether to “push” content or to create a “content API” that customers can use to select and download the content that they would like.
A common theme throughout our presentations was that the representation of the data in XML, RDF, JSON or some other format is relatively easy to change, but the important decision is what logical model to use and how to agree on the meaning (semantics) of terms and vocabularies.
A robust question and answer period touched on wide-ranging issues from the choices between XML, RDF and JSON, extending standardised models and vocabularies, and what decisions should be made to decide how to proceed.
This was one of the first meetings of ASBU on this topic and we look forward to assisting them further on their journey to metadata-based content sharing between their members.
Previously, we shared that Google was making image credits and usage rights information more visible on Google Images. Google now displays information about image copyright and ownership details, alongside creator and credit info, when websites and photo-owners make that information available for Google to crawl. Since the announcement there has been steady growth in the amount images containing these embedded metadata fields, which in turn has helped drive greater user awareness of copyright for images on the internet.
Up to now, users have seen the IPTC metadata information when they click on the “Image Credits” link in the “Google Images viewer” – the panel that appears when a user selects an image. Starting from today, users will begin to see this information directly in the viewer, making this rights-related information even more visible.
You can see an example of what this looks like below:
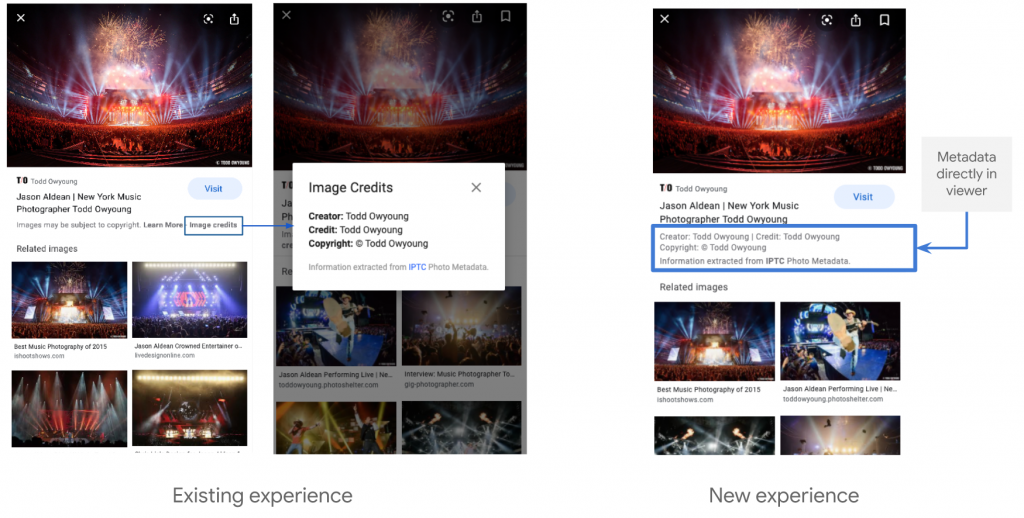
The Google Images team has said in a statement: “We are committed to helping people understand the nature of the content they’re looking at on Google Images. This effort to make IPTC-related information more visible is one more step in that direction.”
For more information on how you can embed rights and credits metadata in your photos, please see our Quick Guide to IPTC Photo Metadata and Google Images.
If you create photo editing or manipulation software and are looking for more information, please consult the Quick Guide or contact us for more information and advice.
We are very happy to continue working with Google and our partner organisation CEPIC on this and other developments in this area. We look forward to making an announcement about the launch of the related “Licensable Images” feature over the summer.

At the IPTC Autumn Meeting in Toronto in 2018, IPTC considered the issues of “trust and credibility” in news media. We looked at the existing initiatives and considered whether IPTC could contribute to the space.
We concluded that some existing efforts were doing great work and that we should not create our own trust and credibility standard. Instead, our resources could best be put towards working with those groups, and aligning IPTC’s standards — particularly our main news standards NewsML-G2 and ninjs — to work well with the outputs of those groups.
Since that time, the IPTC NewsML-G2 Working Group has been collaborating with several initiatives around trust and misinformation in the news industry. We have been working mainly with The Trust Project and the Journalism Trust Initiative from Reporters Without Borders, but have also been in communication with the Credibility Coalition, the Certified Content Coalition and others to identify all known means of expressing trust in news content.
