Categories
Archives

This post is part of a series about the IPTC Spring Meeting 2019 in Lisbon, Portugal. See Day 2 writeup and the day 3 writeup.
Last week brought IPTC members together for our twice-yearly Face-to-Face Meeting to discuss news credibility, taxonomies and controlled vocabularies, updates in sports standards and much more!
This year’s IPTC Spring Meeting was in Lisbon, Portugal, and over 40 IPTC member delegates, member experts and invited guests gathered for three days to discuss all the latest developments in news and media technology.
On Monday, IPTC Chair and Director of Information Management for Associated Press Stuart Myles gave a great introduction and overview of what was to come in the meeting. After everyone introduced themselves, Stuart discussed some changes that the IPTC Board has been thinking about, including looking at updating the Mission and Vision of the organisation to reflect how we operate in 2019.
Then Robert Schmidt-Nia from dpa Deutsche Presse-Agentur introduced their C-POP project (in collaboration with STT and the Sanoma group in Finland) which follows on from the Performing Content we saw at the previous meeting in Toronto. It was interesting hearing about the agency’s shift in focus from a strict business-to-business model to a “B2B2C” model thinking about what consumers needed and how agencies could help publishers to deliver on the needs of readers and subscribers, ideally using feedback from publishers to agencies on how well their content is performing according to real metrics like loyalty and subscription revenue. IPTC will be involved in the C-POP project so you can expect to hear more about this in the future.
On the same topic, Andy Read from BBC gave an overview of the “Telescope” internal measurement tool, showing how BBC staff can view in real time how their content is being consumed by region, topic or device.
James Logan from the BBC and Brendan Quinn of IPTC gave an overview of IPTC’s work with news trust and credibility projects The Trust Project and the Journalism Trust Initiative. We decided at the Autumn 2018 Meeting that IPTC wouldn’t create its own standard around news credibility, disinformation and “fake news”, but that we would work with existing groups and help them to incorporate their standards in IPTC’s work. With The Trust Project, that has been going well, and we are almost ready to publish some best practices on implementing the Trust Project’s Trust Indicators in NewsML-G2 content. Trust Project indicators are already used in schema.org markup by over 120 news providers so it’s great to see such strong uptake.
Separately we have been working with Reporters Sans Frontières’ Journalism Trust Initiative which is at an earlier stage and is looking at documenting general standards for trustworthy and ethical journalism. IPTC is part of the JTI’s Technical Task Force which is working with the drafting teams on making their statements specific enough to be answered with data and indexed by machines. Hopefully it will end up with similar indicators to the Trust Project indicators
With both news credibility projects, some questions still need to be addressed, such as assessing the credibility of claims (when a news organisation says they are trustworthy, how can you trust them!), and how these trust indicators work in a multi-provider workflow: if a news agency sends some content to a publisher who then merges it with original reportage, who determines the trust indicators that are attached to the final story? There is definitely a lot more work to do!
On the same topic, Dave Compton of Refinitiv gave an update on how the News Architecture Working Group has been looking at the Trust Project’s Trust Indicators and working them into NewsML-G2. As far as we have seen so far, no updates to the NewsML-G2 standard are necessary to support the new work. Martin Vertel from dpa showed us the API he created to give dpa’s clients access to Trust Project indicators for dpa stories. Building it with a browser-based JavaScript module opens up some interesting possibilities.
Joaquim Carreira from local agency Lusa showed us the “Combate Às Fake News” project focussing on media literacy and helping readers to know what to look for, including the idea of a “nutrition label” for news content looking at criteria such as factuality, readability and use of emotional language.
The day was rounded off with Johan Lindgren of Swedish agency TT presenting the recent work of IPTC’s Sports Content Working Group. The group has recently been tidying up the spec and incorporating suggestions for changes, plus looking at eSports and Chess as two non-traditional sports that are both seeing an increase in interest – in the case of eSports, it is becoming a huge industry. Our tests showed that in simple cases eSports results can be addressed with existing SportsML 3 structures, but to handle more detailed play-by-play results we may need to at least introduce a new controlled vocabulary. Please let us know if you would like to implement SportsML for eSports!
Johan also presented the draft of SportsML 3.1 to be voted on by the IPTC Standards Committee.
Stay tuned for an update on Days 2 and 3!

We were proud to be involved at last week’s Metadata Exchange for News interoperability demo organised by DPP (formerly known as the Digital Production Partnership).
DPP’s “Metadata Exchange for News” is an industry initiative aimed at making the news production process easier.
The DPP team looked around for existing standards on which to base their work, and when they found IPTC’s NewsML-G2, they realised that it exactly matched their requirements. NewsML-G2’s generic PlanningItem and NewsItem structure meant that it could easily be used to manage news production workflows with no customisation required.
We were treated to a demo of a full news production workflow in the DPP’s offices at ITV in London on February 6th.
A full news production workflow
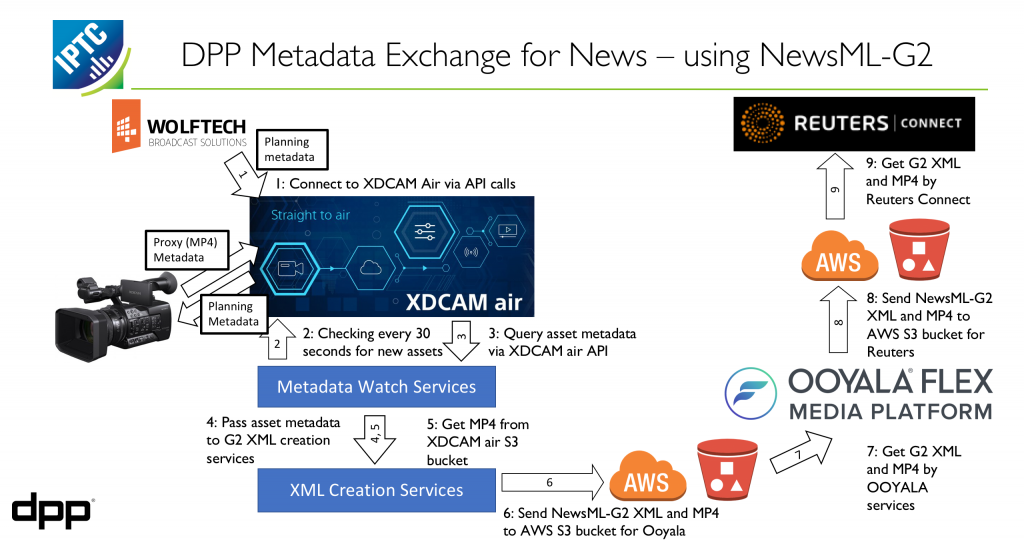
As you can see from the diagram, the workflow involves these steps:
- An editor creates a planning record for a news item using Wolftech’s planning system, describing metadata for the planned story
- The system sends the planning item as NewsML-G2 to Sony’s XDCAM Air system which converts it to Sony’s proprietary planning metadata and sends it directly to a camera
- XDCAM Air retrieves the footage from the camera, links it to the planning metadata using the NewsML-G2 IDs, back into XDCAM Air which is then retrieved by some simple custom web services
- The web services send NewsML-G2 NewsItem metadata along with the MP4 video file to Ooyala’s Flex Media Platform via an Amazon Web Services S3 bucket
- Ooyala Flex Media Platform sends the media and metadata to the platforms that require it, in this case the Reuters Connect video browsing and distribution platform.
