Categories
Archives
By Jennifer Parrucci
In leading the way for the creation of a rule-based, multilingual classification system, the IPTC’s EXTRA (EXTraction Rules Apparatus) project is providing a powerful and innovative way for publishers to classify documents using the industry standard IPTC Media Topics taxonomy, as well as tailor rules to their own existing taxonomies. By making these powerful capabilities freely available to the global news publishing community, the EXTRA project catalyzes a variety of innovative outcomes including intelligent aggregation, search and analytics.
In 2016, the IPTC received a €50,000 grant from Google’s Digital News Initiative to create EXTRA , an open source, rules-based, classification system for the annotation of news documents with high-quality subject tags that can be used by publishers to deliver valuable services including, but not limited to, subject related content streams and collections, advertising targeting and content recommendations.
While EXTRA is still in development, attendees of the IPTC Spring Meeting in London were treated to an update and EXTRA demo. The group was shown the rule writer tools and interface and given an example of how to write and test rules. Feedback on these tools is welcomed – the EXTRA project is available via github, including the Extra User Manual, the Extra core code and the Extra API and UI.
A Rules-Based System Improves Tag Consistency Over Other Methods
The fact that EXTRA is rules-based, rather than relying on hand-tagging or statistics-based machine learning systems on the other, is key. EXTRA’s rules-based system allows publishers to improve tag consistency over hand-tagging methods, and provides much more rapid and scalable functionality. EXTRA also allows publishers to adapt their tagging for breaking new and low-frequency topics that cannot be captured by statistical approaches that require numerous annotated results. Users of EXTRA can tweak and customize the extraction rules to suit the needs and patterns of their publication and will be able to either use the IPTC Media Topics as the basic vocabulary or load their own taxonomies into the software. And unlike machine learning, which is a “black box,” EXTRA makes it easier to explain why a given classification was used, and to precisely explain–and correct–mistakes.
A team of IPTC members began by creating a technical requirements document for the project. System requirements included that the tool could be easily configured by given taxonomy, corpora and rules schema, that a comprehensive query language for rules creation was decided upon, that document classification resulted in high precision and recall scores, that the classification could be done in multiple languages, that the system and UI were intuitive and transparent and that everything be available through an open MIT license.