Our aim is to make it easy for users of NewsML-G2 and ninjs to work with these standards to convey the trustworthiness of their content. This should make it easier for news publishers to translate trust information to something that can be read by aggregator platforms and user tools.
In particular, we want to make it as easy as possible for syndicated content to be distributed and published in alignment with trust principles.
A new IPTC Guideline document
To that end, we are publishing a “public draft” of a new IPTC guideline document: Expressing Trust and Credibility Information in IPTC Standards. While not complete, we hope that it helps IPTC members and other users of our standards to understand how they can express trust indicators.
To go along with the draft, we are proposing some changes to existing IPTC standards, including updates to NewsML-G2 and to ninjs, and a new Trust Indicator taxonomy created as part of the IPTC NewsCodes.
New Genres in NewsCodes and changes to NewsML-G2 and ninjs
To accommodate the new work, we will be adding some new entries to the NewsCodes Genre vocabulary. Some genres required for this work such as “Opinion” and “Special Report” were already in the genres vocabulary, but we are proposing to add new genres including “Fact Check” and “Satire“, and some genres to handle sponsored content: Advertiser Supplied, Sponsored and Supported.
We will also be making some small changes to the existing ninjs and NewsML-G2 standards to accommodate some new requirements, such as being able to associate a publisher with another organisation, to indicate membership of The Trust Project, Journalism Trust Initiative or a similar group.
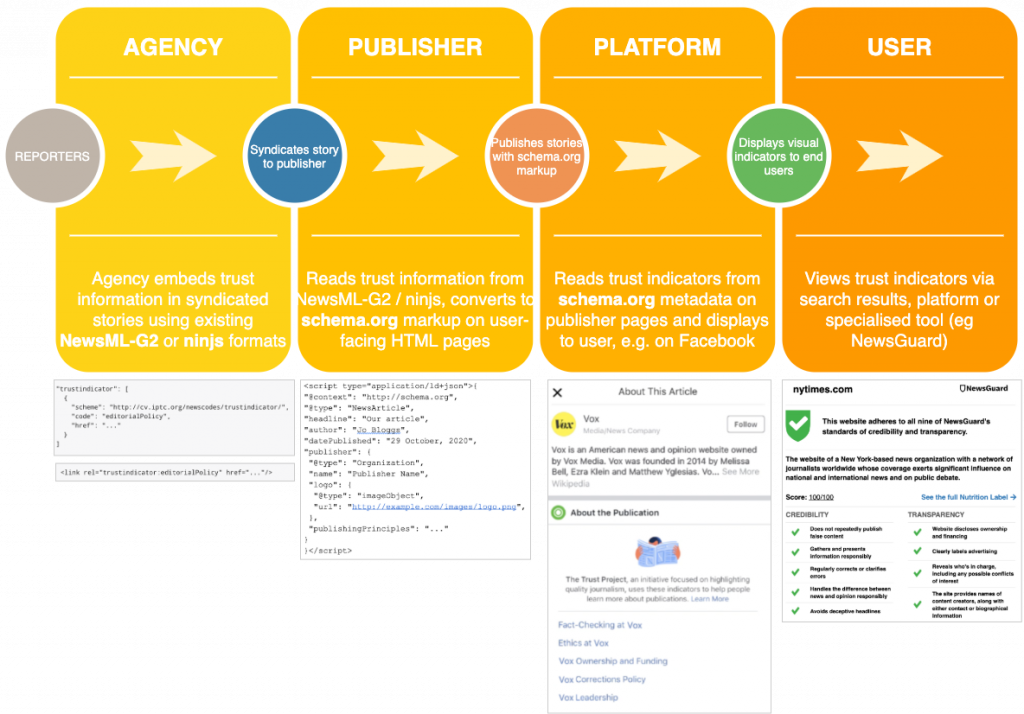
From trusted agency to publisher and then to a user
By following the guidelines, a news agency can add their own trust information to the news items that they distribute. A publisher can then take those trust indicators and convert them to the standard schema.org markup used to convey trust indicators in HTML pages (initially created via a collaboration between schema.org and The Trust Project in 2017).
The schema.org markup can then be read by search engines, platforms such as Facebook, and specialised trust tools such as the NewsGuard browser plugin, so that users can see the trust indicators and decide for themselves whether they can trust a piece of news.