The NewsML-G2 integrations were built for the demo but the idea is that they will soon become standard features of the products involved. All parties reported that implementing NewsML-G2 was fast and fairly painless!
Thanks to all involved and special thanks to Abdul Hakim of DPP for leading the project and organising the demo day.
Look out for an IPTC Webinar on this topic soon!
This report was presented by Stuart Myles, IPTC Chairman, at the IPTC Annual General Meeting in Toronto, Canada on October 17 2018.
IPTC has had a good year – the 53rd year for the organization!
We’ve updated key standards, including NewsML-G2, the Video Metadata Hub and the Media Topics, as well as launching RightsML 2.0, a significant upgrade in the way to express machine processable rights for news and media.
Of course, IPTC standards are a means, not an end. The value of the standards is the easier exchange, consumption and handling of news and media by organizations large and small around the world. So it is important that we continue to focus on making our standards straightforward to use and have them adopted as widely as possible. I think we are making progress on the usability front, such as moving away from zip’d PDFs towards actual HTML web pages for documentation of NewsML-G2. Over the last year, we’ve continued to work with other organizations – W3C, Europeana and MINDS – to develop standards, increase adoption – and, perhaps most importantly, to open up IPTC to other perspectives. And we have had a huge win in the recognition of key photo metadata by Google Images. But we clearly need to do more for both usability and adoption. During the course of this meeting, we’ve had some good discussion about what more we can do in both areas and I encourage all members to help spread the word about IPTC standards, and suggest ways we can accelerate adoption.
Of course, the nature of news and media continues to evolve. On the one hand, new forms of story telling are emerging, such as Augmented Reality and Virtual Reality. Equally, using data as the way to power stories continues to increase both data-driven stories and data-supported stories. By data-driven stories, I mean journalists reviewing large databases of information and creating stories based on the trends they find. By data-supported stories, I mean content creators using visually-interesting graphics to support their content. The automated production, curation and consumption of news and media is likely to increase for the foreseeable future, driven by both technological improvements and the seductive economics of replacing people with algorithms. And it is not only economics which are driving these changes and challenges, just as it is no longer fill-in-the-blank text stories being written by robot journalists. Synthetic media – such as “deep fakes” – are able to produce increasingly convincing photo, video and audio stories that are indistinguishable from “real” media. Inevitably, the existence and debunking of these fakes will be used to deny legitimate reporting, with the implications of continued erosion of trust in media. All of these trends – AR, VR, data-powered journalism and dealing with trust, credibility and misinformation – are topics which IPTC has discussed over the last few years, but we have not developed any tracks of work to try to address them. In part, this is because these are, by definition, outside of the areas that our member organizations traditionally deal in and are so quite difficult to tackle in terms of establishing standards.
However, even within the context of standards, IPTC is opening up to new forms of experimentation. As we heard on Monday, the joint project between IPTC and MINDS, to allow for the identification of audience and interest metadata, has lead to the introduction of structures within NewsML-G2 to support rapid prototyping and experimentation. I see this as a positive move, with great potential to accelerate the work we do and to help keep it lightweight and relevant.
Of course, IPTC has had significant changes of its own over the last year. We bid goodbye to Michael Steidl as our Managing Director of 15 years, and welcomed Brendan Quinn as our new Managing Director this summer. We’re grateful that we continue to benefit from Michael’s skills and experience, as he has remained the Chairman of the Photo and Video Working Groups. And I think that Brendan has made a great start in his new role in helping us keep the IPTC moving forward.
As part of the handover from Michael to Brendan, we decided to scan a lot of the old paper documents (link available to members only), including various types of IPTC newsletter, dating back to 1967, two years after the organization was founded. I thought I would look back to what IPTC was up to in the year 2000, the year I became a delegate to the IPTC, back when I worked for Dow Jones.

And there I am in the photo at the top of the page. Or, at least, the back of my head. Some things are quite reminiscent of this week’s meeting – the birth of NewsML, a focus on improved communications, cooperation with other organizations e.g. MPEG-7.
Then I thought I would look back on IPTC in 1968, the year I was born:

Some things were similar to today – such as a focus on fine technical details such as Alphabet Number 5 and a plan to go to Lisbon next year for a meeting. However, most of the focus in those days was mainly on lobbying against tariffs and satellite monopolies.
So I think it is fair to say that the IPTC has never been just a standards body. It is also, more broadly, a community of practice. We are a group of people from around the world who have a common interest in news and media technology. The process of sharing information and experiences with the group, through these face to face meetings and the online development of standards, means that the members of IPTC learn from each other, and so have an opportunity to develop professionally and personally. I hope you will agree that yesterday’s discussion of news search and classification was an excellent example of exchange of experiences, both good and bad, which can help many of us avoid problems and seize opportunities, and so accelerate our work.
I think it is helpful for us to recognize that IPTC is a community which continues to evolve, as the interests, goals and membership of the organization change. I’m confident that – working together – we can continue to reshape the IPTC to better meet the needs of the membership and to move us further forward in support of solving the business and editorial needs of the news and media industry. I look forward to working with all of you on addressing the challenges in 2019 and beyond.
This is the report of Day 3 of the IPTC Autumn 2018 Meeting in Toronto. See the report from Day 1 and the report from Day 2. All the presentations are available to IPTC members in the IPTC Members Only Zone.
Day 3 of IPTC Autumn Meetings always includes the Annual General Meeting, where all Voting Members can have their say in the future of the organisation. This time new Managing Director Brendan Quinn gave his first MD’s report, alongside Stuart Myles’ Chairman’s Report (which will be posted to the IPTC blog soon). Materials from the AGM are available to members in the IPTC Members Only Zone.