After an extensive search, IPTC hired Infalia in January 2017 to develop the software for EXTRA. Two linguists, one for German and one for English, were hired to create sample rules based on the IPTC Media Topics. The Austrian Press Agency (APA) and Reuters licensed corpora to be used for the EXTRA development process and as examples for users. The working version of EXTRA was completed at the end of June 2017.
Demo of EXTRA: Taxonomy Management Feature
On May 16, 2017 attendees of the IPTC Spring Meeting in London were treated to an EXTRA demo and update about the project. During the demo, the group was shown the rule writer tools and interface and given an example of how to write and test rules.
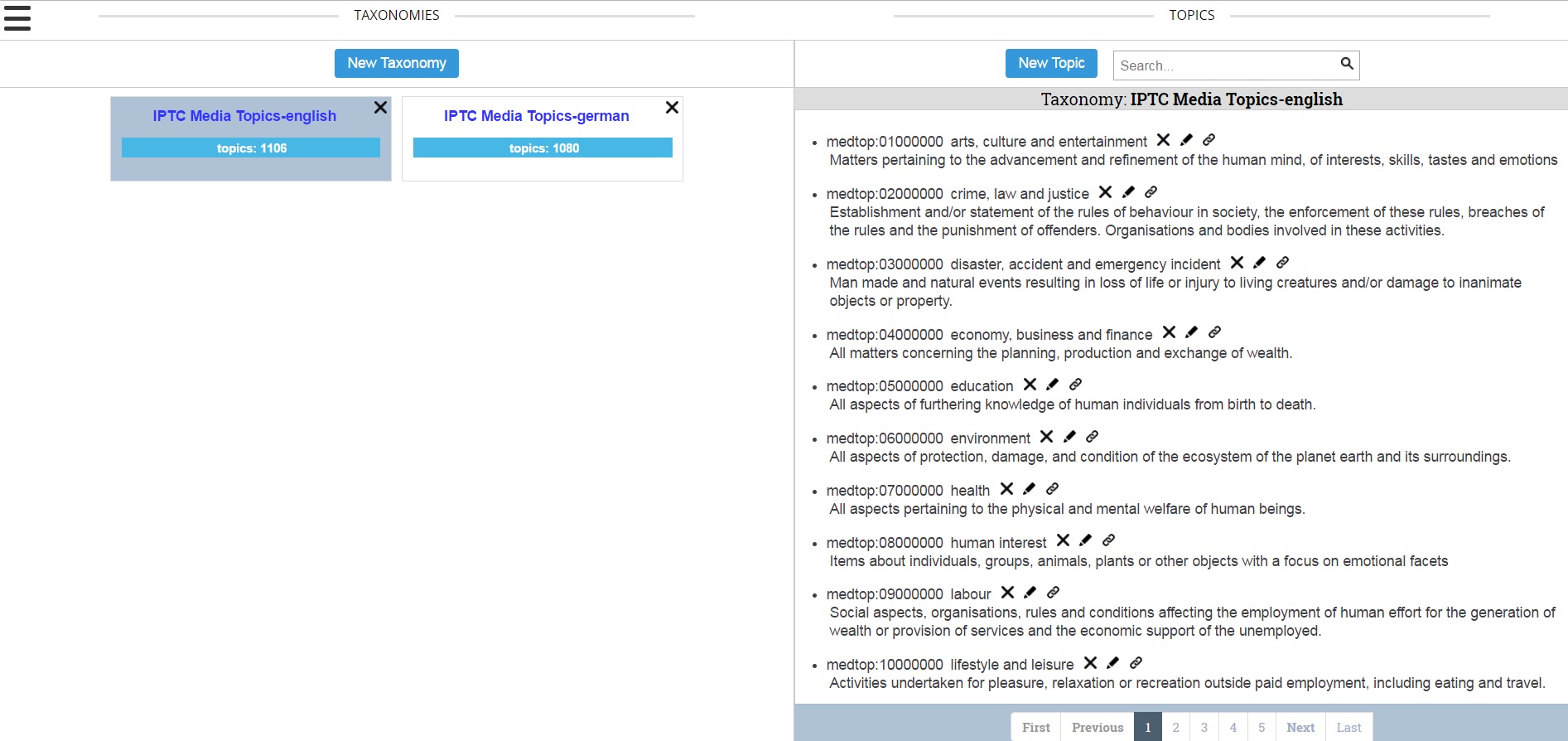
The group was first shown the taxonomy management feature. For the demo, we pre-loaded the taxonomy management module with the IPTC Media Topics in both English and German. Users are free to use whatever taxonomies they would like. If a taxonomy is selected, one will be able to see the terms in that taxonomy along with their term definitions. The user will also be able to edit and delete terms from that taxonomy.
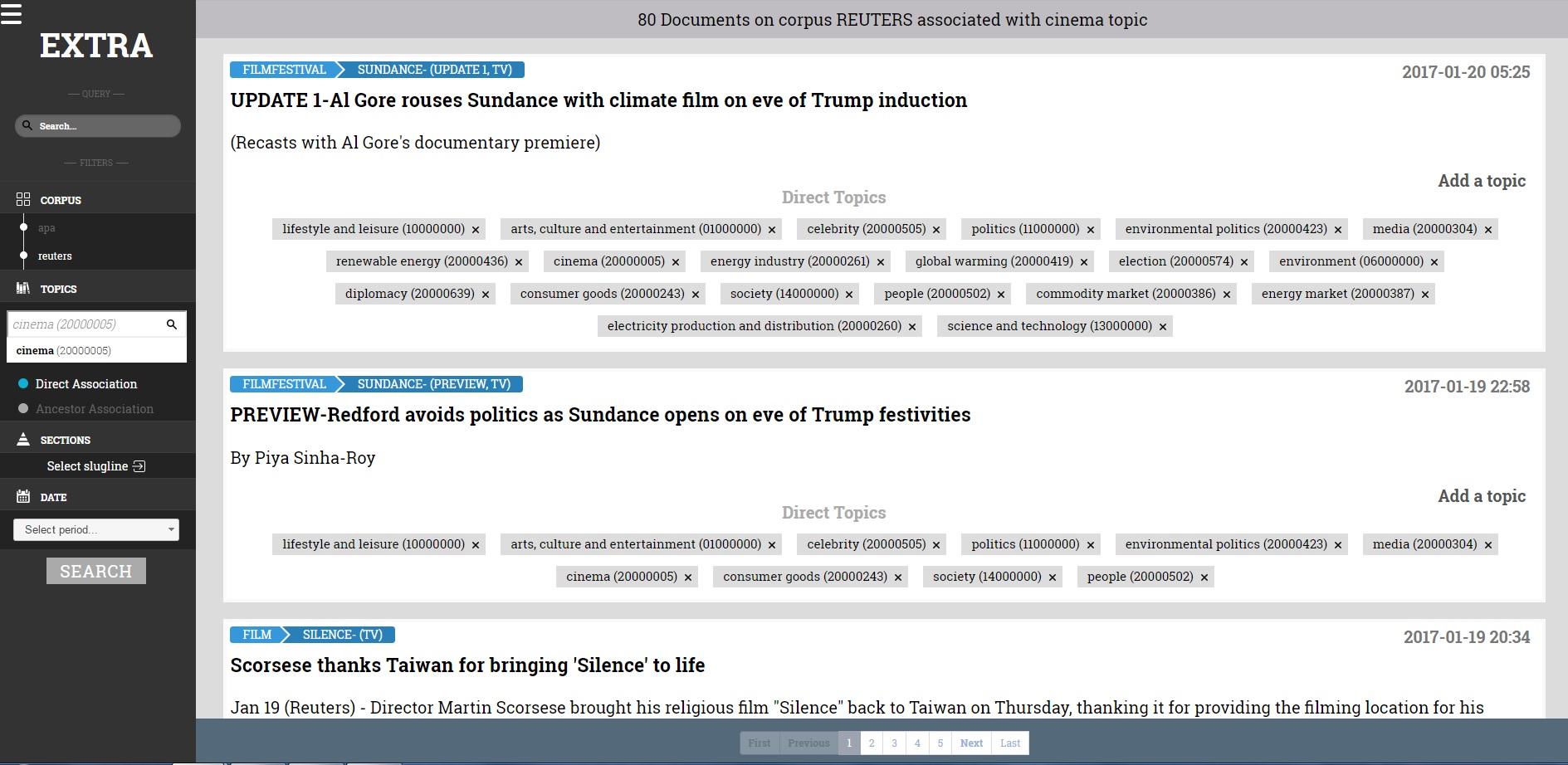
To assist the linguists in writing rules, they used the document search to see what articles within the corpora returned for each Media Topic. This process provided insights into keywords, phrases and article structures that could alert the engine that an article was about a particular topic, and enabled refinement of the rules or the vocabularies. Users can see the IPTC NewsML-G2 XML of a selected document to see what fields they might want to leverage in the rule.