Please give us your feedback
The document will not be final until after those changes have been approved by IPTC members at our next meeting in May.
We have published the draft to ask for feedback from the community about how we could improve our guidance, ask for any trust indicators that we have missed, and to ask for implementation feedback.
Please use the IPTC Contact Us form to send your feedback.
About the Trust Project
The Trust Project is a global network of news organizations working to affirm and amplify journalism’s commitment to transparency, accuracy and inclusion. The project created the Trust Indicators, which are a collaborative, journalism-generated standard for news that helps both regular people and the technology companies’ machines easily assess the authority and integrity of news. The Trust Indicators are based in robust user-centered design research and respond to public needs and wants.
For more information, visit thetrustproject.org.
The Trust Project is funded by Craig Newmark Philanthropies, Democracy Fund, Facebook, Google and the John S. and James L. Knight Foundation.
About the Journalism Trust Initiative
The Journalism Trust Initiative aims at a healthier information space. It is developing indicators for trustworthiness of journalism and thus, promote and reward compliance with professional norms and ethics. JTI is led by Reporters Without Borders (RSF) in partnership with the European Broadcasting Union (EBU), the Global Editors Network (GEN) and Agence France Presse (AFP).
For more, visit https://jti-rsf.org/en/
We are excited to announce that the result of our latest collaboration with Google has been launched in a beta phase: Licensable Images.
This feature, that Google is exploring with this beta, will enable image owners not only to receive credit for their work but also to find ways to raise people’s awareness of licensing requirements for content found via Google Images.
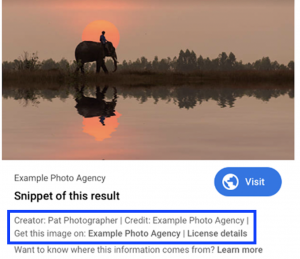
By embedding IPTC Photo Metadata fields into their images (or using schema.org markup), Google will place a badge on licensable images in search results pages.
Under the image preview, Google will show embedded rights metadata (creator, copyright and credit fields). These have been displayed since IPTC’s collaboration with Google in 2018, but will now be given more prominence.
Along with the rights metadata, Google will now show links to the image’s usage licence and also a link to “Get this image”.
See the image for a mockup of how it might look.
By embedding IPTC Photo Metadata into your images, these links will be shown for images on your own website and also when your customers publish images on their sites.
Along with the photo industry organisation CEPIC, IPTC has been working with Google on this project since the IPTC Photo Metadata Conference at CEPIC Congress in June 2019.
The user-facing side of the feature is planned to launch in the next few months. Google has released some developer documentation to encourage image owners to get ready for the launch.
Learn how to make licensable images work for your image collections
For IPTC members, we will be running a webinar today, Thursday 20 February at 15:00 GMT.
The webinar will explain how the licensable images feature works and what image owners can do to get ready for the launch.
The speakers will be Michael Steidl, Lead of the IPTC Photo Metadata Working Group, and Brendan Quinn, Managing Director of IPTC.
Please check your email for the announcement and information on how to join.
For non-members, we will be publishing a page on this site on Friday 21 February that will explain how to take advantage of the feature.
UPDATE: We have now updated our Quick Guide to IPTC Photo Metadata and Google Images to include information on how to embed rights and licensing metadata in your images.
We’re very pleased to see this launch. We look forward to seeing how our members will use this feature to draw more attention to the importance of image rights and licensing.
To support the work of IPTC in this and other areas, please consider joining IPTC.
We’re excited that the biggest week in the photo metadata calendar has arrived – the IPTC Photo Metadata Conference 2019 will be held in Paris this Thursday, 6 June.
We are looking forward to hearing from some IPTC members: Andreas Gnutzmann from Fotoware, Lúí Smyth from Shutterstock, Isabelle Wirth of Agence France Presse and Michael Steidl, Chair of the Photo Metadata Working Group and honourable member of IPTC. Stéphane Guerrilot, CEO of AFP Blue will be chairing the event.
We will also be hearing from independent photographer Andrew Wiard representing the British Press Photographer’s Association (BPPA), plus Anna Dickson, Visual Lead, Image Search at Google attend, bringing her expertise as one of Google’s experts on images but also with a history leading photography teams at Dow Jones and Huffington Post. Mayank Sagar from Image Data Systems will be speaking about the latest developments in automatic image tagging, and Simon Brown of Deep3D will look at the photographer’s view around embedding metadata.