Rounding out the discussions for the three days, we had some broad-ranging and future-facing conversations regarding News Credibility projects, where Stuart Myles took us on a tour of the wide range of projects and initiatives around misinformation, the credibility of news and news sources, and the perceived problems of “fake news.” IPTC or IPTC members are helping out several organisations in their efforts in this area such as the w3C Credible Web community group and the Journalism Trust Initiative.
We also had a discussion on funding opportunities and potential IPTC projects, which is an internal discussion involving members only.
Lastly, speaking about the future, we had Michael Young from Civil Media speak to us about their plans to use blockchain technologies to power small newsrooms and fulfil their broad goal to “power sustainable journalism throughout the world.” A lot of focus has been on Civil’s Initial Coin Offering, which closed underfunded and will be returning investors’ money, but they have many other activities, including a suite of WordPress-based plugins allowing news providers to join the Civil ecosystem and pledge openness, fairness and transparency according to the Civil Foundation’s constitution. Mike explained how blockchain based voting and decisions mean that members can be rewarded for pointing out breaches of the constitution, and bad actors can be punished or even removed from the network entirely.
The event ended with a few of us attending the Canadian Journalism Foundation’s event with journalism pundits Vivian Schiller, Jeff Jarvis, Jay Rosen and Matthew Ingram, talking about misinformation and misuse of social media (video recording available via the above link), and ten of us went on a networking and team bonding trip to Niagara Falls and to a local winery on the Thursday.
Overall it was a great Autumn Meeting which set the scene and built the foundation for many more great IPTC meetings to come!
This is the report of Day 2 of the IPTC Autumn 2018 Meeting in Toronto. See the report from Day 1 and the report from Day 3. All the presentations are available to IPTC members in the IPTC Members Only Zone.
Day 2 of the IPTC Autumn 2018 Meeting in Toronto was a deep dive into search and classification. Many of our members are working hard to make their content accessible quickly and easily to their customers, and user expectations are higher than ever, so search is a key part of what they do.
First up we had Diego Ceccarelli from Bloomberg talking through their search architecture. Users of Bloomberg terminals have very high expectations that they will see stories straight away: They have 16m queries and 2m new stories and news items per day, with requirements for a median query response time of less than 200ms and for new items to be available in search results in less than 100ms. And as Diego says, “with huge flexibility comes huge complexity.” For example, because customers expect to see the freshest content straight away, the system has no caching at all!

To achieve this, the Bloomberg team use Apache Solr – in fact they have 3 members of staff dedicated to working on Solr full-time, and have contributed a huge amount of code back to the project, including their machine-learning-based “learning to rank” module which can be trained to rank a set of search results in a nuanced way. Bloomberg also worked with an agency to develop open source code used to monitor a stream of incoming stories against queries, used for alerting. Other topics Diego raised included clustering of search results, balancing relevance and timeliness, crowdsourcing data to train ranking systems, combining permissions into search results, and more – a great talk!
Our heads already reeling with all the information we learned from Bloomberg, we then heard from another search legend, Boerge Svingen, one of the founders of FAST Search in Norway and now Director of Engineering at the New York Times. He spoke about how NYT re-architected their search platform to be based around Apache Kafka, a “distributed log streaming” platform that keeps a record of every article ever published on the Times (since 1851!) and can replay all of them to feed a new search node in around half an hour. The platform is so successful that it is used to feed the “headless CMS” (see yesterday’s report) based on GraphQL which is used to render pages on nytimes.com for all types of devices. Boerge and his team use Protocol Buffers as their schema to keep everything light and fast. More information in Boerge’s slide deck, available to IPTC members.
Next up was Chad Schorr talking about search at Associated Press, discussing their Elastic implementation on Amazon Web Services. Using a devops approach based on “immutable infrastructure” meant that the architecture is now very solid and well-tested. Chad was very open and spoke about issues and problems AP had while they were implementing the project and we had a great discussion about how other organisations can avoid the same problems.
Then Robert Schmidt-Nia from DPA talked about their implementation of a content repository (in effect another “headless CMS”!) based on serialising NewsML-G2 into JSON using a serverless architecture based on Amazon Lambda functions, AWS S3 for storage, SQS queues and Elasticsearch. Robert told of how the entire project was built in three months with one and a half developers, and ended up with only 500 lines of code! It can now be used to provide services to DPA customers that could not be provided before, including subsets of content based on metadata such as all Olympics content.
Next, Solveig Vikene and Roger Bystrøm from Norway’s news agency NTB spoke about and gave a live demo of their new image archive search product. They demonstrated how photographers can pre-enter metadata so that they can send their photos to the wire a few seconds after taking them on the camera. Some functions like global metadata search and replace and a feature-rich query builder made their system look very impressive.
Veronika Zielinska from Associated Press spoke about AP’s rule-based text classification systems, showing the complexity of auto-tagging content (down to disambiguating between two US Republican Congressmen both called Mike Rogers!) and the subtlety of AP’s terms (distinguishing between “violent crime” events versus the social issue of “domestic violence”) therefore the necessity of manually creating, and maintaining, a rules-based system.
Stuart Myles then took us on a tour through AP’s automated image classification activities, looking at whether commercial tools are yet up to the task of classifying news content, the value of assembling good training sets but the difficulties in doing so, and the benefits of starting with a relatively small taxonomy that is easier for machine learning systems to understand.
Dave Compton talked us through Thomson Reuters Knowledge Items used by the OpenCalais classifier and how they use the PermID system to unify concepts across their databases of people, organisations, financial instruments and much more. Dave described how Knowledge Items are represented as NewsML-G2 Knowledge Items, and are mapped to Media Topics where possible.
On that subject, Jennifer Parrucci of the New York Times, and chair of the IPTC NewsCodes Working Group, gave an update on the latest activities of the group, including the ongoing Media Topic definitions review, adding new Media Topic terms after suggestions by the Swedish media industry, and work with schema.org team on mapping between schema.org and Media Topics terms.
As you can see, it was a very busy day!
This is the report of Day 1 of the IPTC Autumn 2018 Meeting in Toronto. See the report from Day 2 and the report from Day 3. All the presentations are available to IPTC members in the IPTC Members Only Zone.
This week we are in Toronto for the IPTC Autumn Meeting. Unfortunately the weather is not as warm as it was last week but we are still enjoying ourselves immensely and learning a lot from each other!

