Categories
Archives

Following the recent announcements of Google’s signalling of generative AI content and Midjourney and Shutterstock the day after, Microsoft has now announced that it will also be signalling the provenance of content created by Microsoft’s generative AI tools such as Bing Image Creator.
Microsoft’s efforts go one step beyond those of Google and Midjourney, because they are adding the image metadata in a way that can be verified using digital certificates. This means that not only is the signal added to the image metadata, but verifiable information is added on who added the metadata and when.
As TechCrunch puts it, “Using cryptographic methods, the capabilities, scheduled to roll out in the coming months, will mark and sign AI-generated content with metadata about the origin of the image or video.”
The system uses the specification created by the Coalition for Content Provenance and Authenticity. a joint project of Project Origin and the Content Authenticity Initiative.
The 1.3 version of the C2PA Specification specifies how a C2PA Action can be used to signal provenance of Generative AI content. This uses the IPTC DigitalSourceType vocabulary – the same vocabulary used by the Google and Midjourney implementations.
This follows IPTC’s guidance on how to use the DigitalSourceType property, published earlier this month.

We have just finished the IPTC Spring Meeting in Tallinn, Estonia. Our first face-to-face IPTC Member Meeting since 2019, those who could attend in person were very happy to be back together, enabling collaboration, knowledge sharing and building bonds across organisations in the media industry.
We were also joined by over 50 online attendees from IPTC member organisations, who braved sometimes difficult timezone differences to view many of the sessions in real time and participate in discussions. Other IPTC members who weren’t able to be there either physically or virtually will be able to watch recordings of the sessions soon.
Themes this time obviously included Generative AI, but also fact-checking and provenance, social media embedding and social stories,
Highlights of the Monday included a special briefing about digital citizenship and digital governance at the e-Estonia Briefing Centre, where members heard from an Estonian government representative who described Estonia’s electronic tax, medicine, administration and even e-voting system, all powered by the cryptographically-protected digital ID card and the X-Road system of interconnecting all of e-Estonia’s services, across both the private and public sector.
Also on the Monday we heard from Gerd Kamp (dpa) who explained how dpa are using Web Components technology to embed social media into their articles in a way that’s much easier for their customers to process. We also heard Working Group presentations and new standard proposals from the NewsML-G2 Working Group and the News in JSON Working Group, whose lead Johan Lindgren (TT) handed over the reins to Ian Young (PA Media / Alamy) who promises to be a fine leader of the group in the future. We say many thanks to Johan for all his contributions to IPTC over the past 25 years!
We also heard from Evi Varsou (ATC) who demonstrated some of ATC’s tools for fighting fake news and misinformation, used by some of the world’s top news organisations.
Day 2 saw Dave Compton (Refinitiv, an LSE Group Company) describe some of their work on handling augmenting news content in real time with analytics information. Then we heard invited speaker Maria Amelie (Factiverse) talk about her troubles with the Norwegian authorities, being deported, and eventually getting Norwegian law changed to support refugees like herself. She now runs the startup Factiverse which is looking at using AI to help promote fact checks as fast as possible, via their site Factisearch (among other projects).
After a discussion on rights and RightsML, we heard from Estonian startup Texta (who provide several tools for media organisations, including an automated comment feed moderator that works in many languages), and German startup Storifyme.com who have created a tool that lets media companies quickly and easily create social posts from news stories – still very relevant even as Google AMP is being wound down.
Tuesday was rounded off by Jennifer Parrucci (The New York Times) presenting the NewsCodes Working Group‘s update, and Paul Kelly (Individual Member) giving an update on the huge amount of work on IPTC Sport Schema from the Sports Content Working Group.
On Wednesday, after an EGM voting on an update to the Articles of Association, we heard from Charlie Halford (BBC) on Project Origin and C2PA, and Sebastian Posth of International Standard Content Code.
We also voted in updates to NewsML-G2 and ninjs, which will be announced here soon.
We’re already looking forward to the Autuymn Meeting, held in October online, and Spring Meeting 2024, hopefully in New York City!