Michael Steidl and Sarah Saunders will be presenting the results of the 2019 Photo Metadata Survey, where we have obtained the views of image creators, publishers and software makers regarding embedded image metadata.
Brendan Quinn, Managing Director of IPTC will be presenting the IPTC Photo Metadata Crawler which looks at usage of embedded photo metadata among news publishers.
We’re looking forward to analysing the world of photo metadata from the perspective of image creators and editors, software makers, publishers, search engines and end users.
There are still some tickets available, so please join us! Attendance is free for CEPIC Congress attendees, but if you just want to come for the IPTC event on Thursday afternoon you can register using this form for €100 + VAT.
See you there!

We were proud to be involved at last week’s Metadata Exchange for News interoperability demo organised by DPP (formerly known as the Digital Production Partnership).
DPP’s “Metadata Exchange for News” is an industry initiative aimed at making the news production process easier.
The DPP team looked around for existing standards on which to base their work, and when they found IPTC’s NewsML-G2, they realised that it exactly matched their requirements. NewsML-G2’s generic PlanningItem and NewsItem structure meant that it could easily be used to manage news production workflows with no customisation required.
We were treated to a demo of a full news production workflow in the DPP’s offices at ITV in London on February 6th.
A full news production workflow
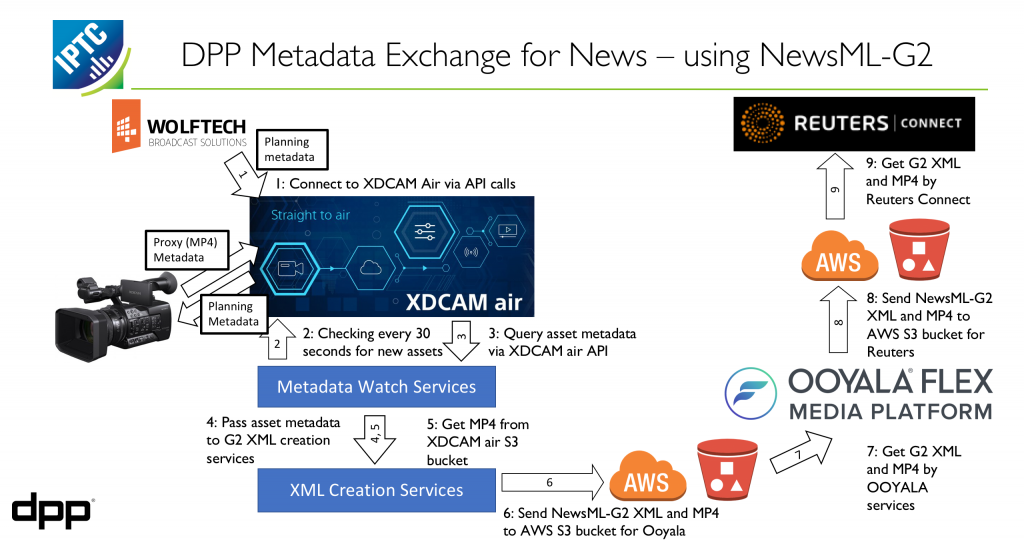
As you can see from the diagram, the workflow involves these steps:
- An editor creates a planning record for a news item using Wolftech’s planning system, describing metadata for the planned story
- The system sends the planning item as NewsML-G2 to Sony’s XDCAM Air system which converts it to Sony’s proprietary planning metadata and sends it directly to a camera
- XDCAM Air retrieves the footage from the camera, links it to the planning metadata using the NewsML-G2 IDs, back into XDCAM Air which is then retrieved by some simple custom web services
- The web services send NewsML-G2 NewsItem metadata along with the MP4 video file to Ooyala’s Flex Media Platform via an Amazon Web Services S3 bucket
- Ooyala Flex Media Platform sends the media and metadata to the platforms that require it, in this case the Reuters Connect video browsing and distribution platform.
The NewsML-G2 integrations were built for the demo but the idea is that they will soon become standard features of the products involved. All parties reported that implementing NewsML-G2 was fast and fairly painless!
Thanks to all involved and special thanks to Abdul Hakim of DPP for leading the project and organising the demo day.
Look out for an IPTC Webinar on this topic soon!