All presentations are available to members on the members-only event page.
After an introduction from Chair Stuart Myles, we heard an update from Michael Steidl, chair or the Video Metadata and Photo Metadata Working Groups. Michael updated us on work promoting the IPTC Video Metadata Hub standard, talking to manufacturers and software vendors at events like IBC in Amsterdam, and pulling together use cases and success stories from existing users of the standard.
On the IPTC Photo Metadata Standard, Michael shared news about the fact that Google Images now displays IPTC Photo Metadata project and the press we have received since that time. Also we are working on new technical features in the standard such as metadata for regions within images. We’re looking for use cases and requirements for storing metadata against regions, so if you have any input, please let Michael, or IPTC Managing Director Brendan Quinn, know!
Dave Compton of Refinitiv, formerly the Financial & Risk business of Thomson Reuters, chair of the NewsML-G2 Working Group, gave an update on recent progress and work towards NewsML-G2 version 2.28 which will be released soon. It will incorporate features for the requirements of auto-tagging systems and a new experimental namespace to be used for potential new updates to NewsML-G2 that aren’t yet ready to be added to the full specification.
The experimental extension to NewsML-G2 is already put in use by Gerald Innerwinkler of APA and Robert Schmidt-Nia of DPA who presented an update on a current project between IPTC and MINDS International looking at metadata for suggesting news stories to users based on psychological and emotional characteristics, plus properties like the likely timeliness for different types of user. Based on the Limbic Map concept from marketing theory, the new proposals are in testing right now.
Chair of the Sports Content Working Group, Johan Lindgren of TT in Sweden, presented an update on SportsML and the work on SportsJS which is nearing a final version now that JSON Schema is soon able to support some new properties that we need to be able to validate Sports content.
Stuart Myles appeared again in his role as chair of the Rights Working Group, updating us on RightsML and where we can take it in the future, including the potential to use RightsML as the basis of blockchain-based rights management systems.
Then we had a focus on “new-generation editorial systems” including a great presentation from Peter Marsh of new IPTC member NEWSCYCLE Solutions on the history and state of the art of content management systems from Tandem-based SII workstations in the 1980s, all the way through to the current wave of headless CMSs as illustrated by this project by The Economist.
Stephane Guerrilot of AFP finished day one presenting AFP’s new-generation system, Iris, which enables AFP customers and partners to search for stories, video and images.
Stay tuned for a report on Day Two!
Hi everyone,
It is now just over 80 days since I took on the IPTC Managing Director role on the 1st of June, so I thought it would be a good time to reflect on my experience so far.
I actually started my IPTC “life” in April at the IPTC 2018 Spring Meeting in Athens, Greece – thankfully my previous project allowed me to go to Athens for a few days to meet everyone and see first hand how an IPTC face-to-face meeting works. Everyone was very friendly and welcoming, and I look forward to seeing many familiar and new faces at the Autumn 2018 meeting in Toronto – the hotel booking link will be released in the next few days so keep an eye out! And if you’re not an IPTC member but you’re interested in speaking or attending, see the call for participation for the IPTC Toronto meeting that we released recently and please do get in touch.
Having worked for many media companies over the years – building content management and syndication systems at Fairfax Media and the BBC, working on long and short term projects for various media organisations (Associated Press, TV3 Ireland, BBC Worldwide and Newsworks) and co-founding a startup in the industry (NewsFixed, since acquired by Paydesk) – I have a broad background in the technology side of the media industry. So it’s great to work with some of those organisations plus many more, helping to set the standards that bring the industry together.
Working with the previous MD Michael Steidl has been a breeze. His care and attention to detail meant that handover was very easy, and hopefully I can continue to uphold the high standards that he has set. I wish him the best of luck in enjoying his retirement, and am very thankful that he has offered to stay on as chair of the IPTC Photo Metadata and Video Metadata working groups!
When most people in the industry think of IPTC, they probably think of the technical standards or the controlled vocabularies – but I really see IPTC as a group of people from companies across the news and media industry who are working together to solve the sorts of problems that can only be solved by working together. I really hope that we can continue to work together to solve more problems in the future. If you have ideas, please get in touch – I can be reached at mdirector@iptc.org.
I also plan to get out to many industry events and conferences to meet and learn from people from the industry who may or may not be IPTC members. Thanks to those I have already met at the IPTC Photo Metadata Conference co-located with CEPIC in Berlin in May, the Henry Stewart Digital Asset Management conference in London in June, and I’m looking forward to going to the IBC Conference in Amsterdam in September.
Taking on the role with IPTC has coincided with another change in my life: as the MD role is remote, my wife and I took the opportunity to move to my wife’s home town, the tech hotspot of Tallinn, Estonia. We’re having a great time getting settled here, and if you ever happen to be in Tallinn, please get in touch, I would love to show you around!
Brendan Quinn
IPTC Managing Director
Earlier this year, we announced the arrival of Brendan Quinn, the new managing director of the International Press Telecommunications Council.
And while we’re thrilled to welcome Brendan to his new role, we’d be remiss if we didn’t take a moment to honour the man whom he’ll be replacing: Michael Steidl, who is retiring from the IPTC after 15 years.
Michael joined IPTC in the beginning of 2003 after two decades working as a journalist, managing director for news agencies and information technology consultant for news providers.
Upon his arrival, he pledged to do one thing, recalled IPTC Board Chairman Stuart Myles in a tribute at the recent IPTC Spring Meeting 2018.
Michael didn’t want to reinvent the wheel, but to simply continue the good work of the previous director and “add some extra shades of colour” to IPTC’s image as a leader in news industry standards.
Of course, Michael did more than just add a few extra shades. Myles said:
“In fact, I would say that Michael’s contributions to the IPTC is really more equivalent to an entirely new artistic movement – a sort of Renaissance for the organisation – including managing the introduction of entirely new ways of operating the IPTC. When Michael started, there were no teleconferences or video conferences or even development of standards through email lists. There was no internet available during the meetings – which has perhaps been a mixed blessing, since people can keep up with the work back home, but we aren’t always as focussed.”
Klaus Sprick, a former IPTC board member who has been involved with the organisation for nearly 50 years, said the council – and the industry as a whole – owes Michael a debt.
“He is THE key person in IPTC to have moved it forward,” Sprick said. “IPTC is now, thanks to his efforts, the only respected and acknowledged organisation setting standards in international press information technology: media topics, subject codes, metadata, formats.”