Sample rules
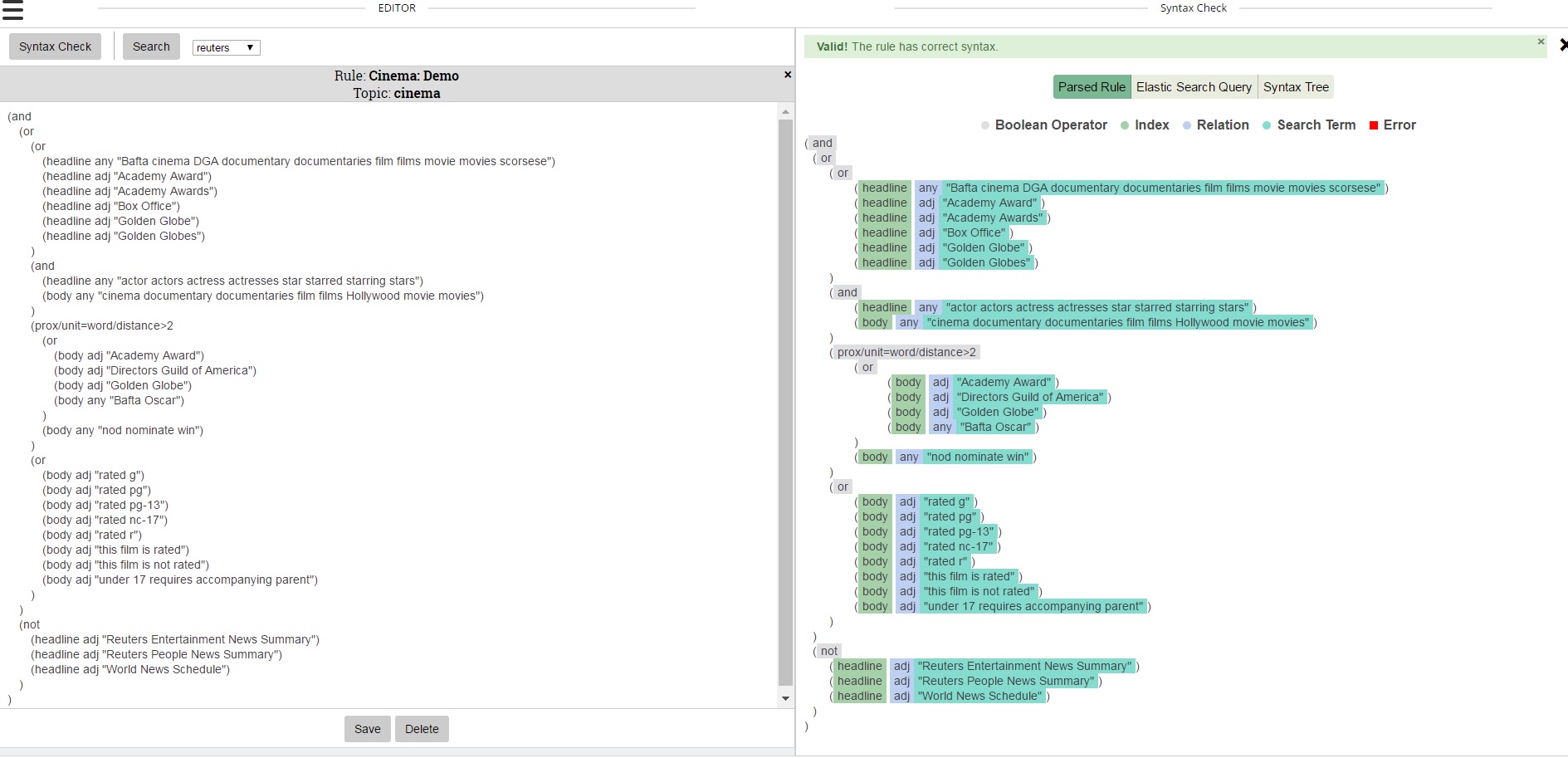
It was then time to show some sample rules. The EXTRA Query Language enables rule writers to create rules that analyze the text of the documents using ElasticSearch operators plus some custom ones. It allows for stemming by language, querying by a whole document or tokenized by a sentence, paragraph or headline. Rules can be written to target the proximity of words or phrases from each other, whether in the document as a whole or a specific field, the frequency of words or phrases individually or how many words from a list appear.
Examples of simple rules:
A rule that requires that “play” and “bass drum guitar piano” appear in proximity of 3 words
(prox/unit=word/distance<=3
(text_content any/stemming “play”)
(text_content any/stemming “bass drum guitar piano”)
)
A rule that requires that “Merkel” and “Obama” appear in the same paragraph
(prox/unit=paragraph/distance=1
(body = “Merkel”)
(body = “Obama”)

After writing a rule, the user has the ability to syntax check their work.