As a follow-up to yesterday’s news on Google using IPTC metadata to mark AI-generated content we are happy to announce that generative AI tools from Midjourney and Shutterstock will both be adopting the same guidelines.
According to a post on Google’s blog, Midjourney and Shutterstock will be using the same mechanism as Google – that is, using the IPTC “Digital Source Type” property to embed a marker that the content was created by a generative AI tool. Google will be detecting this metadata and using it to show a signal in search results that the content has been AI-generated.
A step towards implementing responsible practices for AI
We at IPTC are very excited to see this concrete implementation of our guidance on metadata for synthetic media.
We also see it as a real-world implementation of the guidelines on Responsible Practices for Synthetic Media from the Partnership on AI, and of the AI Ethical Guidelines for the Re-Use and Production of Visual Content from CEPIC, the alliance of European picture agencies. Both of these best practice guidelines emphasise the need for transparency in declaring content that was created using AI tools.
The phrase from the CEPIC transparency guidelines is “Inform users that the media or content is synthetic, through
labelling or cryptographic means, when the media created includes synthetic elements.”
The equivalent recommendation from the Partnership on AI guidelines is called indirect disclosure:
“Indirect disclosure is embedded and includes, but is not limited to, applying cryptographic provenance to synthetic outputs (such as the C2PA standard), applying traceable elements to training data and outputs, synthetic media file metadata, synthetic media pixel composition, and single-frame disclosure statements in videos”
Here is a simple, concrete way of implementing these disclosure / transparency guidelines using existing metadata standards.
Moving towards a provenance ecosystem
IPTC is also involved in efforts to embed transparency and provenance metadata in a way that can be protected using cryptography: C2PA, the Content Authenticity Initiative, and Project Origin.
C2PA provides a way of declaring the same “Digital Source Type” information in a more robust way, that can provide mechanisms to retrieve metadata even after the image was manipulated or after the metadata was stripped from the file.
However implementing C2PA technology is more complicated, and involves obtaining and managing digital certificates, among other things. Also C2PA technology has not been implemented by platforms or search engines on the display side.
In the short term, AI content creation systems can use this simple mechanism to add disclosure information to their content.
The IPTC is happy to help any other parties to implement these metadata signals: please contact IPTC via the Contact Us form.
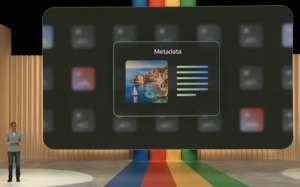
At today’s Google I/O event keynote, Sundar Pichai, CEO of Google, explained how Google will be using embedded IPTC image metadata to signal visual media created by generative AI models.
“Moving forward, we are building our models to include watermarking and other techniques from the start,” Pichai said. “If you look at a synthetic image, it’s impressive how real it looks, so you can imagine how important this is going to be in the future.
“Metadata allows content creators to associate additional context with original files, giving you more information whenever you encounter an image. We’ll ensure every one of our AI-generated images has that metadata.”
The IPTC Photo Metadata section of Google Images’ guidance on metadata has been updated with new guidance on the DigitalSourceType field:
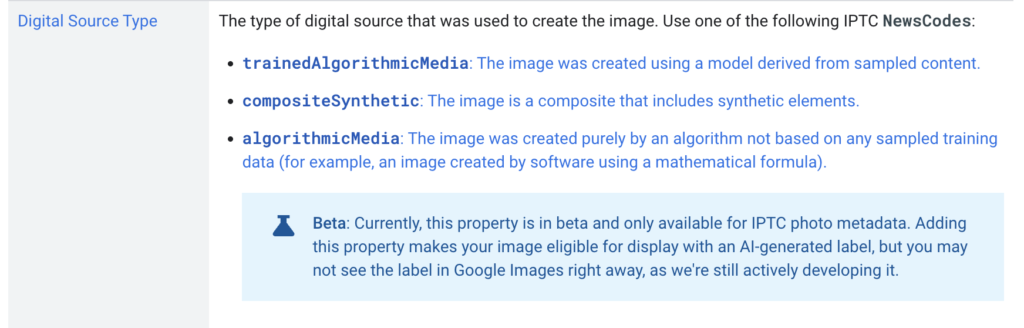
This follows the guidance on IPTC Photo Metadata for Generative AI that was recently published by IPTC.
“AI-Generated” label on Google Images
The above guidance hints at an “AI-generated label” to be used on Google Images in the future. Google recommends that all creators of AI-generated images use the IPTC Digital Source Type property to signal AI-generated content. While Google says that “you may not see the label in Google Images right away”, it appears that it will soon be available in Google Images search results.

The IPTC has updated its Photo Metadata User Guide to include some best practice guidelines for how to use embedded metadata to signal “synthetic media” content that was created by generative AI systems.
After our work in 2022 and the draft vocabulary to support synthetic media, the IPTC NewsCodes Working Group, Video Metadata Working Group and Photo Metadata Working Group worked together with several experts and organisations to come up with a definitive list of “digital source types” that includes various types of machine-generated content, or hybrid human and machine-generated media.
Since publishing the vocabulary, the work has been picked up by the Coalition for Content Provenance and Authenticity (C2PA) via the use of digitalSourceType in Actions and in the IPTC Photo and Video Metadata assertion. But the primary use case is for adding metadata to image and video files
Here is a direct link to the new section on Guidance for using Digital Source Type, including examples for how the various terms can be used to describe media created in different formats – audio, video, images and even text.
IPTC recommends that software creating images using trained AI algorithms uses the “Digital Source Type” value of “trainedAlgorithmicMedia” is added to the XMP data packet in generated image and video files. Alternatively, it may be included in a C2PA manifest as described in the IPTC assertion documentation in the C2PA specification.
The official URL for the full vocabulary is http://cv.iptc.org/newscodes/digitalsourcetype, so the complete URI for the recommended Trained Algorithmic Media term is http://cv.iptc.org/newscodes/digitalsourcetype/trainedAlgorithmicMedia.
Other terms in the vocabulary include:
- Composite with synthetic elements – https://cv.iptc.org/newscodes/digitalsourcetype/compositeSynthetic – covering a composite image that contains some synthetic and some elements captured with a camera;
- Digital Art – https://cv.iptc.org/newscodes/digitalsourcetype/digitalArt – covering art created by a human using digital tools such as a mouse or digital pencil, or computer-generated imagery (CGI) video
- Virtual recording – https://cv.iptc.org/newscodes/digitalsourcetype/virtualRecording – a recording of a virtual event which may or may not contain synthetic elements, such as a Fortnite game or a Zoom meeting
- and several other options – see the full list with examples in the IPTC Photo Metadata User Guide.
Of course, the original digital source type values covering photographs taken on a digital camera or phone (digitalCapture), scan from negative (negativeFilm), and images digitised from print (print) are also valid and may continue to be used. We have, however, retired the generic term “softwareImage” which is now deemed to be too generic. We recommend using one of the newer terms in its place.
If you are considering implementing this guidance in AI image generation software, we would love to hear about it so we can offer advice and tell others. Please contact us using the IPTC contact form.