Michael has called his time with the IPTC a great experience, adding he was happy to have been involved with the development and launch of nine new standards, the new Media Topic taxonomy and other vocabularies, and in his role in setting up new formats for face-to-face meetings and the creation of new kinds of meetings.
“Being in contact with our membership is also part of the bright side of my IPTC life and I enjoyed spreading the word about IPTC and its work among people knowing only little or nothing about our organisation.”
Prior to joining IPTC, Michael spent 11 years as managing director of Kathpress, where he had also worked as journalist. He has also worked as vice press officer for Medienstelle ED Wien, and as a freelance reporter for ORF.
We wish Michael a very happy retirement and thank him once again for the work he’s done to bring the IPTC to where it is today.

By Johan Lindgren
The Sports Content Working Group of IPTC started in the early 2000’s, initially to develop the XML standard SportsML. But the group has evolved to handle many aspects of reporting sports in the news.
The initial big question for news organisations handling sports is to decide if it should be handled as text or as data. The sports articles have, obviously, more in common with articles about other subjects. It is the results, schedules, statistics and standings that provide the dilemma. You can choose to provide the results ready for display on screen or on paper. Or you can provide the results as detailed marked up data and let the receiver handle the formatting, depending on purpose.
In fact, with using both NewsML-G2 and SportsML from IPTC you can provide both variants in parallel, if you wish so. In a NewsML-G2 news item as wrapper you provide one rendition of the content with the results as data in SportsML markup, and in another rendition you provide the same results, but in a displayable format like HTML5.
Vocabularies and Media Topics
Another big issue in handling sports data is knowing all the terms, what they mean and how they are used. The people in the sports group have spent a lot of time on this and provide very extensive vocabularies. Some are found in the Media Topics, maintained by the NewsCodes Working Group of IPTC. The same is true for the new addition to this, called facets. Facets refine the semantics of a Media Topic.
Example: If you try to combine Nordic skiing, female, relay, freestyle, 4×5 km as constituting one combined Media Topic and think of all the variations resulting from alternates to those terms, and then expand that thought to all sports events, the number of Media Topics will be overwhelming. Instead, IPTC chose to minimize the number of Media Topics and instead create a system of facets that qualify these broader topics. So, for example, “male” and “female” can apply to many, many sport competition topics, eliminating the need to create separate Media Topic terms for all of them.
About SportsML
Apart from the topics and their facets there is a huge number of metadata property values maintained by the sports group. These values are listed in 113 vocabularies (they can be downloaded), 37 of them are used for the core of SportsML and the other 76 are used for sport-specific additions. In total there are 1,850 values defined and listed as concepts in 113 knowledge items. The list of metadata values and their explanations is fundamental know-how in the sports reporting. You can have names and definitions in several languages.
Example of a code saying the player started the game on the field:
<concept id=”spplayerstatusstarter”>
<conceptId qcode=”spplayerstatus:starter” />
<name xml:lang=”en-US”>starter</name><name xml:lang=”en-GB”>starter</name>
<definition xml:lang=”en-GB”>A member of the lineup that enters the field at the commencement of play.</definition></concept>
SportsML is used by news organisations around the world both for everyday sport reporting and big events. BBC, for example, built their handling of the Olympic results in London around SportsML. It is also used by organisers of so-called fantasy sports leagues. Even by just using the core you can handle most normal news reporting of all sports events and competitions. There are also plugins for eleven sports, when you want to handle very in-depth data of these sports. And more plugins can be added. There are also ways to extend the standard with your own values or constructs. When developing SportsML the aim has always been to handle things in the core if the things are applicable to more than one sport. But some things are very specific to one sport and will instead be placed in its own schema which is imported and linked in proper places.
To illustrate this we can use this snippet from a soccer game:
<team-stats score=”0″ score-opposing=”2″ event-outcome=”speventoutcome:loss”>
<team-stats-soccer line-formation=”433″>
<stats-soccer-offensive corner-kicks=”2″/>
The first line is general with the score and outcome. But the two other lines are soccer-specific with a line-formation and the number of corner-kicks this team shot in this game.
SportsML for JSON
Up until now SportsML has mainly been serialized using XML. But with increasing interest in JSON the sports group is working on also providing a schema of SportsML for JSON usage. The work is close to being ready for the first public release. Some details of the schema need to be finalized and then the Working Group provide samples and some tools. We’re hoping to have this ready to release by early 2018.
The release of 3.0 of SportsML in XML also provided some tools (see our Github repository), mainly to transform between the earlier version, 2.2, and 3.0. One of the big developments in 3.0 was the possibility to handle statistics either in generic structures or in specific structures. So there are tools to transform between the two variants. To show this we can compare the above soccer example with the similar generic sample:
<stat stat-type=”spsocstat:line-formation” value=”433″/>
<stat class=”spct:offense” stat-type=”spsocstat:corner-kicks” value=”2″/>
As you see the attribute names become type-values in the generic stat-construction.
The work in the Sports Content Group is completely done by volunteers. The members of the group work in the news business and contribute to the group as much as their work allows. We welcome all interested persons, e.g. by joining our public discussion forum. The more people who can contribute the better, and there seem to be a never-ending flow of interesting topics when you start talking about sports data.
Johan Lindgren is the Chair of the Sports Content Working Group and a developer at TT Nyhetsbyrån, Sweden.
By Jennifer Parrucci
In leading the way for the creation of a rule-based, multilingual classification system, the IPTC’s EXTRA (EXTraction Rules Apparatus) project is providing a powerful and innovative way for publishers to classify documents using the industry standard IPTC Media Topics taxonomy, as well as tailor rules to their own existing taxonomies. By making these powerful capabilities freely available to the global news publishing community, the EXTRA project catalyzes a variety of innovative outcomes including intelligent aggregation, search and analytics.
In 2016, the IPTC received a €50,000 grant from Google’s Digital News Initiative to create EXTRA , an open source, rules-based, classification system for the annotation of news documents with high-quality subject tags that can be used by publishers to deliver valuable services including, but not limited to, subject related content streams and collections, advertising targeting and content recommendations.
While EXTRA is still in development, attendees of the IPTC Spring Meeting in London were treated to an update and EXTRA demo. The group was shown the rule writer tools and interface and given an example of how to write and test rules. Feedback on these tools is welcomed – the EXTRA project is available via github, including the Extra User Manual, the Extra core code and the Extra API and UI.