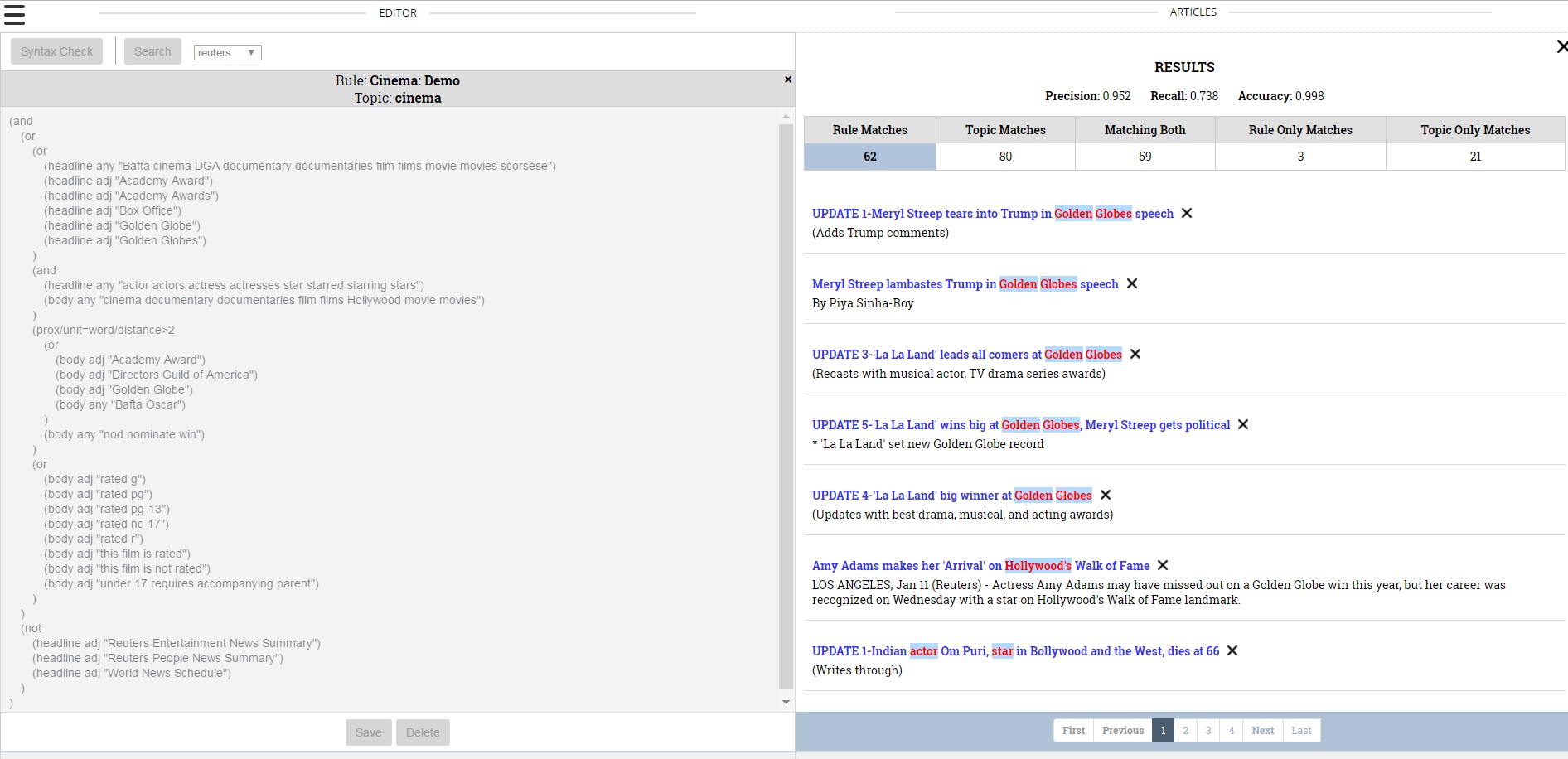
Then, one can run the rule against a corpus to see how many articles match the rule and were tagged with that term (if it is a pre-existing tag), how many many articles only matched the rule and how many articles matched the rule and not the tag. The user is also shown precision and recall scores. All of this data allows the user to tweak their rule until they are happy with the result.
While EXTRA was still in development at the time of the EXTRA demo, the response from the room was positive and members were eager for the finished product.
Feedback on EXTRA:
The EXTRA project is available via github, including the Extra User Manual, the Extra core code and the Extra API and UI.
Please send your feedback about EXTRA to office@iptc.org.
Jennifer Parrucci is a the group lead for IPTC’s News Codes Working Group and a Senior Taxonomist for NYTimes.com.