A Rules-Based System Improves Tag Consistency Over Other Methods
The fact that EXTRA is rules-based, rather than relying on hand-tagging or statistics-based machine learning systems on the other, is key. EXTRA’s rules-based system allows publishers to improve tag consistency over hand-tagging methods, and provides much more rapid and scalable functionality. EXTRA also allows publishers to adapt their tagging for breaking new and low-frequency topics that cannot be captured by statistical approaches that require numerous annotated results. Users of EXTRA can tweak and customize the extraction rules to suit the needs and patterns of their publication and will be able to either use the IPTC Media Topics as the basic vocabulary or load their own taxonomies into the software. And unlike machine learning, which is a “black box,” EXTRA makes it easier to explain why a given classification was used, and to precisely explain–and correct–mistakes.
A team of IPTC members began by creating a technical requirements document for the project. System requirements included that the tool could be easily configured by given taxonomy, corpora and rules schema, that a comprehensive query language for rules creation was decided upon, that document classification resulted in high precision and recall scores, that the classification could be done in multiple languages, that the system and UI were intuitive and transparent and that everything be available through an open MIT license.
After an extensive search, IPTC hired Infalia in January 2017 to develop the software for EXTRA. Two linguists, one for German and one for English, were hired to create sample rules based on the IPTC Media Topics. The Austrian Press Agency (APA) and Reuters licensed corpora to be used for the EXTRA development process and as examples for users. The working version of EXTRA was completed at the end of June 2017.
Demo of EXTRA: Taxonomy Management Feature
On May 16, 2017 attendees of the IPTC Spring Meeting in London were treated to an EXTRA demo and update about the project. During the demo, the group was shown the rule writer tools and interface and given an example of how to write and test rules.
The group was first shown the taxonomy management feature. For the demo, we pre-loaded the taxonomy management module with the IPTC Media Topics in both English and German. Users are free to use whatever taxonomies they would like. If a taxonomy is selected, one will be able to see the terms in that taxonomy along with their term definitions. The user will also be able to edit and delete terms from that taxonomy.
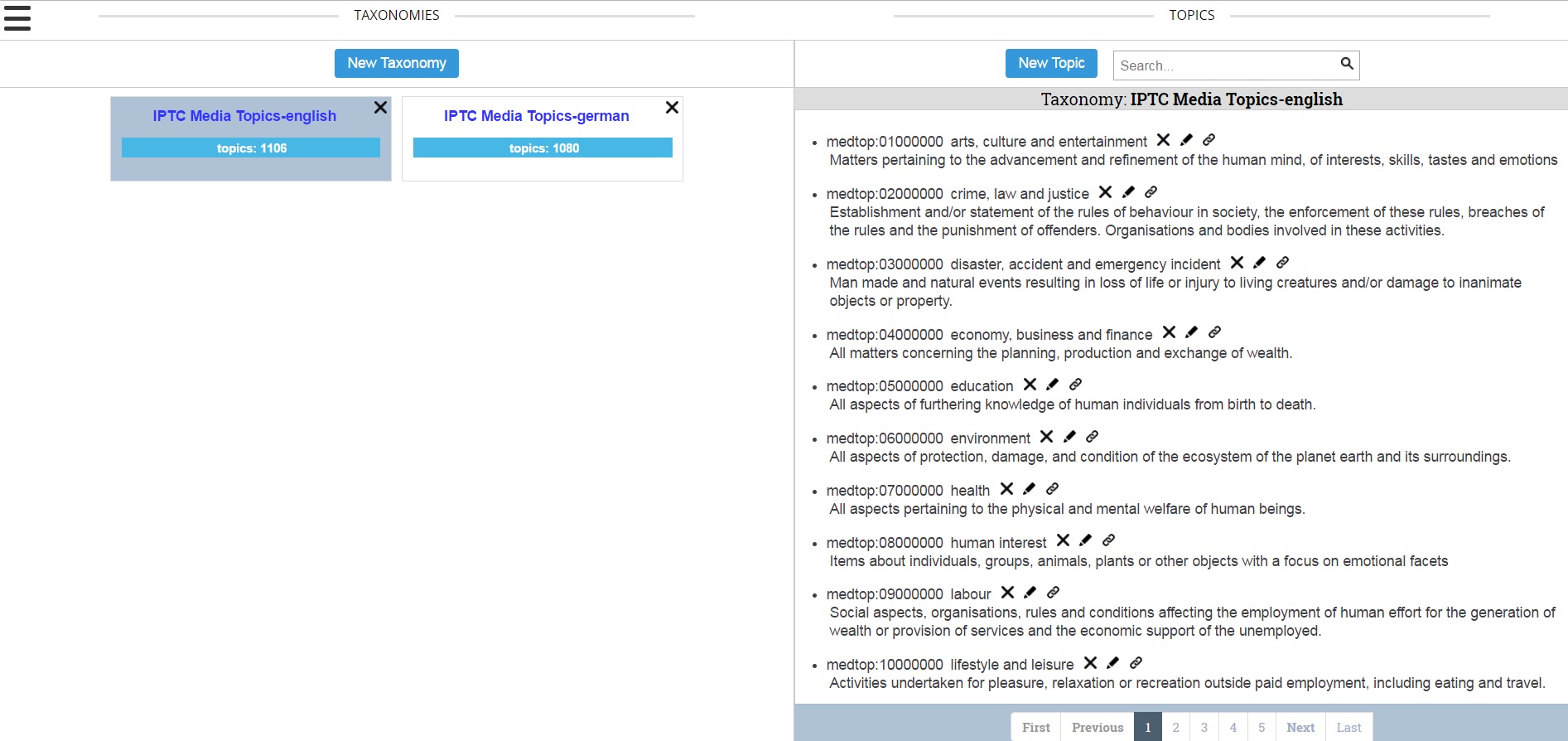
To assist the linguists in writing rules, they used the document search to see what articles within the corpora returned for each Media Topic. This process provided insights into keywords, phrases and article structures that could alert the engine that an article was about a particular topic, and enabled refinement of the rules or the vocabularies. Users can see the IPTC NewsML-G2 XML of a selected document to see what fields they might want to leverage in the rule.
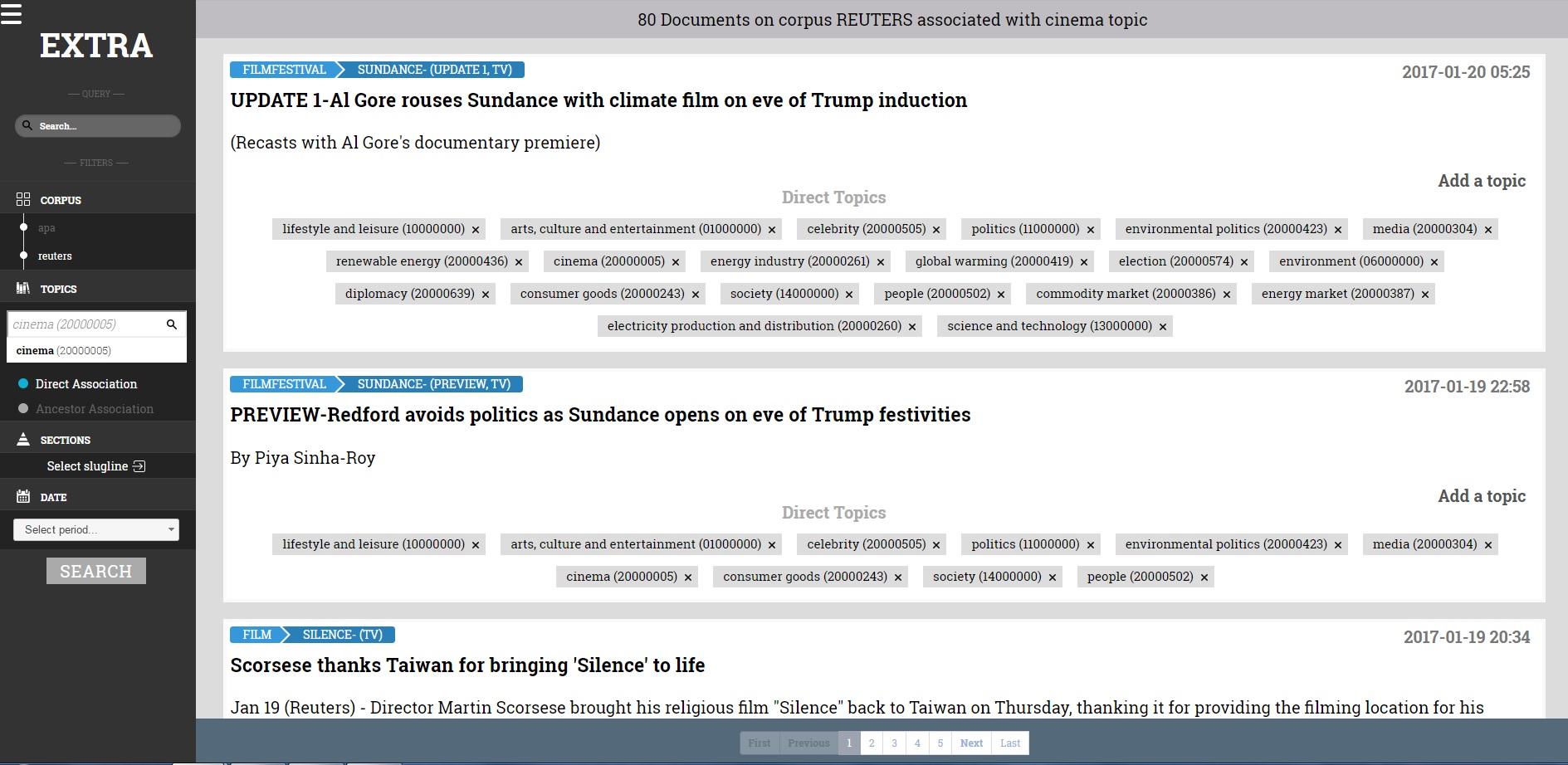
Sample rules
It was then time to show some sample rules. The EXTRA Query Language enables rule writers to create rules that analyze the text of the documents using ElasticSearch operators plus some custom ones. It allows for stemming by language, querying by a whole document or tokenized by a sentence, paragraph or headline. Rules can be written to target the proximity of words or phrases from each other, whether in the document as a whole or a specific field, the frequency of words or phrases individually or how many words from a list appear.
Examples of simple rules:
A rule that requires that “play” and “bass drum guitar piano” appear in proximity of 3 words
(prox/unit=word/distance<=3
(text_content any/stemming “play”)
(text_content any/stemming “bass drum guitar piano”)
)
A rule that requires that “Merkel” and “Obama” appear in the same paragraph
(prox/unit=paragraph/distance=1
(body = “Merkel”)
(body = “Obama”)

After writing a rule, the user has the ability to syntax check their work.
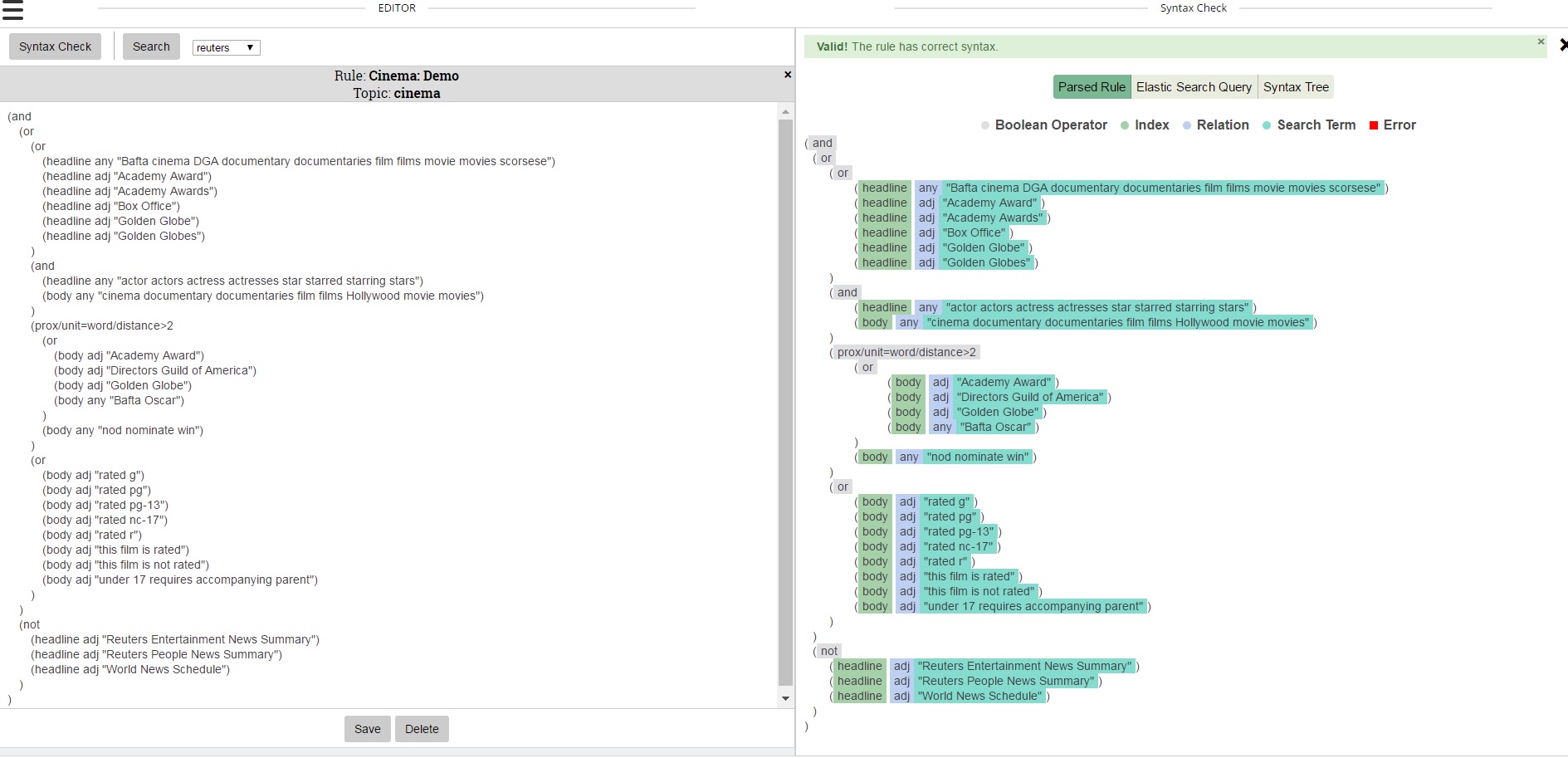
Then, one can run the rule against a corpus to see how many articles match the rule and were tagged with that term (if it is a pre-existing tag), how many many articles only matched the rule and how many articles matched the rule and not the tag. The user is also shown precision and recall scores. All of this data allows the user to tweak their rule until they are happy with the result.
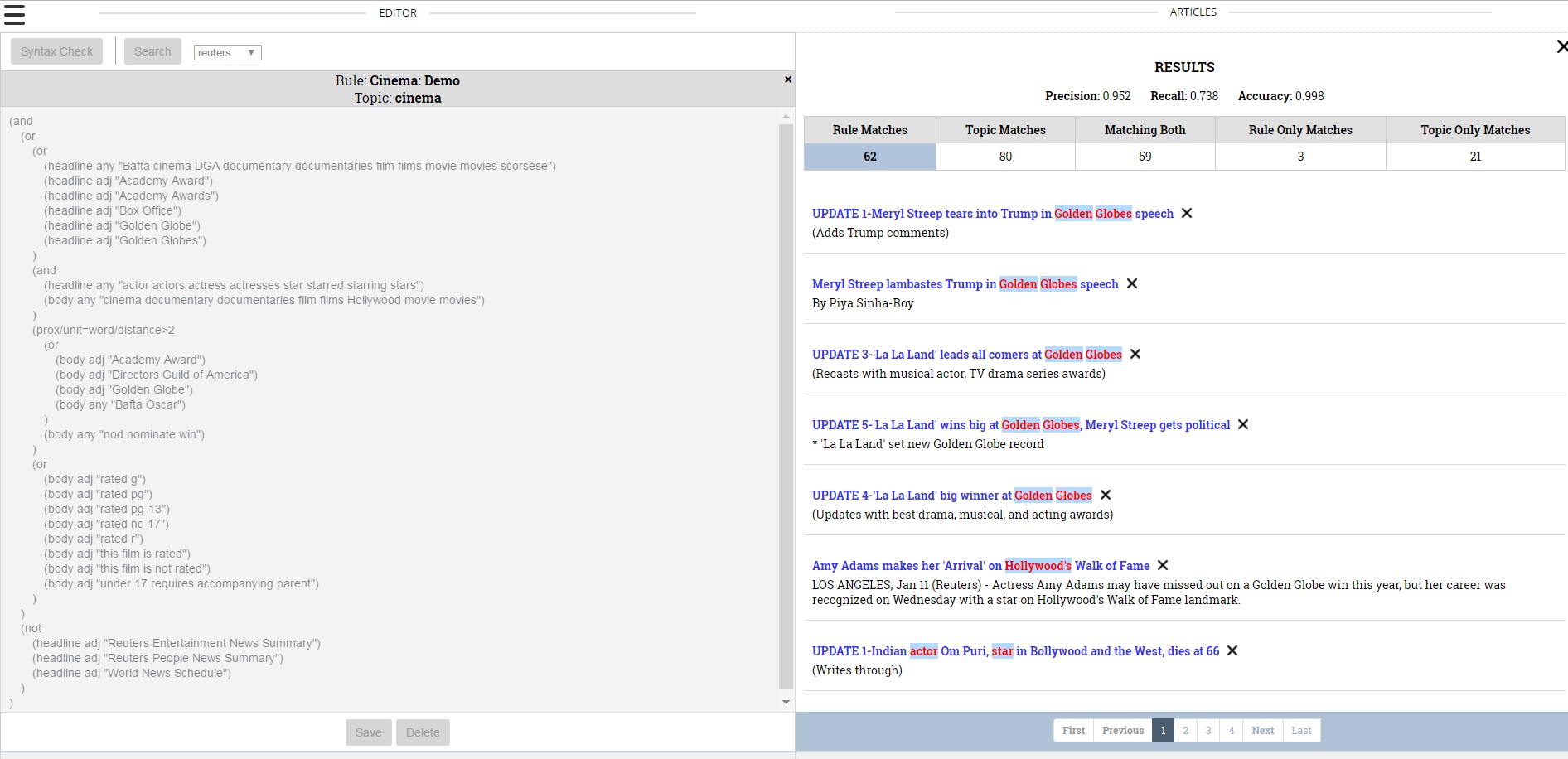
While EXTRA was still in development at the time of the EXTRA demo, the response from the room was positive and members were eager for the finished product.
Feedback on EXTRA:
The EXTRA project is available via github, including the Extra User Manual, the Extra core code and the Extra API and UI.
Please send your feedback about EXTRA to office@iptc.org.
Jennifer Parrucci is a the group lead for IPTC’s News Codes Working Group and a Senior Taxonomist for NYTimes.com.